 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMambaTrack3D: A State Space Model Framework for LiDAR-Based Object Tracking under High Temporal Variation
Nov 19, 2025Dynamic outdoor environments with high temporal variation (HTV) pose significant challenges for 3D single object tracking in LiDAR point clouds. Existing memory-based trackers often suffer from quadratic computational complexity, temporal redundancy, and insufficient exploitation of geometric priors. To address these issues, we propose MambaTrack3D, a novel HTV-oriented tracking framework built upon the state space model Mamba. Specifically, we design a Mamba-based Inter-frame Propagation (MIP) module that replaces conventional single-frame feature extraction with efficient inter-frame propagation, achieving near-linear complexity while explicitly modeling spatial relations across historical frames. Furthermore, a Grouped Feature Enhancement Module (GFEM) is introduced to separate foreground and background semantics at the channel level, thereby mitigating temporal redundancy in the memory bank. Extensive experiments on KITTI-HTV and nuScenes-HTV benchmarks demonstrate that MambaTrack3D consistently outperforms both HTV-oriented and normal-scenario trackers, achieving improvements of up to 6.5 success and 9.5 precision over HVTrack under moderate temporal gaps. On the standard KITTI dataset, MambaTrack3D remains highly competitive with state-of-the-art normal-scenario trackers, confirming its strong generalization ability. Overall, MambaTrack3D achieves a superior accuracy-efficiency trade-off, delivering robust performance across both specialized HTV and conventional tracking scenarios.
Robust Single Object Tracking in LiDAR Point Clouds under Adverse Weather Conditions
Jan 13, 2025



3D single object tracking (3DSOT) in LiDAR point clouds is a critical task for outdoor perception, enabling real-time perception of object location, orientation, and motion. Despite the impressive performance of current 3DSOT methods, evaluating them on clean datasets inadequately reflects their comprehensive performance, as the adverse weather conditions in real-world surroundings has not been considered. One of the main obstacles is the lack of adverse weather benchmarks for the evaluation of 3DSOT. To this end, this work proposes a challenging benchmark for LiDAR-based 3DSOT in adverse weather, which comprises two synthetic datasets (KITTI-A and nuScenes-A) and one real-world dataset (CADC-SOT) spanning three weather types: rain, fog, and snow. Based on this benchmark, five representative 3D trackers from different tracking frameworks conducted robustness evaluation, resulting in significant performance degradations. This prompts the question: What are the factors that cause current advanced methods to fail on such adverse weather samples? Consequently, we explore the impacts of adverse weather and answer the above question from three perspectives: 1) target distance; 2) template shape corruption; and 3) target shape corruption. Finally, based on domain randomization and contrastive learning, we designed a dual-branch tracking framework for adverse weather, named DRCT, achieving excellent performance in benchmarks.
Evaluating the Robustness of LiDAR Point Cloud Tracking Against Adversarial Attack
Oct 28, 2024In this study, we delve into the robustness of neural network-based LiDAR point cloud tracking models under adversarial attacks, a critical aspect often overlooked in favor of performance enhancement. These models, despite incorporating advanced architectures like Transformer or Bird's Eye View (BEV), tend to neglect robustness in the face of challenges such as adversarial attacks, domain shifts, or data corruption. We instead focus on the robustness of the tracking models under the threat of adversarial attacks. We begin by establishing a unified framework for conducting adversarial attacks within the context of 3D object tracking, which allows us to thoroughly investigate both white-box and black-box attack strategies. For white-box attacks, we tailor specific loss functions to accommodate various tracking paradigms and extend existing methods such as FGSM, C\&W, and PGD to the point cloud domain. In addressing black-box attack scenarios, we introduce a novel transfer-based approach, the Target-aware Perturbation Generation (TAPG) algorithm, with the dual objectives of achieving high attack performance and maintaining low perceptibility. This method employs a heuristic strategy to enforce sparse attack constraints and utilizes random sub-vector factorization to bolster transferability. Our experimental findings reveal a significant vulnerability in advanced tracking methods when subjected to both black-box and white-box attacks, underscoring the necessity for incorporating robustness against adversarial attacks into the design of LiDAR point cloud tracking models. Notably, compared to existing methods, the TAPG also strikes an optimal balance between the effectiveness of the attack and the concealment of the perturbations.
