 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineControlNet: Fine-level Text Control for Image Generation with Spatially Aligned Text Control Injection
Dec 14, 2023Recently introduced ControlNet has the ability to steer the text-driven image generation process with geometric input such as human 2D pose, or edge features. While ControlNet provides control over the geometric form of the instances in the generated image, it lacks the capability to dictate the visual appearance of each instance. We present FineControlNet to provide fine control over each instance's appearance while maintaining the precise pose control capability. Specifically, we develop and demonstrate FineControlNet with geometric control via human pose images and appearance control via instance-level text prompts. The spatial alignment of instance-specific text prompts and 2D poses in latent space enables the fine control capabilities of FineControlNet. We evaluate the performance of FineControlNet with rigorous comparison against state-of-the-art pose-conditioned text-to-image diffusion models. FineControlNet achieves superior performance in generating images that follow the user-provided instance-specific text prompts and poses compared with existing methods. Project webpage: https://samsunglabs.github.io/FineControlNet-project-page
VioLA: Aligning Videos to 2D LiDAR Scans
Nov 08, 2023



We study the problem of aligning a video that captures a local portion of an environment to the 2D LiDAR scan of the entire environment. We introduce a method (VioLA) that starts with building a semantic map of the local scene from the image sequence, then extracts points at a fixed height for registering to the LiDAR map. Due to reconstruction errors or partial coverage of the camera scan, the reconstructed semantic map may not contain sufficient information for registration. To address this problem, VioLA makes use of a pre-trained text-to-image inpainting model paired with a depth completion model for filling in the missing scene content in a geometrically consistent fashion to support pose registration. We evaluate VioLA on two real-world RGB-D benchmarks, as well as a self-captured dataset of a large office scene. Notably, our proposed scene completion module improves the pose registration performance by up to 20%.
RICo: Rotate-Inpaint-Complete for Generalizable Scene Reconstruction
Jul 21, 2023
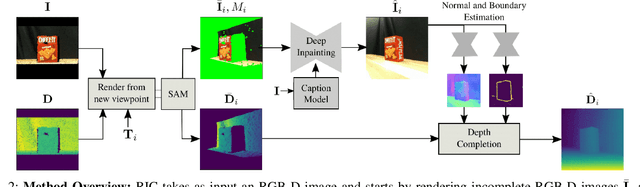
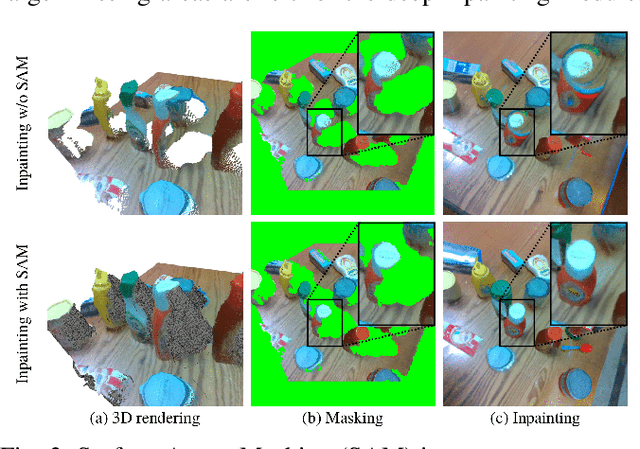
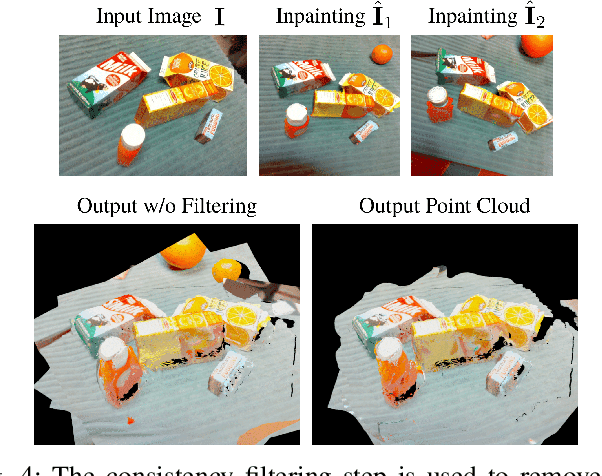
General scene reconstruction refers to the task of estimating the full 3D geometry and texture of a scene containing previously unseen objects. In many practical applications such as AR/VR, autonomous navigation, and robotics, only a single view of the scene may be available, making the scene reconstruction a very challenging task. In this paper, we present a method for scene reconstruction by structurally breaking the problem into two steps: rendering novel views via inpainting and 2D to 3D scene lifting. Specifically, we leverage the generalization capability of large language models to inpaint the missing areas of scene color images rendered from different views. Next, we lift these inpainted images to 3D by predicting normals of the inpainted image and solving for the missing depth values. By predicting for normals instead of depth directly, our method allows for robustness to changes in depth distributions and scale. With rigorous quantitative evaluation, we show that our method outperforms multiple baselines while providing generalization to novel objects and scenes.
