 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineControlNet: Fine-level Text Control for Image Generation with Spatially Aligned Text Control Injection
Dec 14, 2023Recently introduced ControlNet has the ability to steer the text-driven image generation process with geometric input such as human 2D pose, or edge features. While ControlNet provides control over the geometric form of the instances in the generated image, it lacks the capability to dictate the visual appearance of each instance. We present FineControlNet to provide fine control over each instance's appearance while maintaining the precise pose control capability. Specifically, we develop and demonstrate FineControlNet with geometric control via human pose images and appearance control via instance-level text prompts. The spatial alignment of instance-specific text prompts and 2D poses in latent space enables the fine control capabilities of FineControlNet. We evaluate the performance of FineControlNet with rigorous comparison against state-of-the-art pose-conditioned text-to-image diffusion models. FineControlNet achieves superior performance in generating images that follow the user-provided instance-specific text prompts and poses compared with existing methods. Project webpage: https://samsunglabs.github.io/FineControlNet-project-page
RICo: Rotate-Inpaint-Complete for Generalizable Scene Reconstruction
Jul 21, 2023
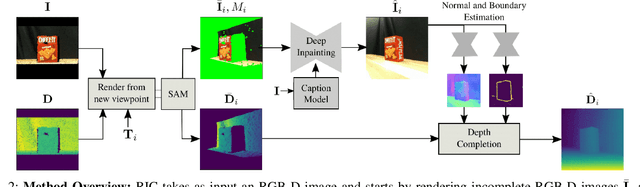
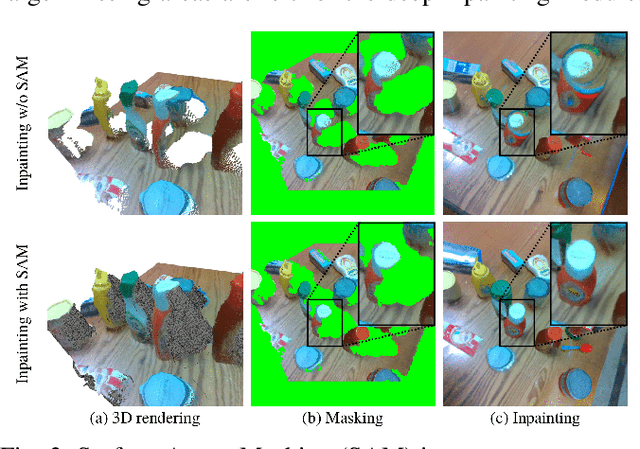
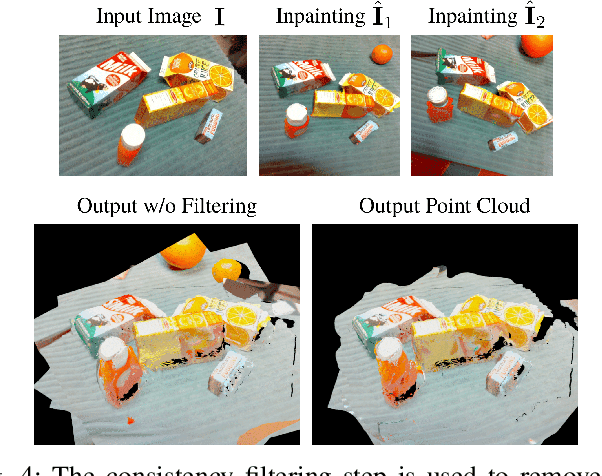
General scene reconstruction refers to the task of estimating the full 3D geometry and texture of a scene containing previously unseen objects. In many practical applications such as AR/VR, autonomous navigation, and robotics, only a single view of the scene may be available, making the scene reconstruction a very challenging task. In this paper, we present a method for scene reconstruction by structurally breaking the problem into two steps: rendering novel views via inpainting and 2D to 3D scene lifting. Specifically, we leverage the generalization capability of large language models to inpaint the missing areas of scene color images rendered from different views. Next, we lift these inpainted images to 3D by predicting normals of the inpainted image and solving for the missing depth values. By predicting for normals instead of depth directly, our method allows for robustness to changes in depth distributions and scale. With rigorous quantitative evaluation, we show that our method outperforms multiple baselines while providing generalization to novel objects and scenes.