The Solution for Temporal Action Localisation Task of Perception Test Challenge 2024
Oct 08, 2024

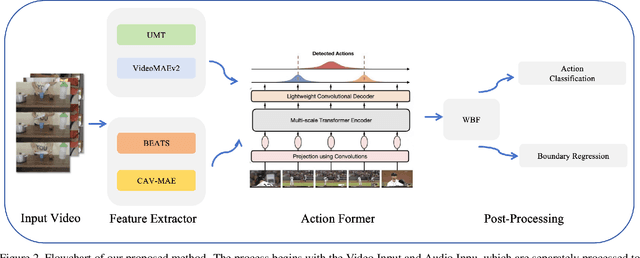

This report presents our method for Temporal Action Localisation (TAL), which focuses on identifying and classifying actions within specific time intervals throughout a video sequence. We employ a data augmentation technique by expanding the training dataset using overlapping labels from the Something-SomethingV2 dataset, enhancing the model's ability to generalize across various action classes. For feature extraction, we utilize state-of-the-art models, including UMT, VideoMAEv2 for video features, and BEATs and CAV-MAE for audio features. Our approach involves training both multimodal (video and audio) and unimodal (video only) models, followed by combining their predictions using the Weighted Box Fusion (WBF) method. This fusion strategy ensures robust action localisation. our overall approach achieves a score of 0.5498, securing first place in the competition.
Small Object Tracking in LiDAR Point Cloud: Learning the Target-awareness Prototype and Fine-grained Search Region
Jan 24, 2024



Single Object Tracking in LiDAR point cloud is one of the most essential parts of environmental perception, in which small objects are inevitable in real-world scenarios and will bring a significant barrier to the accurate location. However, the existing methods concentrate more on exploring universal architectures for common categories and overlook the challenges that small objects have long been thorny due to the relative deficiency of foreground points and a low tolerance for disturbances. To this end, we propose a Siamese network-based method for small object tracking in the LiDAR point cloud, which is composed of the target-awareness prototype mining (TAPM) module and the regional grid subdivision (RGS) module. The TAPM module adopts the reconstruction mechanism of the masked decoder to learn the prototype in the feature space, aiming to highlight the presence of foreground points that will facilitate the subsequent location of small objects. Through the above prototype is capable of accentuating the small object of interest, the positioning deviation in feature maps still leads to high tracking errors. To alleviate this issue, the RGS module is proposed to recover the fine-grained features of the search region based on ViT and pixel shuffle layers. In addition, apart from the normal settings, we elaborately design a scaling experiment to evaluate the robustness of the different trackers on small objects. Extensive experiments on KITTI and nuScenes demonstrate that our method can effectively improve the tracking performance of small targets without affecting normal-sized objects.
