 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOST: Efficient One-stream Network for 3D Single Object Tracking in Point Clouds
Paper and Code
Oct 16, 2022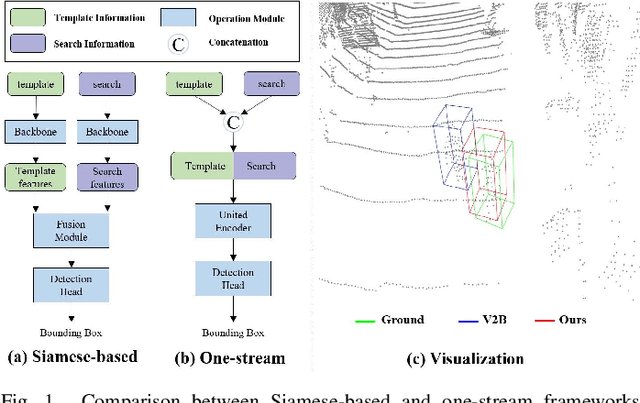
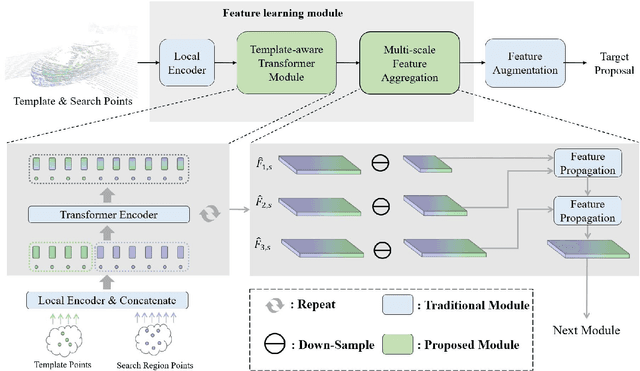
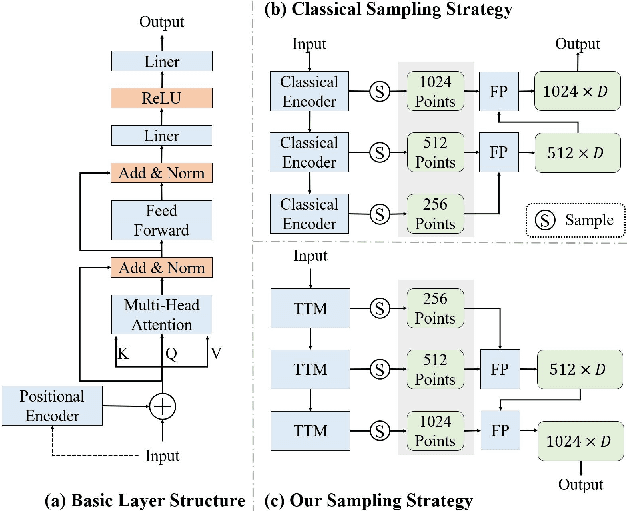
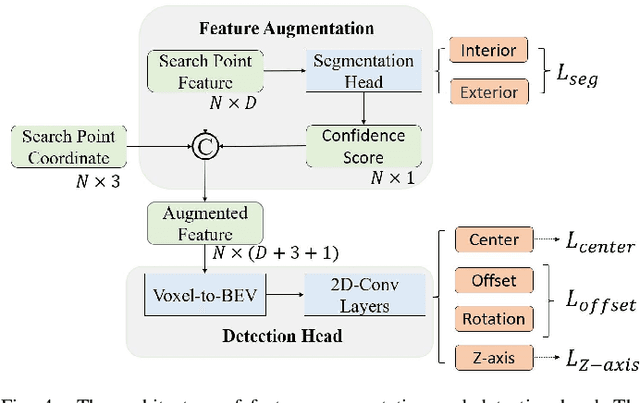
Although recent Siamese network-based trackers have achieved impressive perceptual accuracy for single object tracking in LiDAR point clouds, they advance with some heavy correlation operations on relation modeling and overlook the inherent merit of arbitrariness compared to multiple object tracking. In this work, we propose a radically novel one-stream network with the strength of the Transformer encoding, which avoids the correlation operations occurring in previous Siamese network, thus considerably reducing the computational effort. In particular, the proposed method mainly consists of a Template-aware Transformer Module (TTM) and a Multi-scale Feature Aggregation (MFA) module capable of fusing spatial and semantic information. The TTM stitches the specified template and the search region together and leverages an attention mechanism to establish the information flow, breaking the previous pattern of independent \textit{extraction-and-correlation}. As a result, this module makes it possible to directly generate template-aware features that are suitable for the arbitrary and continuously changing nature of the target, enabling the model to deal with unseen categories. In addition, the MFA is proposed to make spatial and semantic information complementary to each other, which is characterized by reverse directional feature propagation that aggregates information from shallow to deep layers. Extensive experiments on KITTI and nuScenes demonstrate that our method has achieved considerable performance not only for class-specific tracking but also for class-agnostic tracking with less computation and higher efficiency.