Real-time Simultaneous Multi-Object 3D Shape Reconstruction, 6DoF Pose Estimation and Dense Grasp Prediction
May 16, 2023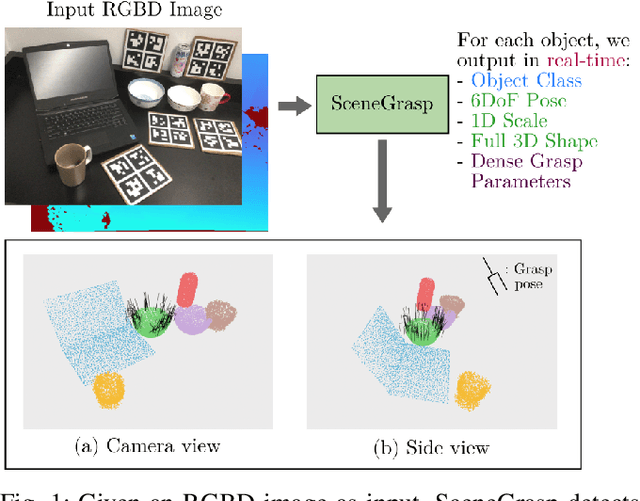
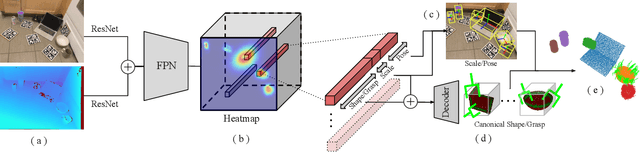
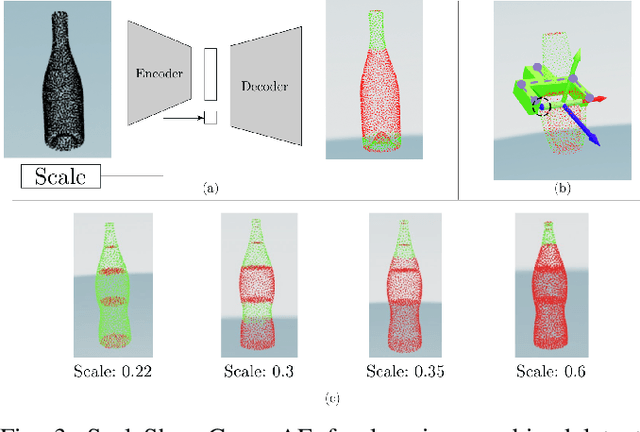
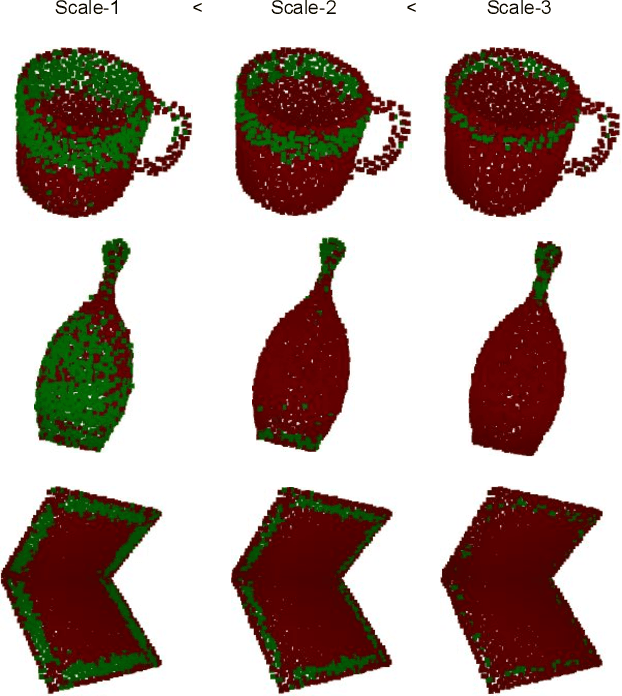
Robotic manipulation systems operating in complex environments rely on perception systems that provide information about the geometry (pose and 3D shape) of the objects in the scene along with other semantic information such as object labels. This information is then used for choosing the feasible grasps on relevant objects. In this paper, we present a novel method to provide this geometric and semantic information of all objects in the scene as well as feasible grasps on those objects simultaneously. The main advantage of our method is its speed as it avoids sequential perception and grasp planning steps. With detailed quantitative analysis, we show that our method delivers competitive performance compared to the state-of-the-art dedicated methods for object shape, pose, and grasp predictions while providing fast inference at 30 frames per second speed.