Real-time Simultaneous Multi-Object 3D Shape Reconstruction, 6DoF Pose Estimation and Dense Grasp Prediction
May 16, 2023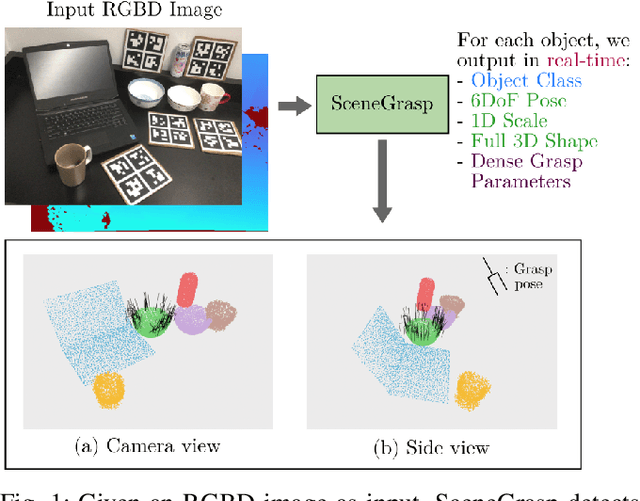
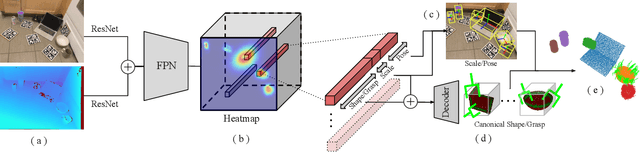
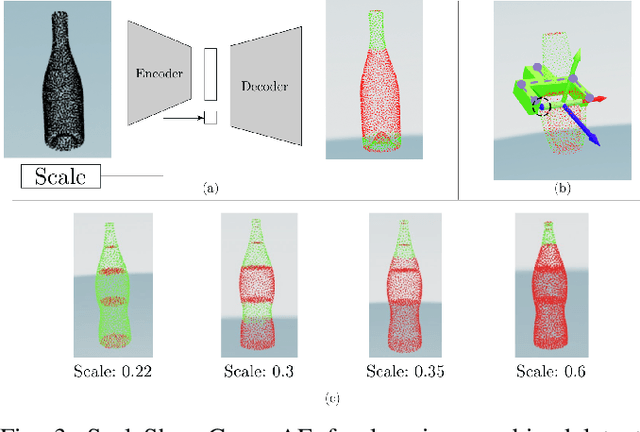
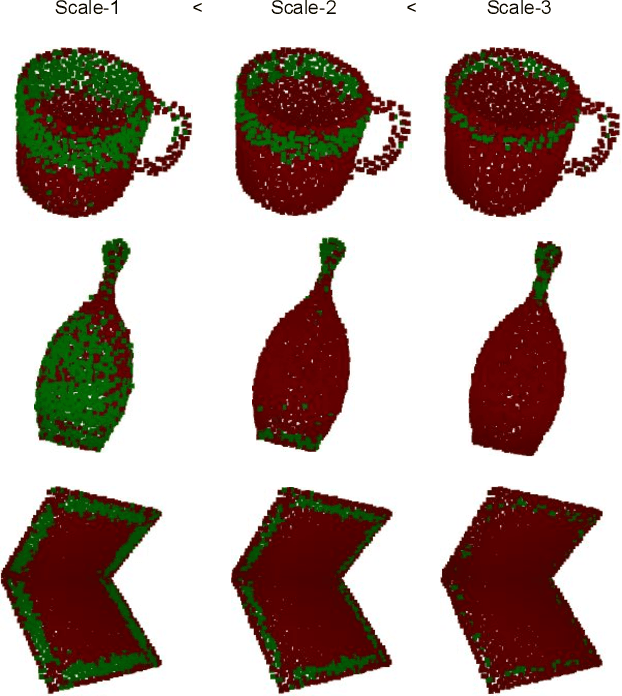
Robotic manipulation systems operating in complex environments rely on perception systems that provide information about the geometry (pose and 3D shape) of the objects in the scene along with other semantic information such as object labels. This information is then used for choosing the feasible grasps on relevant objects. In this paper, we present a novel method to provide this geometric and semantic information of all objects in the scene as well as feasible grasps on those objects simultaneously. The main advantage of our method is its speed as it avoids sequential perception and grasp planning steps. With detailed quantitative analysis, we show that our method delivers competitive performance compared to the state-of-the-art dedicated methods for object shape, pose, and grasp predictions while providing fast inference at 30 frames per second speed.
