 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Solution for Temporal Action Localisation Task of Perception Test Challenge 2024
Oct 08, 2024

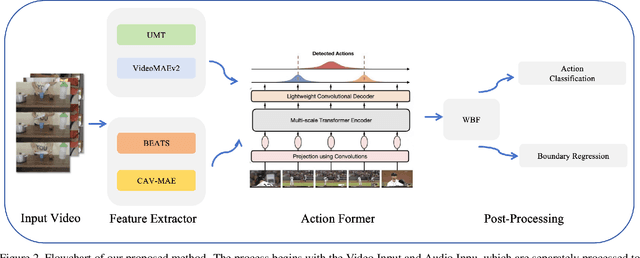

This report presents our method for Temporal Action Localisation (TAL), which focuses on identifying and classifying actions within specific time intervals throughout a video sequence. We employ a data augmentation technique by expanding the training dataset using overlapping labels from the Something-SomethingV2 dataset, enhancing the model's ability to generalize across various action classes. For feature extraction, we utilize state-of-the-art models, including UMT, VideoMAEv2 for video features, and BEATs and CAV-MAE for audio features. Our approach involves training both multimodal (video and audio) and unimodal (video only) models, followed by combining their predictions using the Weighted Box Fusion (WBF) method. This fusion strategy ensures robust action localisation. our overall approach achieves a score of 0.5498, securing first place in the competition.