 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRICo: Rotate-Inpaint-Complete for Generalizable Scene Reconstruction
Paper and Code
Jul 21, 2023
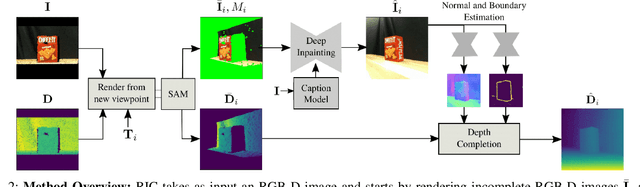
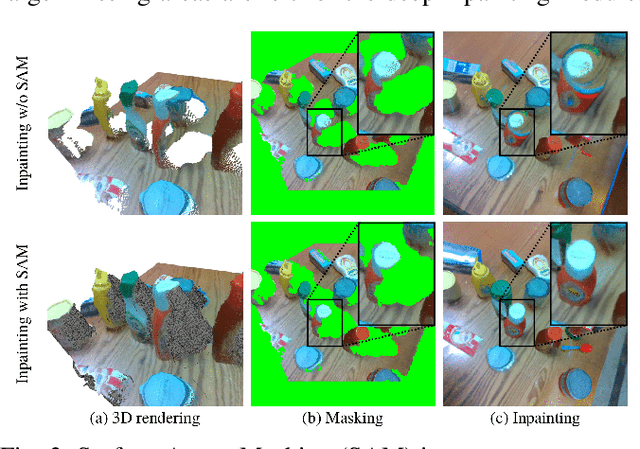
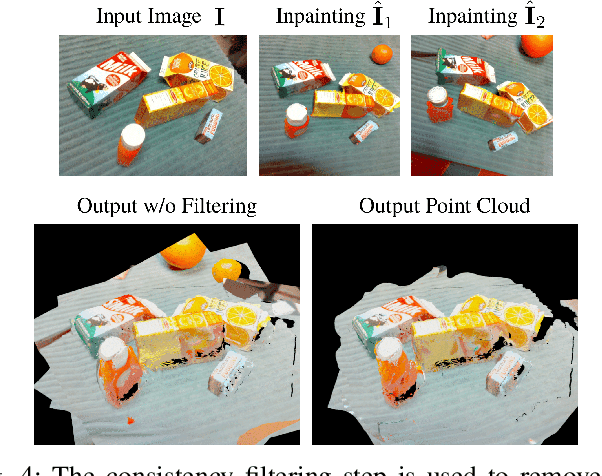
General scene reconstruction refers to the task of estimating the full 3D geometry and texture of a scene containing previously unseen objects. In many practical applications such as AR/VR, autonomous navigation, and robotics, only a single view of the scene may be available, making the scene reconstruction a very challenging task. In this paper, we present a method for scene reconstruction by structurally breaking the problem into two steps: rendering novel views via inpainting and 2D to 3D scene lifting. Specifically, we leverage the generalization capability of large language models to inpaint the missing areas of scene color images rendered from different views. Next, we lift these inpainted images to 3D by predicting normals of the inpainted image and solving for the missing depth values. By predicting for normals instead of depth directly, our method allows for robustness to changes in depth distributions and scale. With rigorous quantitative evaluation, we show that our method outperforms multiple baselines while providing generalization to novel objects and scenes.