Neural Optimal Control using Learned System Dynamics
Feb 20, 2023We study the problem of generating control laws for systems with unknown dynamics. Our approach is to represent the controller and the value function with neural networks, and to train them using loss functions adapted from the Hamilton-Jacobi-Bellman (HJB) equations. In the absence of a known dynamics model, our method first learns the state transitions from data collected by interacting with the system in an offline process. The learned transition function is then integrated to the HJB equations and used to forward simulate the control signals produced by our controller in a feedback loop. In contrast to trajectory optimization methods that optimize the controller for a single initial state, our controller can generate near-optimal control signals for initial states from a large portion of the state space. Compared to recent model-based reinforcement learning algorithms, we show that our method is more sample efficient and trains faster by an order of magnitude. We demonstrate our method in a number of tasks, including the control of a quadrotor with 12 state variables.
Category-Level Global Camera Pose Estimation with Multi-Hypothesis Point Cloud Correspondences
Sep 28, 2022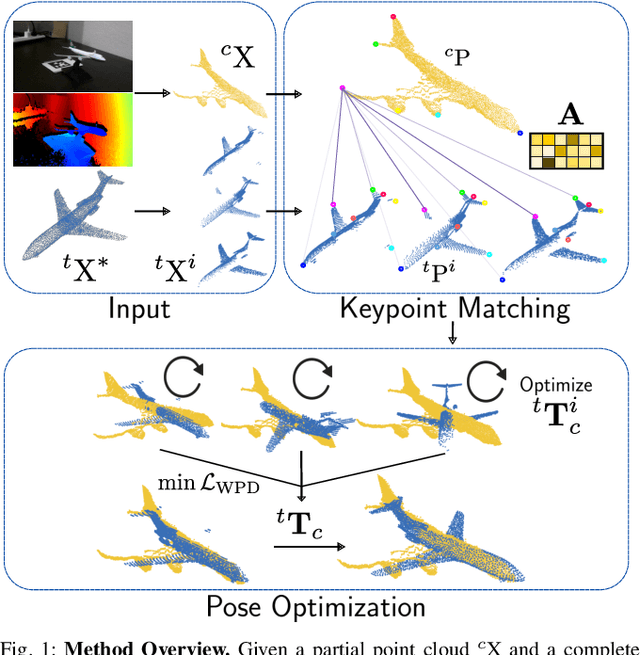
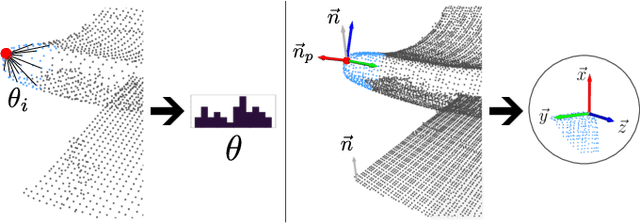
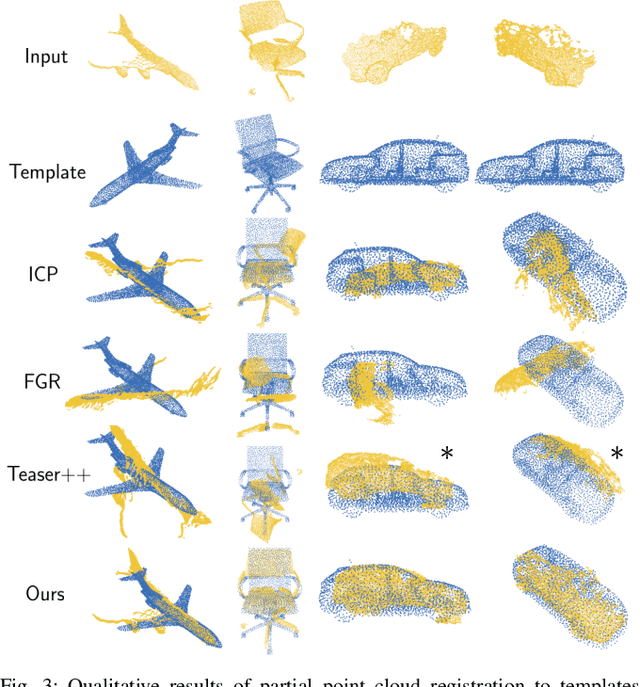
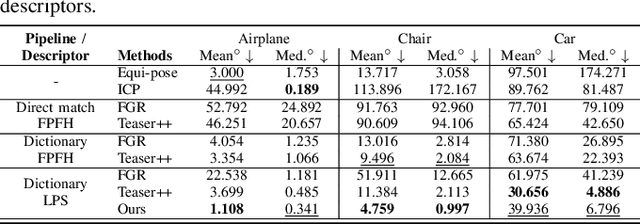
Correspondence search is an essential step in rigid point cloud registration algorithms. Most methods maintain a single correspondence at each step and gradually remove wrong correspondances. However, building one-to-one correspondence with hard assignments is extremely difficult, especially when