 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFAS-Grasp: Closed Loop Grasping with Visual Feedback and Adaptive Sampling
Oct 27, 2023We consider the problem of closed-loop robotic grasping and present a novel planner which uses Visual Feedback and an uncertainty-aware Adaptive Sampling strategy (VFAS) to close the loop. At each iteration, our method VFAS-Grasp builds a set of candidate grasps by generating random perturbations of a seed grasp. The candidates are then scored using a novel metric which combines a learned grasp-quality estimator, the uncertainty in the estimate and the distance from the seed proposal to promote temporal consistency. Additionally, we present two mechanisms to improve the efficiency of our sampling strategy: We dynamically scale the sampling region size and number of samples in it based on past grasp scores. We also leverage a motion vector field estimator to shift the center of our sampling region. We demonstrate that our algorithm can run in real time (20 Hz) and is capable of improving grasp performance for static scenes by refining the initial grasp proposal. We also show that it can enable grasping of slow moving objects, such as those encountered during human to robot handover.
HIO-SDF: Hierarchical Incremental Online Signed Distance Fields
Oct 14, 2023



A good representation of a large, complex mobile robot workspace must be space-efficient yet capable of encoding relevant geometric details. When exploring unknown environments, it needs to be updatable incrementally in an online fashion. We introduce HIO-SDF, a new method that represents the environment as a Signed Distance Field (SDF). State of the art representations of SDFs are based on either neural networks or voxel grids. Neural networks are capable of representing the SDF continuously. However, they are hard to update incrementally as neural networks tend to forget previously observed parts of the environment unless an extensive sensor history is stored for training. Voxel-based representations do not have this problem but they are not space-efficient especially in large environments with fine details. HIO-SDF combines the advantages of these representations using a hierarchical approach which employs a coarse voxel grid that captures the observed parts of the environment together with high-resolution local information to train a neural network. HIO-SDF achieves a 46% lower mean global SDF error across all test scenes than a state of the art continuous representation, and a 30% lower error than a discrete representation at the same resolution as our coarse global SDF grid.
RAMP: Hierarchical Reactive Motion Planning for Manipulation Tasks Using Implicit Signed Distance Functions
May 17, 2023
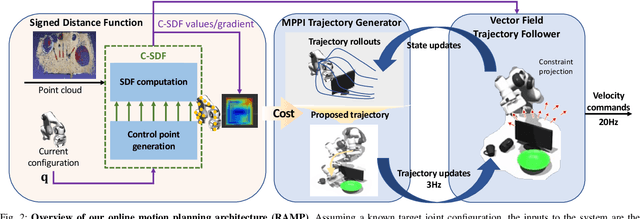
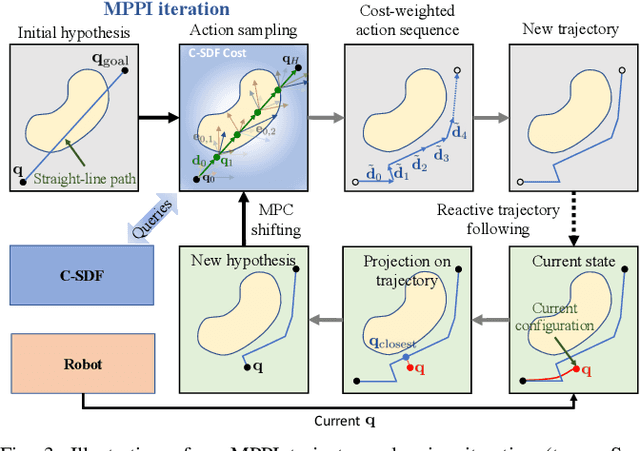
We introduce Reactive Action and Motion Planner (RAMP), which combines the strengths of search-based and reactive approaches for motion planning. In essence, RAMP is a hierarchical approach where a novel variant of a Model Predictive Path Integral (MPPI) controller is used to generate trajectories which are then followed asynchronously by a local vector field controller. We demonstrate, in the context of a table clearing application, that RAMP can rapidly find paths in the robot's configuration space, satisfy task and robot-specific constraints, and provide safety by reacting to static or dynamically moving obstacles. RAMP achieves superior performance through a number of key innovations: we use Signed Distance Function (SDF) representations directly from the robot configuration space, both for collision checking and reactive control. The use of SDFs allows for a smoother definition of collision cost when planning for a trajectory, and is critical in ensuring safety while following trajectories. In addition, we introduce a novel variant of MPPI which, combined with the safety guarantees of the vector field trajectory follower, performs incremental real-time global trajectory planning. Simulation results establish that our method can generate paths that are comparable to traditional and state-of-the-art approaches in terms of total trajectory length while being up to 30 times faster. Real-world experiments demonstrate the safety and effectiveness of our approach in challenging table clearing scenarios.
