 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Wide Baseline Visual Servoing via 3D Equivariance
Paper and Code
Sep 12, 2022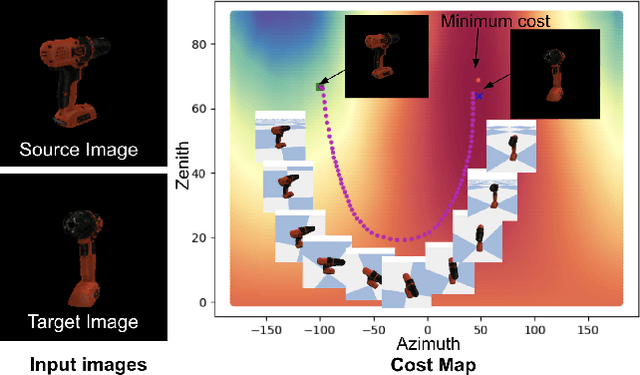
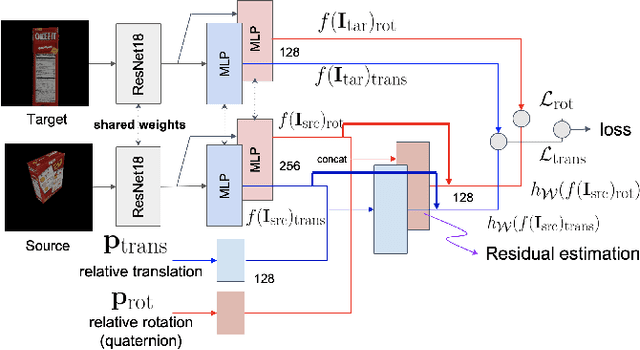
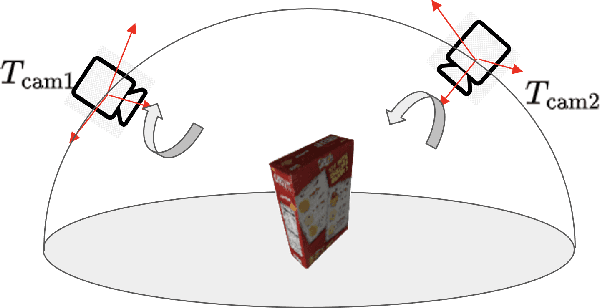

One of the challenging input settings for visual servoing is when the initial and goal camera views are far apart. Such settings are difficult because the wide baseline can cause drastic changes in object appearance and cause occlusions. This paper presents a novel self-supervised visual servoing method for wide baseline images which does not require 3D ground truth supervision. Existing approaches that regress absolute camera pose with respect to an object require 3D ground truth data of the object in the forms of 3D bounding boxes or meshes. We learn a coherent visual representation by leveraging a geometric property called 3D equivariance-the representation is transformed in a predictable way as a function of 3D transformation. To ensure that the feature-space is faithful to the underlying geodesic space, a geodesic preserving constraint is applied in conjunction with the equivariance. We design a Siamese network that can effectively enforce these two geometric properties without requiring 3D supervision. With the learned model, the relative transformation can be inferred simply by following the gradient in the learned space and used as feedback for closed-loop visual servoing. Our method is evaluated on objects from the YCB dataset, showing meaningful outperformance on a visual servoing task, or object alignment task with respect to state-of-the-art approaches that use 3D supervision. Ours yields more than 35% average distance error reduction and more than 90% success rate with 3cm error tolerance.