matching two point clouds with many locally similar features. This paper proposes an optimization method that retains all possible correspondences for each keypoint when matching a partial point cloud to a complete point cloud. These uncertain correspondences are then gradually updated with the estimated rigid transformation by considering the matching cost. Moreover, we propose a new point feature descriptor that measures the similarity between local point cloud regions. Extensive experiments show that our method outperforms the state-of-the-art (SoTA) methods even when matching different objects within the same category. Notably, our method outperforms the SoTA methods when registering real-world noisy depth images to a template shape by up to 20% performance.
Unsupervised Continuous Object Representation Networks for Novel View Synthesis
Jul 30, 2020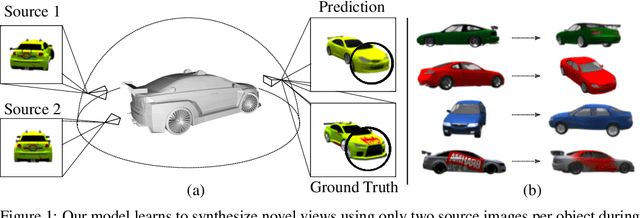
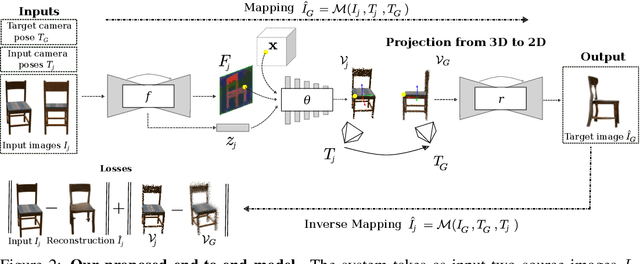


Novel View Synthesis (NVS) is concerned with the generation of novel views of a scene from one or more source images. NVS requires explicit reasoning about 3D object structure and unseen parts of the scene. As a result, current approaches rely on supervised training with either 3D models or multiple target images. We present Unsupervised Continuous Object Representation Networks (UniCORN), which encode the geometry and appearance of a 3D scene using a neural 3D representation. Our model is trained with only two source images per object, requiring no ground truth 3D models or target view supervision. Despite being unsupervised, UniCORN achieves comparable results to the state-of-the-art on challenging tasks, including novel view synthesis and single-view 3D reconstruction.