Real-time Simultaneous Multi-Object 3D Shape Reconstruction, 6DoF Pose Estimation and Dense Grasp Prediction
May 16, 2023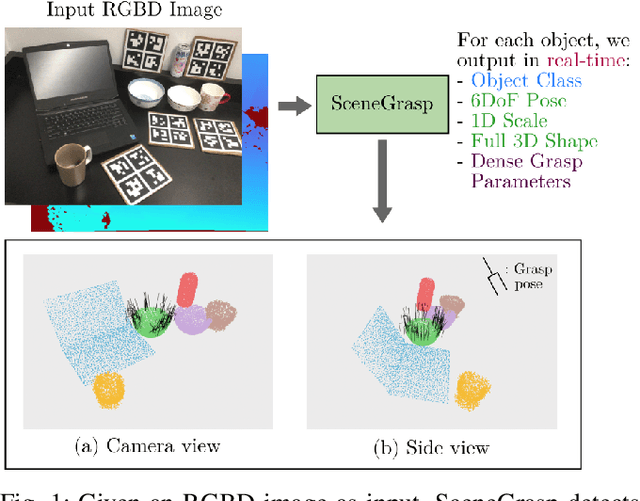
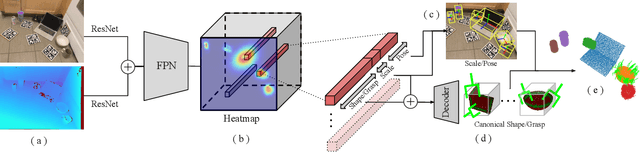
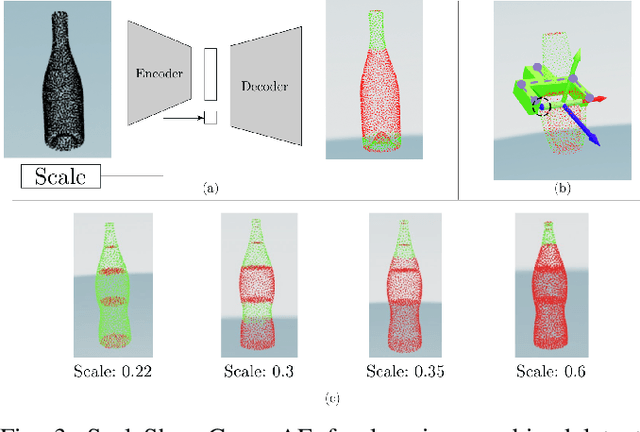
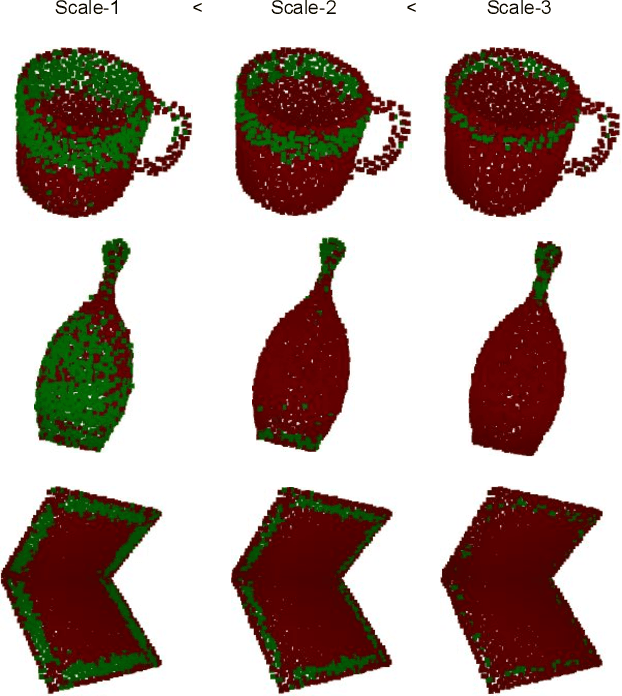
Robotic manipulation systems operating in complex environments rely on perception systems that provide information about the geometry (pose and 3D shape) of the objects in the scene along with other semantic information such as object labels. This information is then used for choosing the feasible grasps on relevant objects. In this paper, we present a novel method to provide this geometric and semantic information of all objects in the scene as well as feasible grasps on those objects simultaneously. The main advantage of our method is its speed as it avoids sequential perception and grasp planning steps. With detailed quantitative analysis, we show that our method delivers competitive performance compared to the state-of-the-art dedicated methods for object shape, pose, and grasp predictions while providing fast inference at 30 frames per second speed.
Pick2Place: Task-aware 6DoF Grasp Estimation via Object-Centric Perspective Affordance
