 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Surface Reconstruction in the Wild by Deforming Shape Priors from Synthetic Data
Feb 24, 2023Reconstructing the underlying 3D surface of an object from a single image is a challenging problem that has received extensive attention from the computer vision community. Many learning-based approaches tackle this problem by learning a 3D shape prior from either ground truth 3D data or multi-view observations. To achieve state-of-the-art results, these methods assume that the objects are specified with respect to a fixed canonical coordinate frame, where instances of the same category are perfectly aligned. In this work, we present a new method for joint category-specific 3D reconstruction and object pose estimation from a single image. We show that one can leverage shape priors learned on purely synthetic 3D data together with a point cloud pose canonicalization method to achieve high-quality 3D reconstruction in the wild. Given a single depth image at test time, we first transform this partial point cloud into a learned canonical frame. Then, we use a neural deformation field to reconstruct the 3D surface of the object. Finally, we jointly optimize object pose and 3D shape to fit the partial depth observation. Our approach achieves state-of-the-art reconstruction performance across several real-world datasets, even when trained only on synthetic data. We further show that our method generalizes to different input modalities, from dense depth images to sparse and noisy LIDAR scans.
Category-Level Global Camera Pose Estimation with Multi-Hypothesis Point Cloud Correspondences
Sep 28, 2022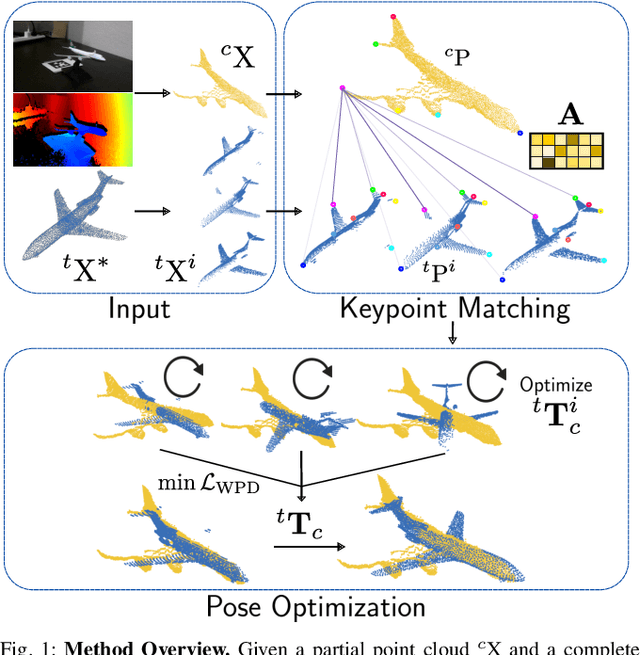
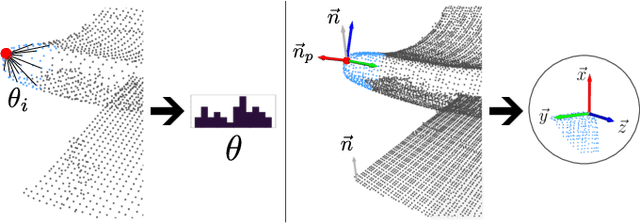
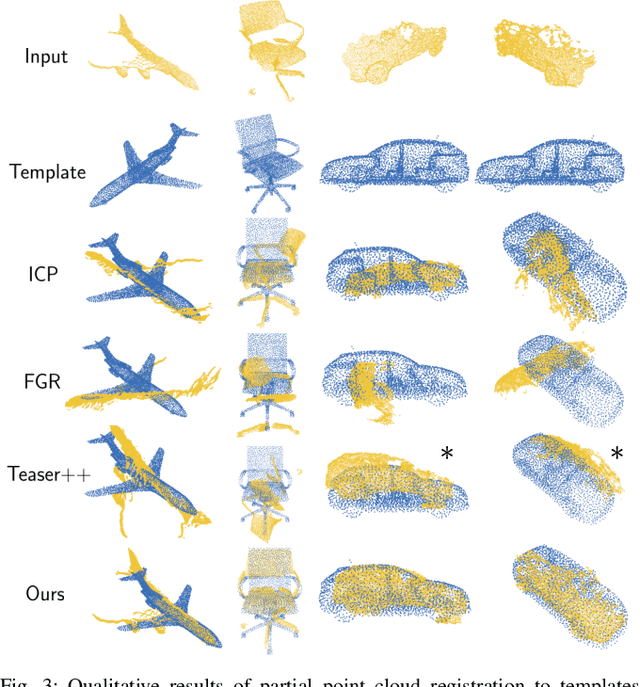
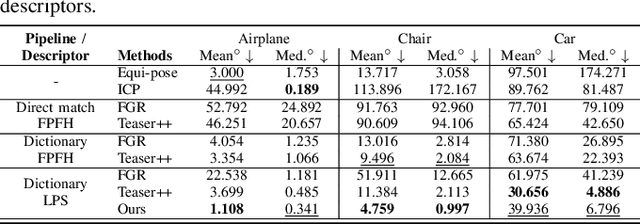
Correspondence search is an essential step in rigid point cloud registration algorithms. Most methods maintain a single correspondence at each step and gradually remove wrong correspondances. However, building one-to-one correspondence with hard assignments is extremely difficult, especially when matching two point clouds with many locally similar features. This paper proposes an optimization method that retains all possible correspondences for each keypoint when matching a partial point cloud to a complete point cloud. These uncertain correspondences are then gradually updated with the estimated rigid transformation by considering the matching cost. Moreover, we propose a new point feature descriptor that measures the similarity between local point cloud regions. Extensive experiments show that our method outperforms the state-of-the-art (SoTA) methods even when matching different objects within the same category. Notably, our method outperforms the SoTA methods when registering real-world noisy depth images to a template shape by up to 20% performance.
