 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRebalanced Multimodal Learning with Data-aware Unimodal Sampling
Mar 05, 2025To address the modality learning degeneration caused by modality imbalance, existing multimodal learning~(MML) approaches primarily attempt to balance the optimization process of each modality from the perspective of model learning. However, almost all existing methods ignore the modality imbalance caused by unimodal data sampling, i.e., equal unimodal data sampling often results in discrepancies in informational content, leading to modality imbalance. Therefore, in this paper, we propose a novel MML approach called \underline{D}ata-aware \underline{U}nimodal \underline{S}ampling~(\method), which aims to dynamically alleviate the modality imbalance caused by sampling. Specifically, we first propose a novel cumulative modality discrepancy to monitor the multimodal learning process. Based on the learning status, we propose a heuristic and a reinforcement learning~(RL)-based data-aware unimodal sampling approaches to adaptively determine the quantity of sampled data at each iteration, thus alleviating the modality imbalance from the perspective of sampling. Meanwhile, our method can be seamlessly incorporated into almost all existing multimodal learning approaches as a plugin. Experiments demonstrate that \method~can achieve the best performance by comparing with diverse state-of-the-art~(SOTA) baselines.
The Solution for Temporal Action Localisation Task of Perception Test Challenge 2024
Oct 08, 2024

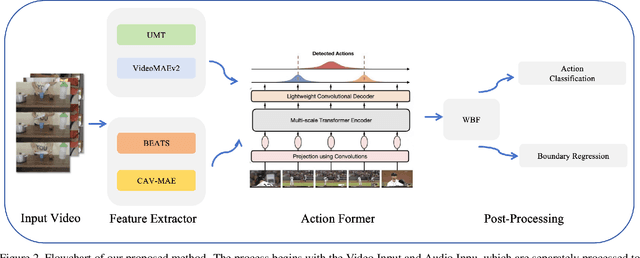

This report presents our method for Temporal Action Localisation (TAL), which focuses on identifying and classifying actions within specific time intervals throughout a video sequence. We employ a data augmentation technique by expanding the training dataset using overlapping labels from the Something-SomethingV2 dataset, enhancing the model's ability to generalize across various action classes. For feature extraction, we utilize state-of-the-art models, including UMT, VideoMAEv2 for video features, and BEATs and CAV-MAE for audio features. Our approach involves training both multimodal (video and audio) and unimodal (video only) models, followed by combining their predictions using the Weighted Box Fusion (WBF) method. This fusion strategy ensures robust action localisation. our overall approach achieves a score of 0.5498, securing first place in the competition.
Map-Aware Human Pose Prediction for Robot Follow-Ahead
Mar 20, 2024In the robot follow-ahead task, a mobile robot is tasked to maintain its relative position in front of a moving human actor while keeping the actor in sight. To accomplish this task, it is important that the robot understand the full 3D pose of the human (since the head orientation can be different than the torso) and predict future human poses so as to plan accordingly. This prediction task is especially tricky in a complex environment with junctions and multiple corridors. In this work, we address the problem of forecasting the full 3D trajectory of a human in such environments. Our main insight is to show that one can first predict the 2D trajectory and then estimate the full 3D trajectory by conditioning the estimator on the predicted 2D trajectory. With this approach, we achieve results comparable or better than the state-of-the-art methods three times faster. As part of our contribution, we present a new dataset where, in contrast to existing datasets, the human motion is in a much larger area than a single room. We also present a complete robot system that integrates our human pose forecasting network on the mobile robot to enable real-time robot follow-ahead and present results from real-world experiments in multiple buildings on campus. Our project page, including supplementary material and videos, can be found at: https://qingyuan-jiang.github.io/iros2024_poseForecasting/
Onboard View Planning of a Flying Camera for High Fidelity 3D Reconstruction of a Moving Actor
Jul 31, 2023
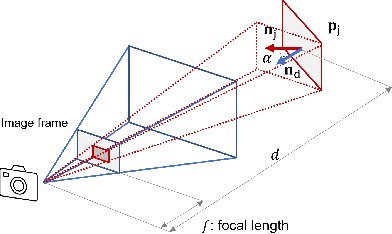
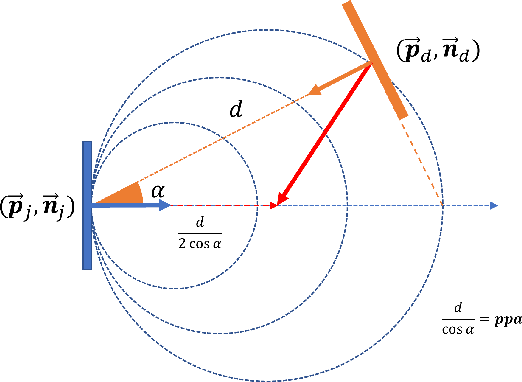
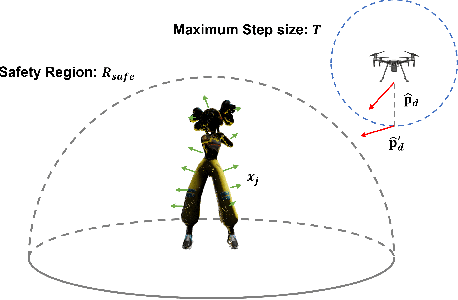
Capturing and reconstructing a human actor's motion is important for filmmaking and gaming. Currently, motion capture systems with static cameras are used for pixel-level high-fidelity reconstructions. Such setups are costly, require installation and calibration and, more importantly, confine the user to a predetermined area. In this work, we present a drone-based motion capture system that can alleviate these limitations. We present a complete system implementation and study view planning which is critical for achieving high-quality reconstructions. The main challenge for view planning for a drone-based capture system is that it needs to be performed during motion capture. To address this challenge, we introduce simple geometric primitives and show that they can be used for view planning. Specifically, we introduce Pixel-Per-Area (PPA) as a reconstruction quality proxy and plan views by maximizing the PPA of the faces of a simple geometric shape representing the actor. Through experiments in simulation, we show that PPA is highly correlated with reconstruction quality. We also conduct real-world experiments showing that our system can produce dynamic 3D reconstructions of good quality. We share our code for the simulation experiments in the link: https://github.com/Qingyuan-Jiang/view_planning_3dhuman