 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMap-Aware Human Pose Prediction for Robot Follow-Ahead
Mar 20, 2024In the robot follow-ahead task, a mobile robot is tasked to maintain its relative position in front of a moving human actor while keeping the actor in sight. To accomplish this task, it is important that the robot understand the full 3D pose of the human (since the head orientation can be different than the torso) and predict future human poses so as to plan accordingly. This prediction task is especially tricky in a complex environment with junctions and multiple corridors. In this work, we address the problem of forecasting the full 3D trajectory of a human in such environments. Our main insight is to show that one can first predict the 2D trajectory and then estimate the full 3D trajectory by conditioning the estimator on the predicted 2D trajectory. With this approach, we achieve results comparable or better than the state-of-the-art methods three times faster. As part of our contribution, we present a new dataset where, in contrast to existing datasets, the human motion is in a much larger area than a single room. We also present a complete robot system that integrates our human pose forecasting network on the mobile robot to enable real-time robot follow-ahead and present results from real-world experiments in multiple buildings on campus. Our project page, including supplementary material and videos, can be found at: https://qingyuan-jiang.github.io/iros2024_poseForecasting/
Federated Learning of Generative Image Priors for MRI Reconstruction
Feb 08, 2022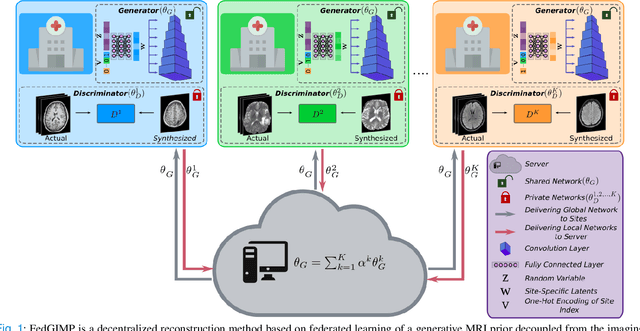
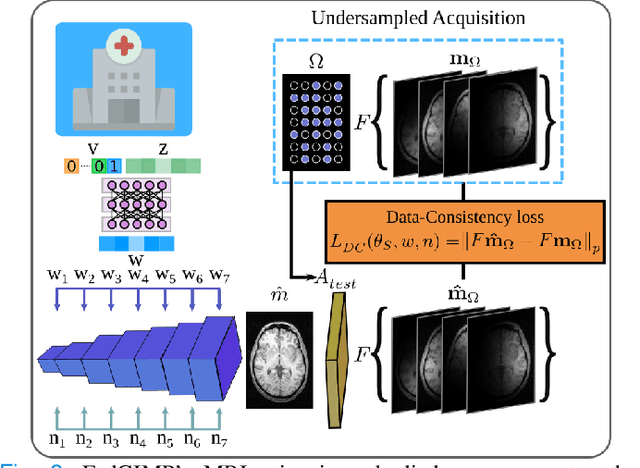
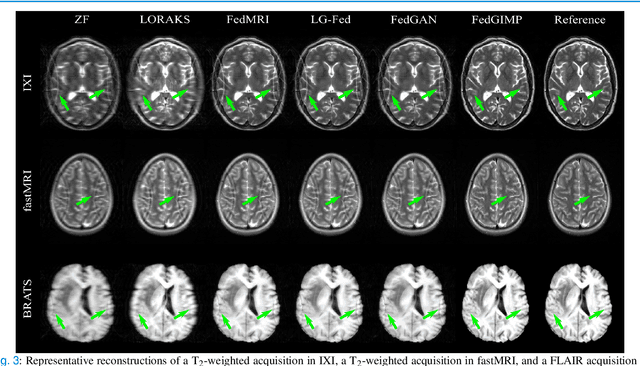
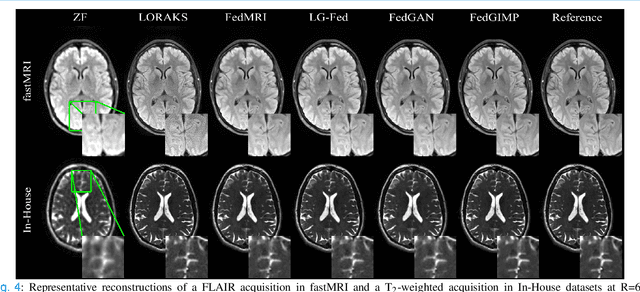
Multi-institutional efforts can facilitate training of deep MRI reconstruction models, albeit privacy risks arise during cross-site sharing of imaging data. Federated learning (FL) has recently been introduced to address privacy concerns by enabling distributed training without transfer of imaging data. Existing FL methods for MRI reconstruction employ conditional models to map from undersampled to fully-sampled acquisitions via explicit knowledge of the imaging operator. Since conditional models generalize poorly across different acceleration rates or sampling densities, imaging operators must be fixed between training and testing, and they are typically matched across sites. To improve generalization and flexibility in multi-institutional collaborations, here we introduce a novel method for MRI reconstruction based on Federated learning of Generative IMage Priors (FedGIMP). FedGIMP leverages a two-stage approach: cross-site learning of a generative MRI prior, and subject-specific injection of the imaging operator. The global MRI prior is learned via an unconditional adversarial model that synthesizes high-quality MR images based on latent variables. Specificity in the prior is preserved via a mapper subnetwork that produces site-specific latents. During inference, the prior is combined with subject-specific imaging operators to enable reconstruction, and further adapted to individual test samples by minimizing data-consistency loss. Comprehensive experiments on multi-institutional datasets clearly demonstrate enhanced generalization performance of FedGIMP against site-specific and federated methods based on conditional models, as well as traditional reconstruction methods.