Apple Counting using Convolutional Neural Networks
Aug 24, 2022



Estimating accurate and reliable fruit and vegetable counts from images in real-world settings, such as orchards, is a challenging problem that has received significant recent attention. Estimating fruit counts before harvest provides useful information for logistics planning. While considerable progress has been made toward fruit detection, estimating the actual counts remains challenging. In practice, fruits are often clustered together. Therefore, methods that only detect fruits fail to offer general solutions to estimate accurate fruit counts. Furthermore, in horticultural studies, rather than a single yield estimate, finer information such as the distribution of the number of apples per cluster is desirable. In this work, we formulate fruit counting from images as a multi-class classification problem and solve it by training a Convolutional Neural Network. We first evaluate the per-image accuracy of our method and compare it with a state-of-the-art method based on Gaussian Mixture Models over four test datasets. Even though the parameters of the Gaussian Mixture Model-based method are specifically tuned for each dataset, our network outperforms it in three out of four datasets with a maximum of 94\% accuracy. Next, we use the method to estimate the yield for two datasets for which we have ground truth. Our method achieved 96-97\% accuracies. For additional details please see our video here: https://www.youtube.com/watch?v=Le0mb5P-SYc}{https://www.youtube.com/watch?v=Le0mb5P-SYc.
Visual Servoing in Orchard Settings
Aug 24, 2022
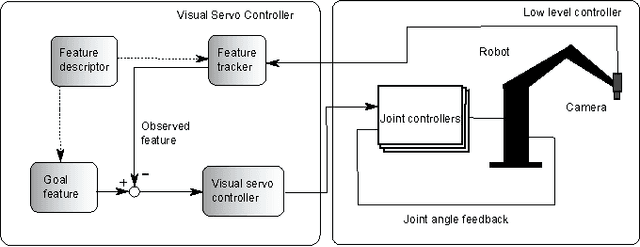


We present a general framework for accurate positioning of sensors and end effectors in farm settings using a camera mounted on a robotic manipulator. Our main contribution is a visual servoing approach based on a new and robust feature tracking algorithm. Results from field experiments performed at an apple orchard demonstrate that our approach converges to a given termination criterion even under environmental influences such as strong winds, varying illumination conditions and partial occlusion of the target object. Further, we show experimentally that the system converges to the desired view for a wide range of initial conditions. This approach opens possibilities for new applications such as automated fruit inspection, fruit picking or precise pesticide application.
