 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fourier-Constrained Diffusion Bridges for MRI Reconstruction
Aug 04, 2023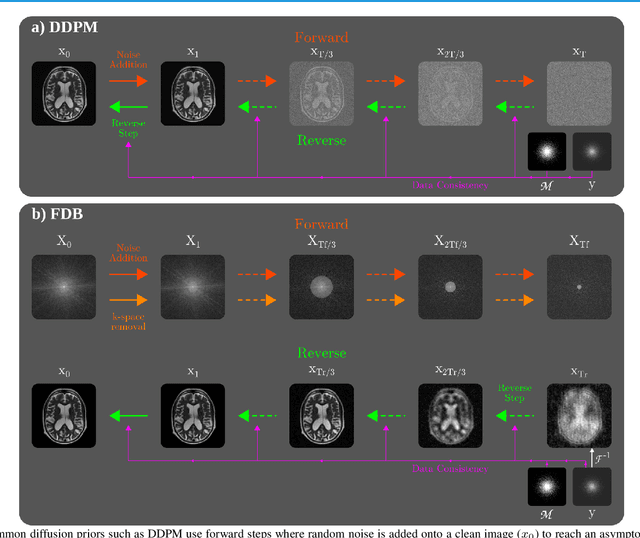
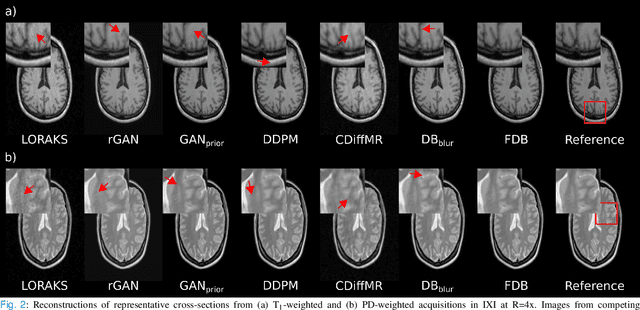
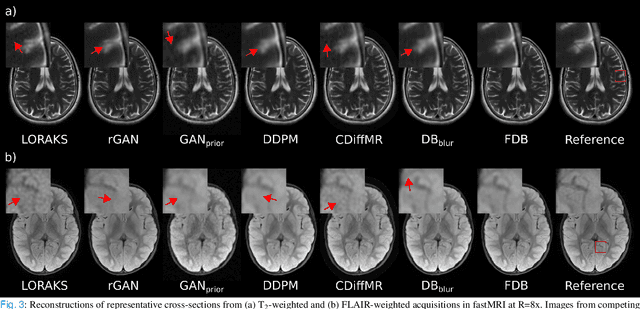
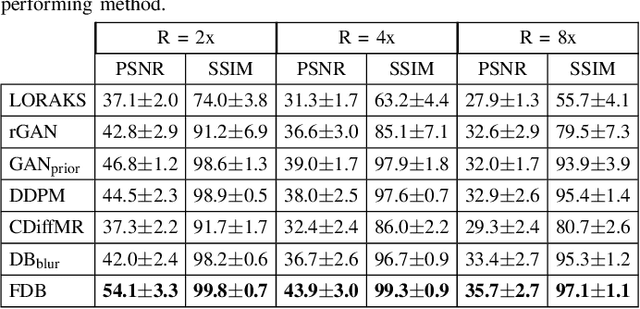
Recent years have witnessed a surge in deep generative models for accelerated MRI reconstruction. Diffusion priors in particular have gained traction with their superior representational fidelity and diversity. Instead of the target transformation from undersampled to fully-sampled data, common diffusion priors are trained to learn a multi-step transformation from Gaussian noise onto fully-sampled data. During inference, data-fidelity projections are injected in between reverse diffusion steps to reach a compromise solution within the span of both the diffusion prior and the imaging operator. Unfortunately, suboptimal solutions can arise as the normality assumption of the diffusion prior causes divergence between learned and target transformations. To address this limitation, here we introduce the first diffusion bridge for accelerated MRI reconstruction. The proposed Fourier-constrained diffusion bridge (FDB) leverages a generalized process to transform between undersampled and fully-sampled data via random noise addition and random frequency removal as degradation operators. Unlike common diffusion priors that use an asymptotic endpoint based on Gaussian noise, FDB captures a transformation between finite endpoints where the initial endpoint is based on moderate degradation of fully-sampled data. Demonstrations on brain MRI indicate that FDB outperforms state-of-the-art reconstruction methods including conventional diffusion priors.
Comments on "Deep Neural Networks with Random Gaussian Weights: A Universal Classification Strategy?"
Jan 08, 2019In a recently published paper [1], it is shown that deep neural networks (DNNs) with random Gaussian weights preserve the metric structure of the data, with the property that the distance shrinks more when the angle between the two data points is smaller. We agree that the random projection setup considered in [1] preserves distances with a high probability. But as far as we are concerned, the relation between the angle of the data points and the output distances is quite the opposite, i.e., smaller angles result in a weaker distance shrinkage. This leads us to conclude that Theorem 3 and Figure 5 in [1] are not accurate. Hence the usage of random Gaussian weights in DNNs cannot provide an ability of universal classification or treating in-class and out-of-class data separately. Consequently, the behavior of networks consisting of random Gaussian weights only is not useful to explain how DNNs achieve state-of-art results in a large variety of problems.