Apr 08, 2023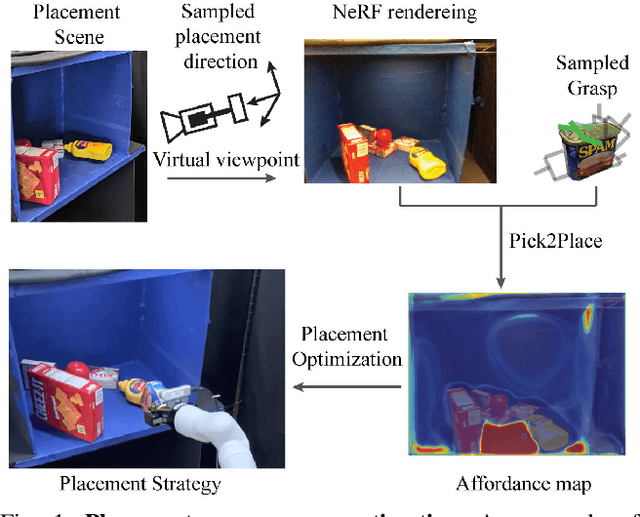
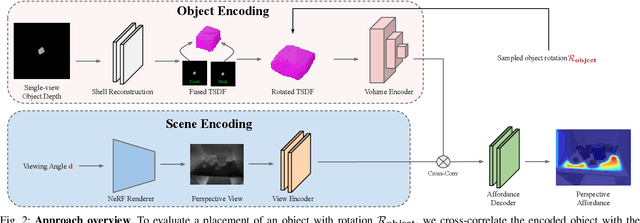

The choice of a grasp plays a critical role in the success of downstream manipulation tasks. Consider a task of placing an object in a cluttered scene; the majority of possible grasps may not be suitable for the desired placement. In this paper, we study the synergy between the picking and placing of an object in a cluttered scene to develop an algorithm for task-aware grasp estimation. We present an object-centric action space that encodes the relationship between the geometry of the placement scene and the object to be placed in order to provide placement affordance maps directly from perspective views of the placement scene. This action space enables the computation of a one-to-one mapping between the placement and picking actions allowing the robot to generate a diverse set of pick-and-place proposals and to optimize for a grasp under other task constraints such as robot kinematics and collision avoidance. With experiments both in simulation and on a real robot we demonstrate that with our method, the robot is able to successfully complete the task of placement-aware grasping with over 89% accuracy in such a way that generalizes to novel objects and scenes.