Active localization of multiple targets using noisy relative measurements
Feb 23, 2020
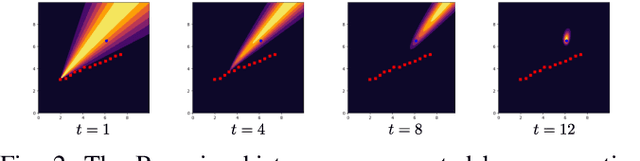
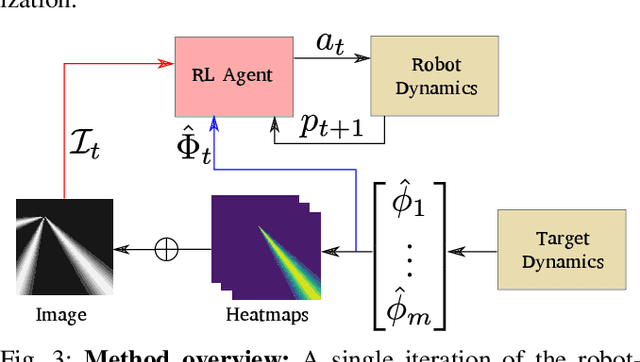
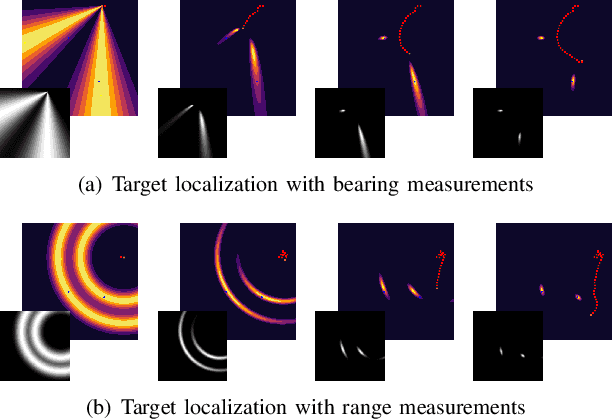
Consider a mobile robot tasked with localizing targets at unknown locations by obtaining relative measurements. The observations can be bearing or range measurements. How should the robot move so as to localize the targets and minimize the uncertainty in their locations as quickly as possible? Most existing approaches are either greedy in nature or rely on accurate initial estimates. We formulate this path planning problem as an unsupervised learning problem where the measurements are aggregated using a Bayesian histogram filter. The robot learns to minimize the total uncertainty of each target in the shortest amount of time using the current measurement and an aggregate representation of the current belief state. We analyze our method in a series of experiments where we show that our method outperforms a standard greedy approach. In addition, its performance is also comparable to an offline algorithm which has access to the true location of the targets.
Higher Order Function Networks for View Planning and Multi-View Reconstruction
Oct 04, 2019
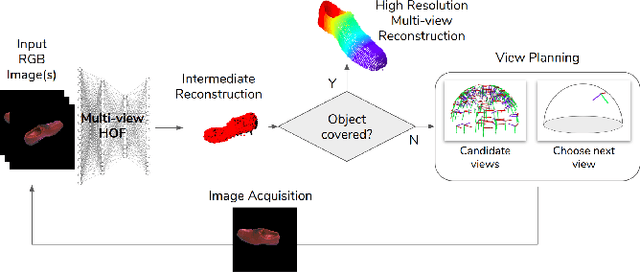
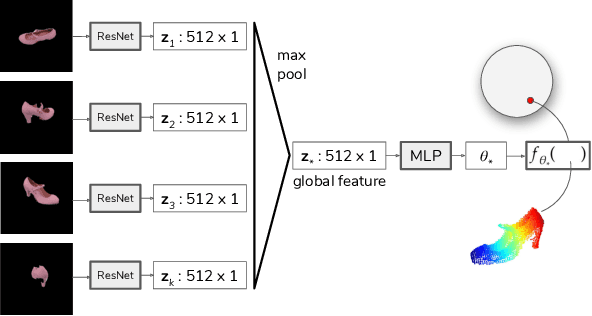
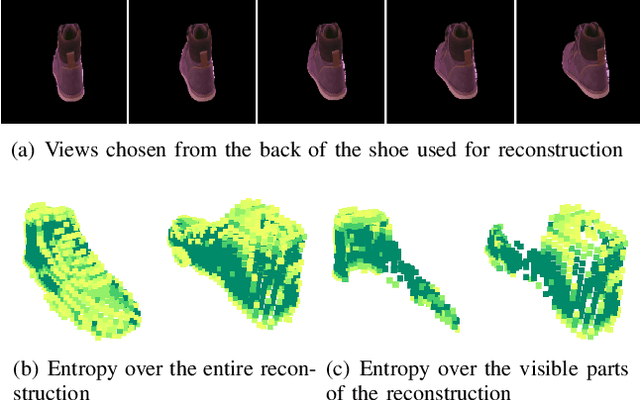
We consider the problem of planning views for a robot to acquire images of an object for visual inspection and reconstruction. In contrast to offline methods which require a 3D model of the object as input or online methods which rely on only local measurements, our method uses a neural network which encodes shape information for a large number of objects. We build on recent deep learning methods capable of generating a complete 3D reconstruction of an object from a single image. Specifically, in this work, we extend a recent method which uses Higher Order Functions (HOF) to represent the shape of the object. We present a new