 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSV-GS: Sparse View 4D Reconstruction with Skeleton-Driven Gaussian Splatting
Jan 01, 2026Reconstructing a dynamic target moving over a large area is challenging. Standard approaches for dynamic object reconstruction require dense coverage in both the viewing space and the temporal dimension, typically relying on multi-view videos captured at each time step. However, such setups are only possible in constrained environments. In real-world scenarios, observations are often sparse over time and captured sparsely from diverse viewpoints (e.g., from security cameras), making dynamic reconstruction highly ill-posed. We present SV-GS, a framework that simultaneously estimates a deformation model and the object's motion over time under sparse observations. To initialize SV-GS, we leverage a rough skeleton graph and an initial static reconstruction as inputs to guide motion estimation. (Later, we show that this input requirement can be relaxed.) Our method optimizes a skeleton-driven deformation field composed of a coarse skeleton joint pose estimator and a module for fine-grained deformations. By making only the joint pose estimator time-dependent, our model enables smooth motion interpolation while preserving learned geometric details. Experiments on synthetic datasets show that our method outperforms existing approaches under sparse observations by up to 34% in PSNR, and achieves comparable performance to dense monocular video methods on real-world datasets despite using significantly fewer frames. Moreover, we demonstrate that the input initial static reconstruction can be replaced by a diffusion-based generative prior, making our method more practical for real-world scenarios.
Map-Aware Human Pose Prediction for Robot Follow-Ahead
Mar 20, 2024In the robot follow-ahead task, a mobile robot is tasked to maintain its relative position in front of a moving human actor while keeping the actor in sight. To accomplish this task, it is important that the robot understand the full 3D pose of the human (since the head orientation can be different than the torso) and predict future human poses so as to plan accordingly. This prediction task is especially tricky in a complex environment with junctions and multiple corridors. In this work, we address the problem of forecasting the full 3D trajectory of a human in such environments. Our main insight is to show that one can first predict the 2D trajectory and then estimate the full 3D trajectory by conditioning the estimator on the predicted 2D trajectory. With this approach, we achieve results comparable or better than the state-of-the-art methods three times faster. As part of our contribution, we present a new dataset where, in contrast to existing datasets, the human motion is in a much larger area than a single room. We also present a complete robot system that integrates our human pose forecasting network on the mobile robot to enable real-time robot follow-ahead and present results from real-world experiments in multiple buildings on campus. Our project page, including supplementary material and videos, can be found at: https://qingyuan-jiang.github.io/iros2024_poseForecasting/
VioLA: Aligning Videos to 2D LiDAR Scans
Nov 08, 2023



We study the problem of aligning a video that captures a local portion of an environment to the 2D LiDAR scan of the entire environment. We introduce a method (VioLA) that starts with building a semantic map of the local scene from the image sequence, then extracts points at a fixed height for registering to the LiDAR map. Due to reconstruction errors or partial coverage of the camera scan, the reconstructed semantic map may not contain sufficient information for registration. To address this problem, VioLA makes use of a pre-trained text-to-image inpainting model paired with a depth completion model for filling in the missing scene content in a geometrically consistent fashion to support pose registration. We evaluate VioLA on two real-world RGB-D benchmarks, as well as a self-captured dataset of a large office scene. Notably, our proposed scene completion module improves the pose registration performance by up to 20%.
3D Surface Reconstruction in the Wild by Deforming Shape Priors from Synthetic Data
Feb 24, 2023



