 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHIO-SDF: Hierarchical Incremental Online Signed Distance Fields
Oct 14, 2023



A good representation of a large, complex mobile robot workspace must be space-efficient yet capable of encoding relevant geometric details. When exploring unknown environments, it needs to be updatable incrementally in an online fashion. We introduce HIO-SDF, a new method that represents the environment as a Signed Distance Field (SDF). State of the art representations of SDFs are based on either neural networks or voxel grids. Neural networks are capable of representing the SDF continuously. However, they are hard to update incrementally as neural networks tend to forget previously observed parts of the environment unless an extensive sensor history is stored for training. Voxel-based representations do not have this problem but they are not space-efficient especially in large environments with fine details. HIO-SDF combines the advantages of these representations using a hierarchical approach which employs a coarse voxel grid that captures the observed parts of the environment together with high-resolution local information to train a neural network. HIO-SDF achieves a 46% lower mean global SDF error across all test scenes than a state of the art continuous representation, and a 30% lower error than a discrete representation at the same resolution as our coarse global SDF grid.
RAMP: Hierarchical Reactive Motion Planning for Manipulation Tasks Using Implicit Signed Distance Functions
May 17, 2023
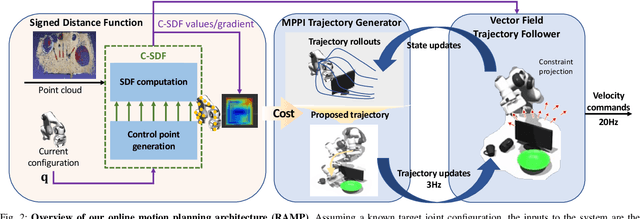
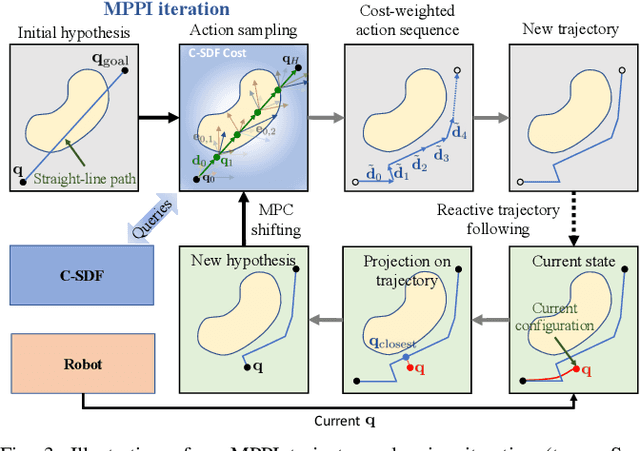
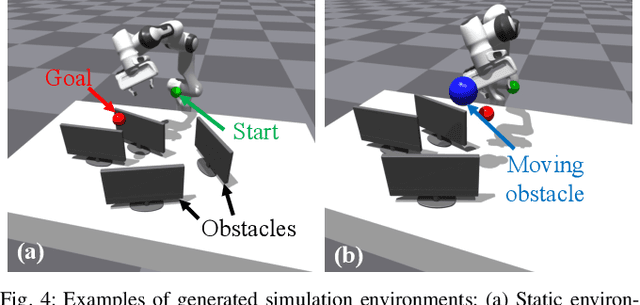
We introduce Reactive Action and Motion Planner (RAMP), which combines the strengths of search-based and reactive approaches for motion planning. In essence, RAMP is a hierarchical approach where a novel variant of a Model Predictive Path Integral (MPPI) controller is used to generate trajectories which are then followed asynchronously by a local vector field controller. We demonstrate, in the context of a table clearing application, that RAMP can rapidly find paths in the robot's configuration space, satisfy task and robot-specific constraints, and provide safety by reacting to static or dynamically moving obstacles. RAMP achieves superior performance through a number of key innovations: we use Signed Distance Function (SDF) representations directly from the robot configuration space, both for collision checking and reactive control. The use of SDFs allows for a smoother definition of collision cost when planning for a trajectory, and is critical in ensuring safety while following trajectories. In addition, we introduce a novel variant of MPPI which, combined with the safety guarantees of the vector field trajectory follower, performs incremental real-time global trajectory planning. Simulation results establish that our method can generate paths that are comparable to traditional and state-of-the-art approaches in terms of total trajectory length while being up to 30 times faster. Real-world experiments demonstrate the safety and effectiveness of our approach in challenging table clearing scenarios.
Self-supervised Wide Baseline Visual Servoing via 3D Equivariance
Sep 12, 2022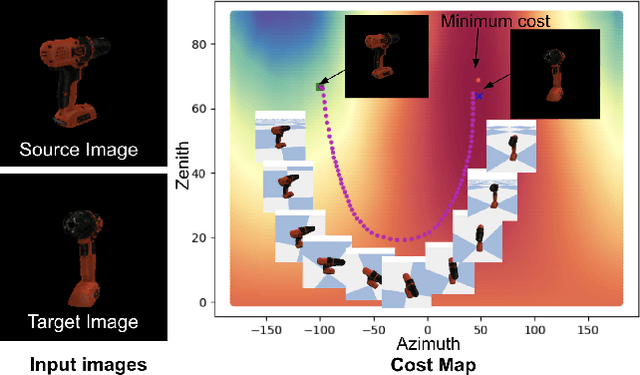
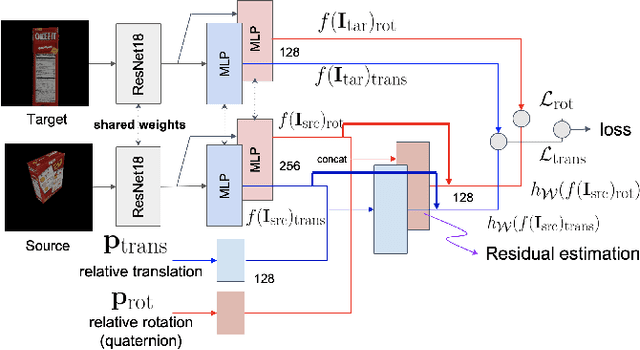
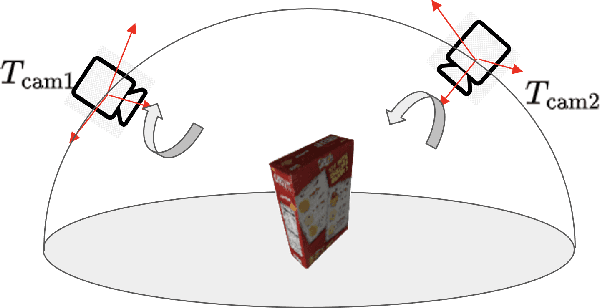