Multi-Step Recurrent Q-Learning for Robotic Velcro Peeling
Nov 16, 2020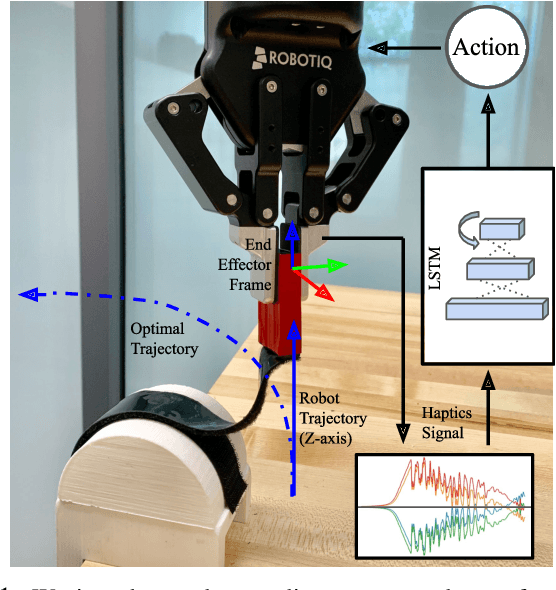
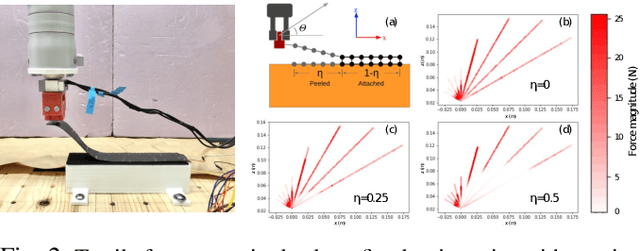
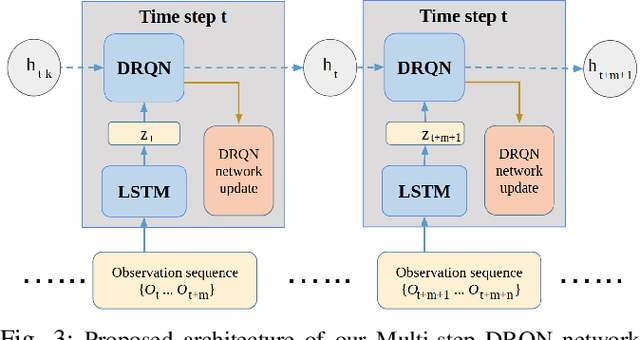
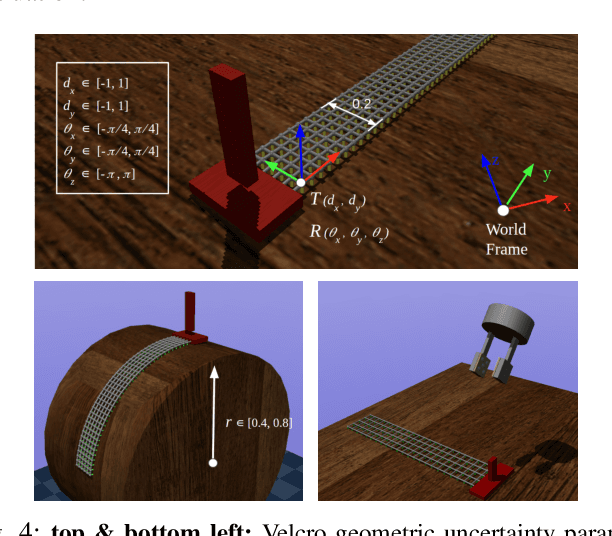
Learning object manipulation is a critical skill for robots to interact with their environment. Even though there has been significant progress in robotic manipulation of rigid objects, interacting with non-rigid objects remains challenging for robots. In this work, we introduce velcro peeling as a representative application for robotic manipulation of non-rigid objects in complex environments. We present a method of learning force-based manipulation from noisy and incomplete sensor inputs in partially observable environments by modeling long term dependencies between measurements with a multi-step deep recurrent network. We present experiments on a real robot to show the necessity of modeling these long term dependencies and validate our approach in simulation and robot experiments. Our results show that using tactile input enables the robot to overcome geometric uncertainties present in the environment with high fidelity in ~90% of all cases, outperforming the baselines by a large margin.
Unsupervised Continuous Object Representation Networks for Novel View Synthesis
Jul 30, 2020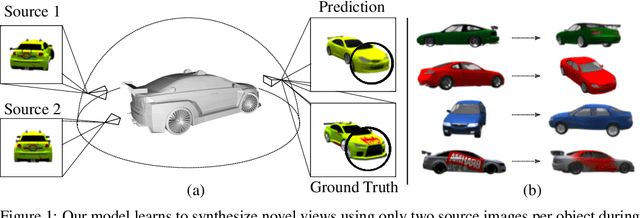
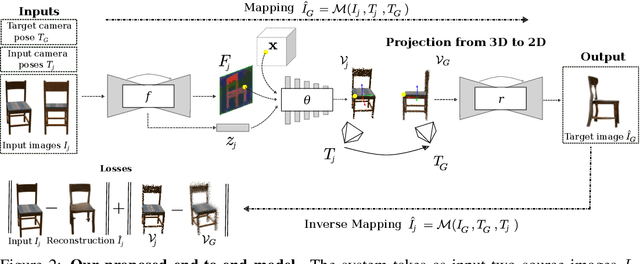


Novel View Synthesis (NVS) is concerned with the generation of novel views of a scene from one or more source images. NVS requires explicit reasoning about 3D object structure and unseen parts of the scene. As a result, current approaches rely on supervised training with either 3D models or multiple target images. We present Unsupervised Continuous Object Representation Networks (UniCORN), which encode the geometry and appearance of a 3D scene using a neural 3D representation. Our model is trained with only two source images per object, requiring no ground truth 3D models or target view supervision. Despite being unsupervised, UniCORN achieves comparable results to the state-of-the-art on challenging tasks, including novel view synthesis and single-view 3D reconstruction.