Reconstructing the underlying 3D surface of an object from a single image is a challenging problem that has received extensive attention from the computer vision community. Many learning-based approaches tackle this problem by learning a 3D shape prior from either ground truth 3D data or multi-view observations. To achieve state-of-the-art results, these methods assume that the objects are specified with respect to a fixed canonical coordinate frame, where instances of the same category are perfectly aligned. In this work, we present a new method for joint category-specific 3D reconstruction and object pose estimation from a single image. We show that one can leverage shape priors learned on purely synthetic 3D data together with a point cloud pose canonicalization method to achieve high-quality 3D reconstruction in the wild. Given a single depth image at test time, we first transform this partial point cloud into a learned canonical frame. Then, we use a neural deformation field to reconstruct the 3D surface of the object. Finally, we jointly optimize object pose and 3D shape to fit the partial depth observation. Our approach achieves state-of-the-art reconstruction performance across several real-world datasets, even when trained only on synthetic data. We further show that our method generalizes to different input modalities, from dense depth images to sparse and noisy LIDAR scans.
Category-Level Global Camera Pose Estimation with Multi-Hypothesis Point Cloud Correspondences
Sep 28, 2022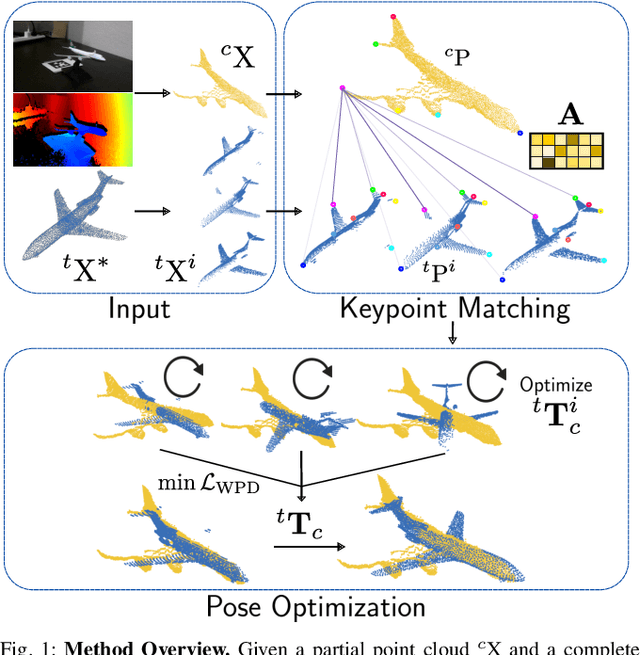
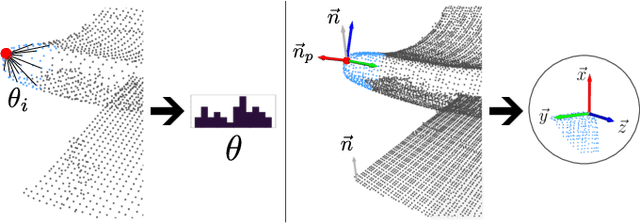
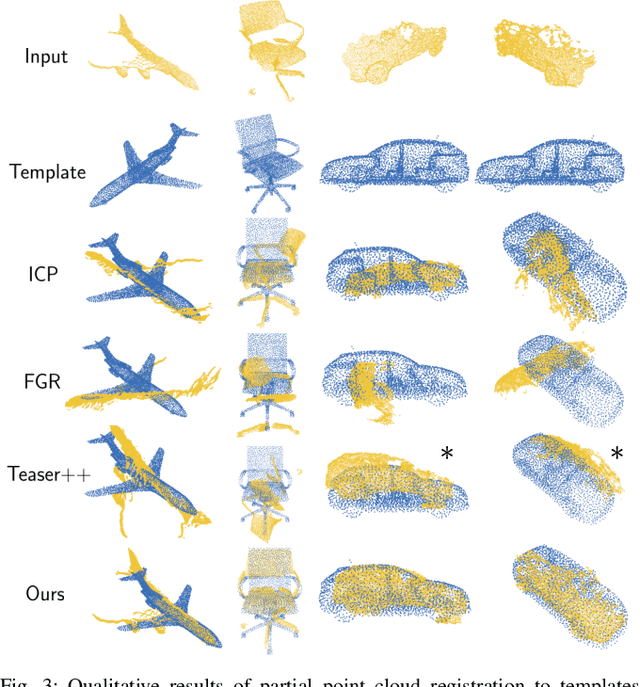
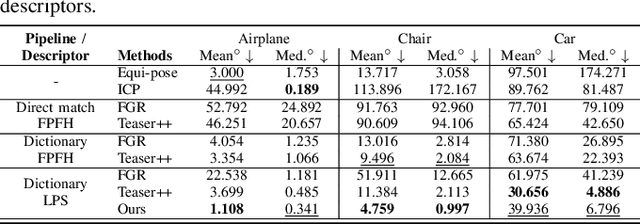
Correspondence search is an essential step in rigid point cloud registration algorithms. Most methods maintain a single correspondence at each step and gradually remove wrong correspondances. However, building one-to-one correspondence with hard assignments is extremely difficult, especially when matching two point clouds with many locally similar features. This paper proposes an optimization method that retains all possible correspondences for each keypoint when matching a partial point cloud to a complete point cloud. These uncertain correspondences are then gradually updated with the estimated rigid transformation by considering the matching cost. Moreover, we propose a new point feature descriptor that measures the similarity between local point cloud regions. Extensive experiments show that our method outperforms the state-of-the-art (SoTA) methods even when matching different objects within the same category. Notably, our method outperforms the SoTA methods when registering real-world noisy depth images to a template shape by up to 20% performance.
Unsupervised Continuous Object Representation Networks for Novel View Synthesis
Jul 30, 2020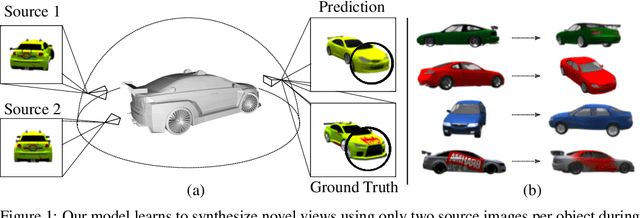
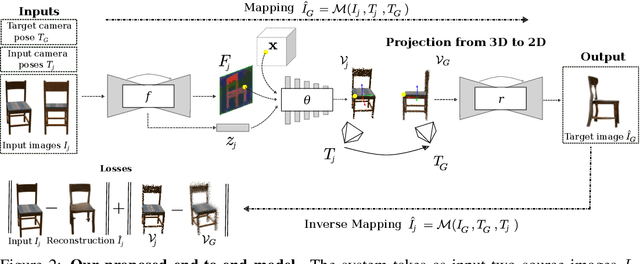


Novel View Synthesis (NVS) is concerned with the generation of novel views of a scene from one or more source images. NVS requires explicit reasoning about 3D object structure and unseen parts of the scene. As a result, current approaches rely on supervised training with either 3D models or multiple target images. We present Unsupervised Continuous Object Representation Networks (UniCORN), which encode the geometry and appearance of a 3D scene using a neural 3D representation. Our model is trained with only two source images per object, requiring no ground truth 3D models or target view supervision. Despite being unsupervised, UniCORN achieves comparable results to the state-of-the-art on challenging tasks, including novel view synthesis and single-view 3D reconstruction.