generalization of this method to incorporate multiple images as input and establish a connection between visibility and reconstruction quality. This relationship forms the foundation of our view planning method where we compute viewpoints to visually cover the output of the multi-view HOF network with as few images as possible. Experiments indicate that our method provides a good compromise between online and offline methods: Similar to online methods, our method does not require the true object model as input. In terms of number of views, it is much more efficient. In most cases, its performance is comparable to the optimal offline case even on object classes the network has not been trained on.
Asynchronous Network Formation in Unknown Unbounded Environments
Aug 02, 2019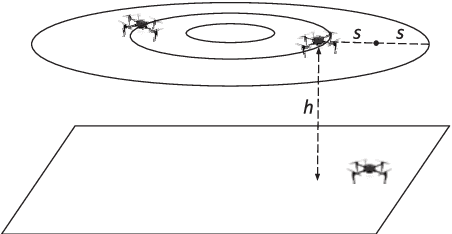
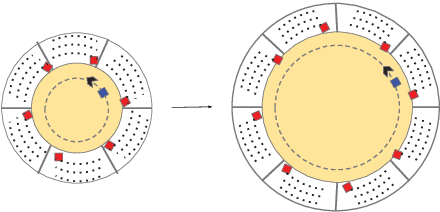
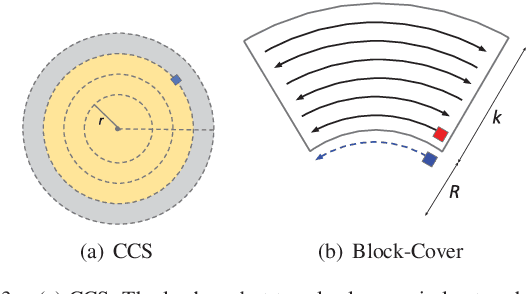
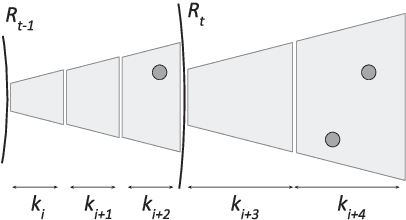
In this paper, we study the Online Network Formation Problem (ONFP) for a mobile multi-robot system. Consider a group of robots with a bounded communication range operating in a large open area. One of the robots has a piece of information which has to be propagated to all other robots. What strategy should the robots pursue to disseminate the information to the rest of the robots as quickly as possible? The initial locations of the robots are unknown to each other, therefore the problem must be solved in an online fashion. For this problem, we present an algorithm whose competitive ratio is $O(H \cdot \max\{M,\sqrt{M H}\})$ for arbitrary robot deployments, where $M$ is the largest edge length in the Euclidean minimum spanning tree on the initial robot configuration and $H$ is the height of the tree. We also study the case when the robot initial positions are chosen uniformly at random and improve the ratio to $O(M)$. Finally, we present simulation results to validate the performance in larger scales and demonstrate our algorithm using three robots in a field experiment.