MinneApple: A Benchmark Dataset for Apple Detection and Segmentation
Sep 13, 2019

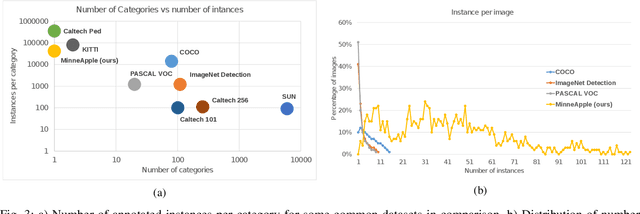
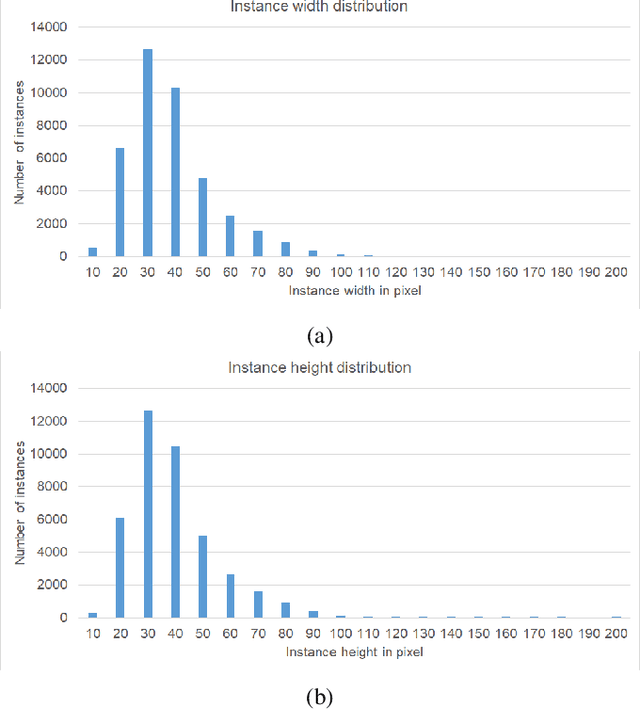
In this work, we present a new dataset to advance the state-of-the-art in fruit detection, segmentation, and counting in orchard environments. While there has been significant recent interest in solving these problems, the lack of a unified dataset has made it difficult to compare results. We hope to enable direct comparisons by providing a large variety of high-resolution images acquired in orchards, together with human annotations of the fruit on trees. The fruits are labeled using polygonal masks for each object instance to aid in precise object detection, localization, and segmentation. Additionally, we provide data for patch-based counting of clustered fruits. Our dataset contains over 41, 000 annotated object instances in 1000 images. We present a detailed overview of the dataset together with baseline performance analysis for bounding box detection, segmentation, and fruit counting as well as representative results for yield estimation. We make this dataset publicly available and host a CodaLab challenge to encourage comparison of results on a common dataset. To download the data and learn more about MinneApple please see the project website: http://rsn.cs.umn.edu/index.php/MinneApple. Up to date information is available online.
Semantics-Aware Image to Image Translation and Domain Transfer
Apr 03, 2019

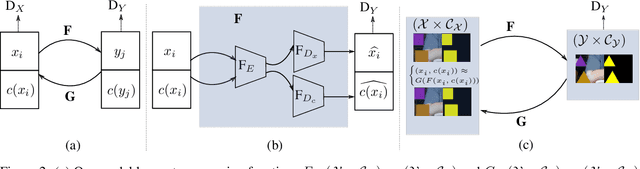
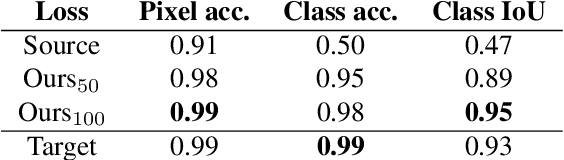
Image to image translation is the problem of transferring an image from a source domain to a target domain. We present a new method to transfer the underlying semantics of an image even when there are geometric changes across the two domains. Specifically, we present a Generative Adversarial Network (GAN) that can transfer semantic information presented as segmentation masks. Our main technical contribution is an encoder-decoder based generator architecture that jointly encodes the image and its underlying semantics and translates both simultaneously to the target domain. Additionally, we propose object transfiguration and cross-domain semantic consistency losses that preserve the underlying semantic labels maps. We demonstrate the effectiveness of our approach in multiple object transfiguration and domain transfer tasks through qualitative and quantitative experiments. The results show that our method is better at transferring image semantics than state of the art image to image translation methods.