Self-supervised Wide Baseline Visual Servoing via 3D Equivariance
Sep 12, 2022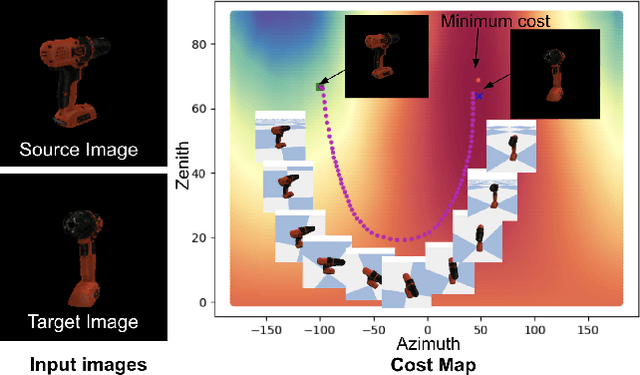
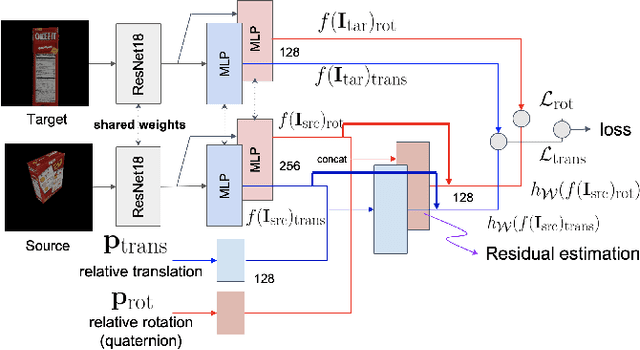
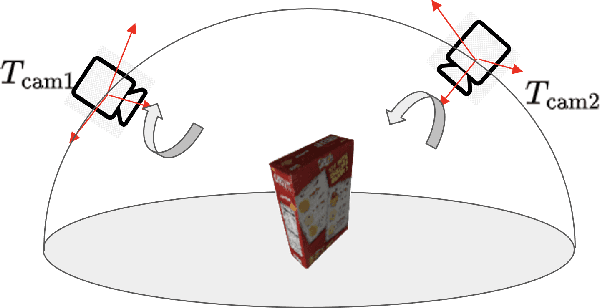

One of the challenging input settings for visual servoing is when the initial and goal camera views are far apart. Such settings are difficult because the wide baseline can cause drastic changes in object appearance and cause occlusions. This paper presents a novel self-supervised visual servoing method for wide baseline images which does not require 3D ground truth supervision. Existing approaches that regress absolute camera pose with respect to an object require 3D ground truth data of the object in the forms of 3D bounding boxes or meshes. We learn a coherent visual representation by leveraging a geometric property called 3D equivariance-the representation is transformed in a predictable way as a function of 3D transformation. To ensure that the feature-space is faithful to the underlying geodesic space, a geodesic preserving constraint is applied in conjunction with the equivariance. We design a Siamese network that can effectively enforce these two geometric properties without requiring 3D supervision. With the learned model, the relative transformation can be inferred simply by following the gradient in the learned space and used as feedback for closed-loop visual servoing. Our method is evaluated on objects from the YCB dataset, showing meaningful outperformance on a visual servoing task, or object alignment task with respect to state-of-the-art approaches that use 3D supervision. Ours yields more than 35% average distance error reduction and more than 90% success rate with 3cm error tolerance.
Learning Continuous Cost-to-Go Functions for Non-holonomic Systems
Mar 20, 2021

This paper presents a supervised learning method to generate continuous cost-to-go functions of non-holonomic systems directly from the workspace description. Supervision from informative examples reduces training time and improves network performance. The manifold representing the optimal trajectories of a non-holonomic system has high-curvature regions which can not be efficiently captured with uniform sampling. To address this challenge, we present an adaptive sampling method which makes use of sampling-based planners along with local, closed-form solutions to generate training samples. The cost-to-go function over a specific workspace is represented as a neural network whose weights are generated by a second, higher order network. The networks are trained in an end-to-end fashion. In our previous work, this architecture was shown to successfully learn to generate the cost-to-go functions of holonomic systems using uniform sampling. In this work, we show that uniform sampling fails for non-holonomic systems. However, with the proposed adaptive sampling methodology, our network can generate near-optimal trajectories for non-holonomic systems while avoiding obstacles. Experiments show that our method is two orders of magnitude faster compared to traditional approaches in cluttered environments.