One of the challenging input settings for visual servoing is when the initial and goal camera views are far apart. Such settings are difficult because the wide baseline can cause drastic changes in object appearance and cause occlusions. This paper presents a novel self-supervised visual servoing method for wide baseline images which does not require 3D ground truth supervision. Existing approaches that regress absolute camera pose with respect to an object require 3D ground truth data of the object in the forms of 3D bounding boxes or meshes. We learn a coherent visual representation by leveraging a geometric property called 3D equivariance-the representation is transformed in a predictable way as a function of 3D transformation. To ensure that the feature-space is faithful to the underlying geodesic space, a geodesic preserving constraint is applied in conjunction with the equivariance. We design a Siamese network that can effectively enforce these two geometric properties without requiring 3D supervision. With the learned model, the relative transformation can be inferred simply by following the gradient in the learned space and used as feedback for closed-loop visual servoing. Our method is evaluated on objects from the YCB dataset, showing meaningful outperformance on a visual servoing task, or object alignment task with respect to state-of-the-art approaches that use 3D supervision. Ours yields more than 35% average distance error reduction and more than 90% success rate with 3cm error tolerance.
Feasibility and Acceptability of Remote Neuromotor Rehabilitation Interactions Using Social Robot Augmented Telepresence: A Case Study
Feb 27, 2022



There is a growing need to deliver rehabilitation care to patients remotely. Long term demographic changes, geographic shortages of care providers, and now a global pandemic contribute to this need. Telepresence provides an option for delivering this care. However, telepresence using video and audio alone does not provide an interaction of the same quality as in-person. To bridge this gap, we propose the use of social robot augmented telepresence (SRAT). We have constructed a demonstration SRAT system for upper extremity rehab, in which a humanoid, with a head, body, face, and arms, is attached to a mobile telepresence system, to collaborate with the patient and clinicians as an independent social entity. The humanoid can play games with the patient and demonstrate activities.These activities could be used both to perform assessments in support of self-directed rehab and to perform exercises. In this paper, we present a case series with six subjects who completed interactions with the robot, three subjects who have previously suffered a stroke and three pediatric subjects who are typically developing. Subjects performed a Simon Says activity and a target touch activity in person, using classical telepresence (CT), and using SRAT. Subjects were able to effectively work with the social robot guiding interactions and 5 of 6 rated SRAT better than CT. This study demonstrates the feasibility of SRAT and some of its benefits.