A Comparative Study of Fruit Detection and Counting Methods for Yield Mapping in Apple Orchards
Mar 06, 2019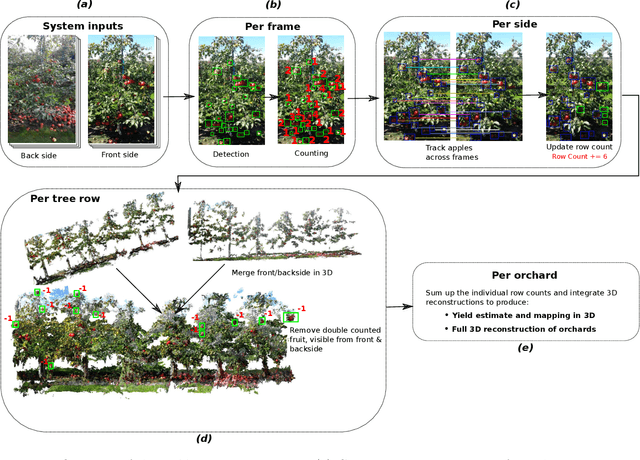
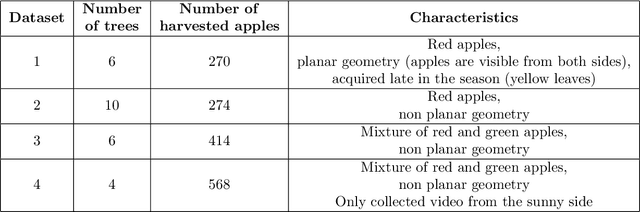
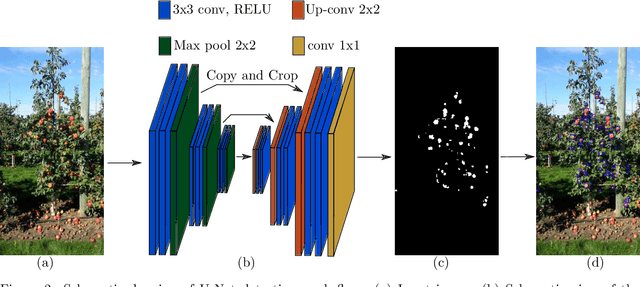

We present new methods for apple detection and counting based on recent deep learning approaches and compare them with state-of-the-art results based on classical methods. Our goal is to quantify performance improvements by neural network-based methods compared to methods based on classical approaches. Additionally, we introduce a complete system for counting apples in an entire row. This task is challenging as it requires tracking fruits in images from both sides of the row. We evaluate the performances of three fruit detection methods and two fruit counting methods on six datasets. Results indicate that the classical detection approach still outperforms the deep learning based methods in the majority of the datasets. For fruit counting though, the deep learning based approach performs better for all of the datasets. Combining the classical detection method together with the neural network based counting approach, we achieve remarkable yield accuracies ranging from 95.56% to 97.83%.
Classification of Aerial Photogrammetric 3D Point Clouds
May 23, 2017
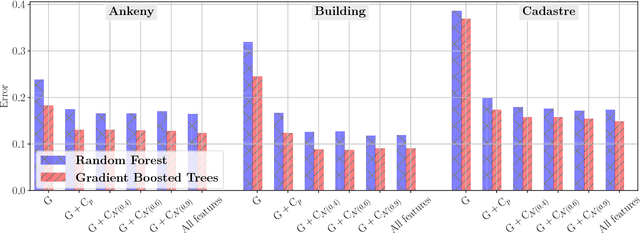


We present a powerful method to extract per-point semantic class labels from aerialphotogrammetry data. Labeling this kind of data is important for tasks such as environmental modelling, object classification and scene understanding. Unlike previous point cloud classification methods that rely exclusively on geometric features, we show that incorporating color information yields a significant increase in accuracy in detecting semantic classes. We test our classification method on three real-world photogrammetry datasets that were generated with Pix4Dmapper Pro, and with varying point densities. We show that off-the-shelf machine learning techniques coupled with our new features allow us to train highly accurate classifiers that generalize well to unseen data, processing point clouds containing 10 million points in less than 3 minutes on a desktop computer.