Cost-to-Go Function Generating Networks for High Dimensional Motion Planning
Dec 10, 2020


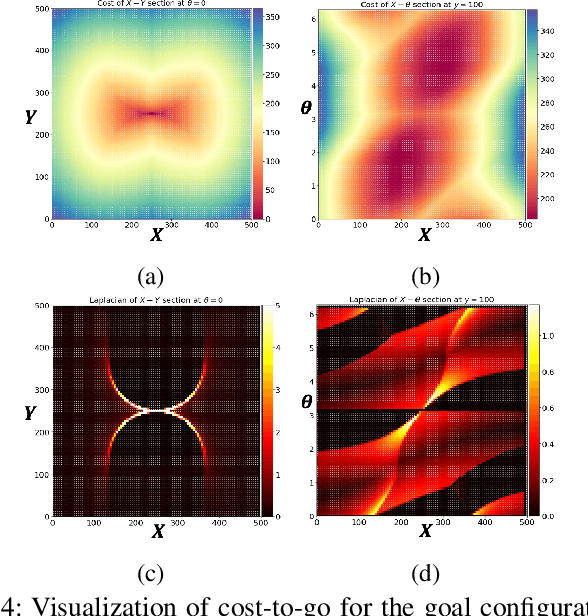
This paper presents c2g-HOF networks which learn to generate cost-to-go functions for manipulator motion planning. The c2g-HOF architecture consists of a cost-to-go function over the configuration space represented as a neural network (c2g-network) as well as a Higher Order Function (HOF) network which outputs the weights of the c2g-network for a given input workspace. Both networks are trained end-to-end in a supervised fashion using costs computed from traditional motion planners. Once trained, c2g-HOF can generate a smooth and continuous cost-to-go function directly from workspace sensor inputs (represented as a point cloud in 3D or an image in 2D). At inference time, the weights of the c2g-network are computed very efficiently and near-optimal trajectories are generated by simply following the gradient of the cost-to-go function. We compare c2g-HOF with traditional planning algorithms for various robots and planning scenarios. The experimental results indicate that planning with c2g-HOF is significantly faster than other motion planning algorithms, resulting in orders of magnitude improvement when including collision checking. Furthermore, despite being trained from sparsely sampled trajectories in configuration space, c2g-HOF generalizes to generate smoother, and often lower cost, trajectories. We demonstrate cost-to-go based planning on a 7 DoF manipulator arm where motion planning in a complex workspace requires only 0.13 seconds for the entire trajectory.
Learning to Generate Cost-to-Go Functions for Efficient Motion Planning
Oct 27, 2020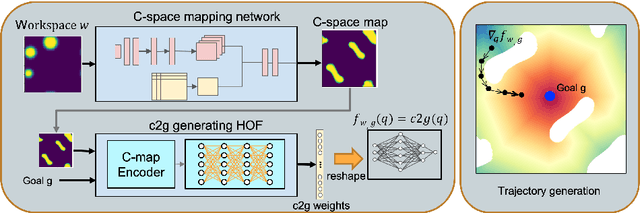



Traditional motion planning is computationally burdensome for practical robots, involving extensive collision checking and considerable iterative propagation of cost values. We present a novel neural network architecture which can directly generate the cost-to-go (c2g) function for a given configuration space and a goal configuration. The output of the network is a continuous function whose gradient in configuration space can be directly used to generate trajectories in motion planning without the need for protracted iterations or extensive collision checking. This higher order function (i.e. a function generating another function) representation lies at the core of our motion planning architecture, c2g-HOF, which can take a workspace as input, and generate the cost-to-go function over the configuration space map (C-map). Simulation results for 2D and 3D environments show that c2g-HOF can be orders of magnitude faster at execution time than methods which explore the configuration space during execution. We also present an implementation of c2g-HOF which generates trajectories for robot manipulators directly from an overhead image of the workspace.