OST: Efficient One-stream Network for 3D Single Object Tracking in Point Clouds
Oct 16, 2022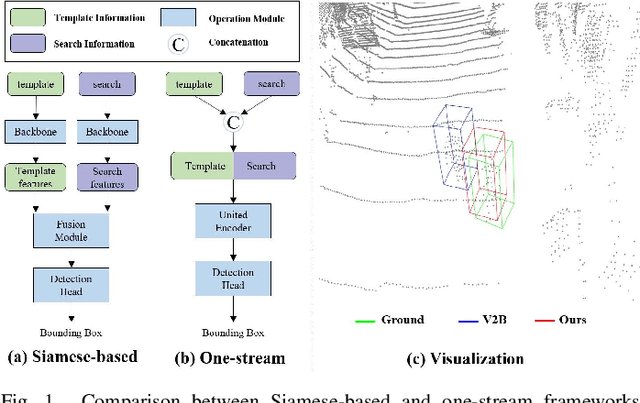
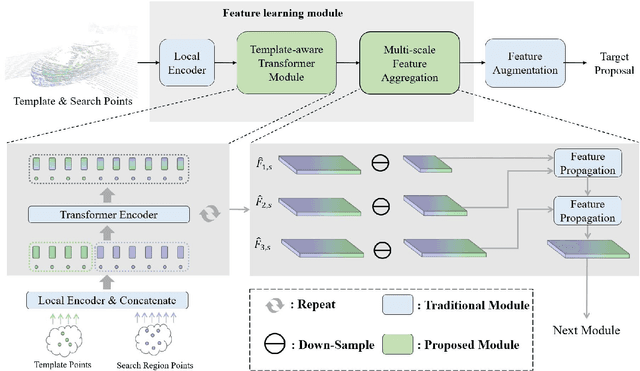
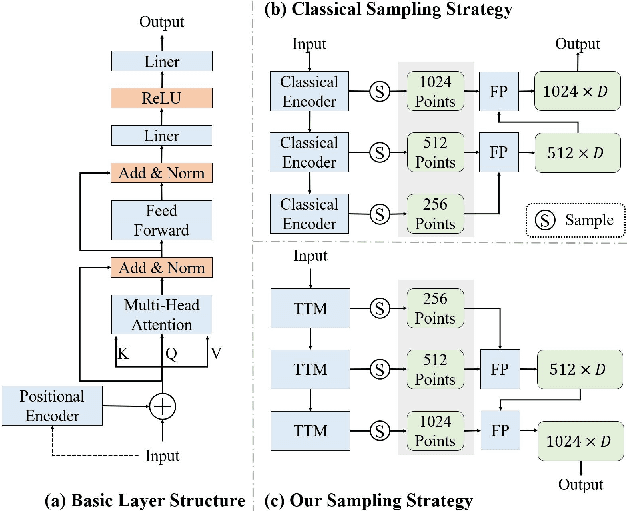
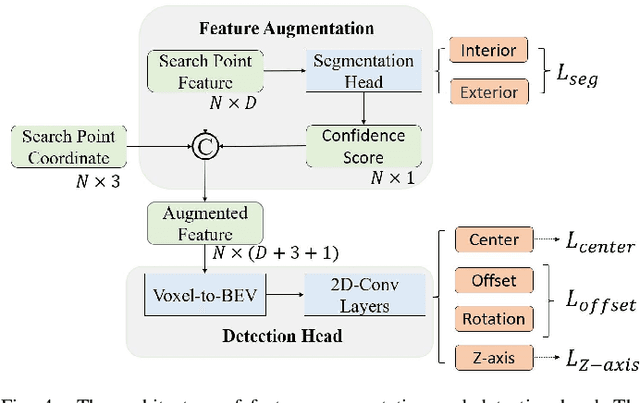
Although recent Siamese network-based trackers have achieved impressive perceptual accuracy for single object tracking in LiDAR point clouds, they advance with some heavy correlation operations on relation modeling and overlook the inherent merit of arbitrariness compared to multiple object tracking. In this work, we propose a radically novel one-stream network with the strength of the Transformer encoding, which avoids the correlation operations occurring in previous Siamese network, thus considerably reducing the computational effort. In particular, the proposed method mainly consists of a Template-aware Transformer Module (TTM) and a Multi-scale Feature Aggregation (MFA) module capable of fusing spatial and semantic information. The TTM stitches the specified template and the search region together and leverages an attention mechanism to establish the information flow, breaking the previous pattern of independent \textit{extraction-and-correlation}. As a result, this module makes it possible to directly generate template-aware features that are suitable for the arbitrary and continuously changing nature of the target, enabling the model to deal with unseen categories. In addition, the MFA is proposed to make spatial and semantic information complementary to each other, which is characterized by reverse directional feature propagation that aggregates information from shallow to deep layers. Extensive experiments on KITTI and nuScenes demonstrate that our method has achieved considerable performance not only for class-specific tracking but also for class-agnostic tracking with less computation and higher efficiency.