Pixels to Plans: Learning Non-Prehensile Manipulation by Imitating a Planner
Apr 05, 2019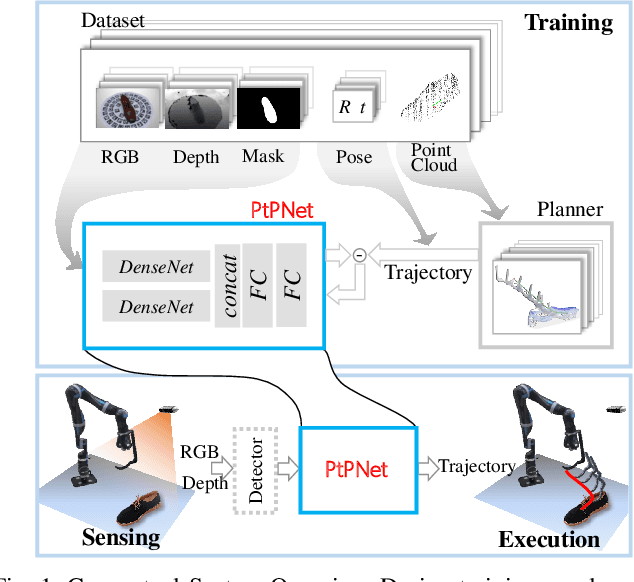
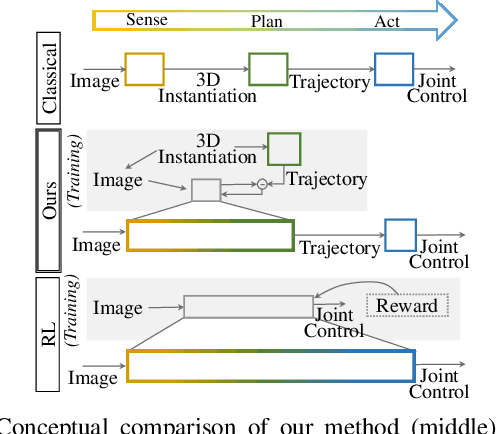
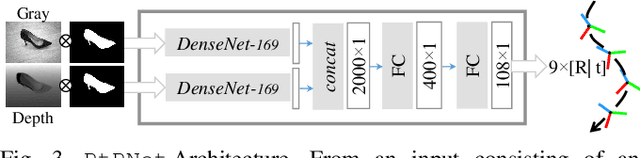
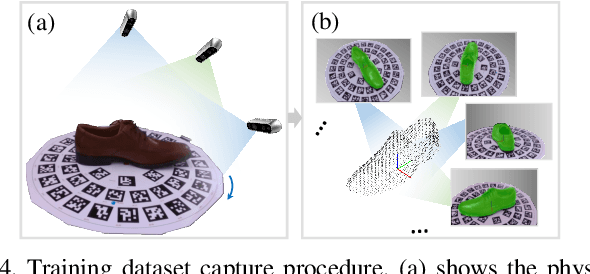
We present a novel method enabling robots to quickly learn to manipulate objects by leveraging a motion planner to generate "expert" training trajectories from a small amount of human-labeled data. In contrast to the traditional sense-plan-act cycle, we propose a deep learning architecture and training regimen called PtPNet that can estimate effective end-effector trajectories for manipulation directly from a single RGB-D image of an object. Additionally, we present a data collection and augmentation pipeline that enables the automatic generation of large numbers (millions) of training image and trajectory examples with almost no human labeling effort. We demonstrate our approach in a non-prehensile tool-based manipulation task, specifically picking up shoes with a hook. In hardware experiments, PtPNet generates motion plans (open-loop trajectories) that reliably (89% success over 189 trials) pick up four very different shoes from a range of positions and orientations, and reliably picks up a shoe it has never seen before. Compared with a traditional sense-plan-act paradigm, our system has the advantages of operating on sparse information (single RGB-D frame), producing high-quality trajectories much faster than the "expert" planner (300ms versus several seconds), and generalizing effectively to previously unseen shoes.