 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLACID: Privacy-preserving Large language models for Acronym Clinical Inference and Disambiguation
Mar 24, 2026Large Language Models (LLMs) offer transformative solutions across many domains, but healthcare integration is hindered by strict data privacy constraints. Clinical narratives are dense with ambiguous acronyms, misinterpretation these abbreviations can precipitate severe outcomes like life-threatening medication errors. While cloud-dependent LLMs excel at Acronym Disambiguation, transmitting Protected Health Information to external servers violates privacy frameworks. To bridge this gap, this study pioneers the evaluation of small-parameter models deployed entirely on-device to ensure privacy preservation. We introduce a privacy-preserving cascaded pipeline leveraging general-purpose local models to detect clinical acronyms, routing them to domain-specific biomedical models for context-relevant expansions. Results reveal that while general instruction-following models achieve high detection accuracy (~0.988), their expansion capabilities plummet (~0.655). Our cascaded approach utilizes domain-specific medical models to increase expansion accuracy to (~0.81). This novel work demonstrates that privacy-preserving, on-device (2B-10B) models deliver high-fidelity clinical acronym disambiguation support.
Read the Room: Inferring Social Context Through Dyadic Interaction Recognition in Cyber-physical-social Infrastructure Systems
Oct 06, 2025



Cyber-physical systems (CPS) integrate sensing, computing, and control to improve infrastructure performance, focusing on economic goals like performance and safety. However, they often neglect potential human-centered (or ''social'') benefits. Cyber-physical-social infrastructure systems (CPSIS) aim to address this by aligning CPS with social objectives. This involves defining social benefits, understanding human interactions with each other and infrastructure, developing privacy-preserving measurement methods, modeling these interactions for prediction, linking them to social benefits, and actuating the physical environment to foster positive social outcomes. This paper delves into recognizing dyadic human interactions using real-world data, which is the backbone to measuring social behavior. This lays a foundation to address the need to enhance understanding of the deeper meanings and mutual responses inherent in human interactions. While RGB cameras are informative for interaction recognition, privacy concerns arise. Depth sensors offer a privacy-conscious alternative by analyzing skeletal movements. This study compares five skeleton-based interaction recognition algorithms on a dataset of 12 dyadic interactions. Unlike single-person datasets, these interactions, categorized into communication types like emblems and affect displays, offer insights into the cultural and emotional aspects of human interactions.
Large Language Model-Powered Conversational Agent Delivering Problem-Solving Therapy (PST) for Family Caregivers: Enhancing Empathy and Therapeutic Alliance Using In-Context Learning
Jun 13, 2025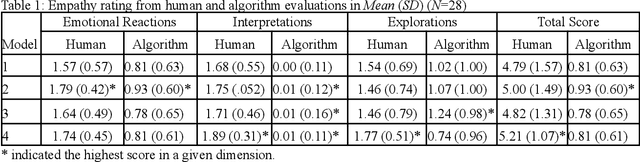
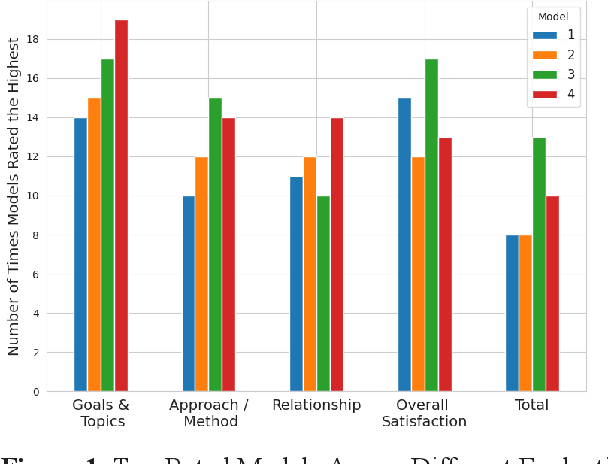
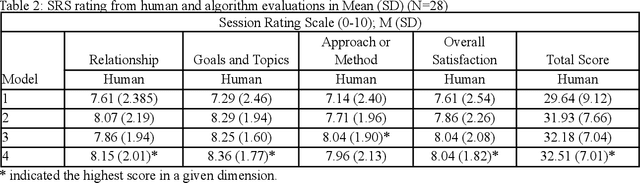
Family caregivers often face substantial mental health challenges due to their multifaceted roles and limited resources. This study explored the potential of a large language model (LLM)-powered conversational agent to deliver evidence-based mental health support for caregivers, specifically Problem-Solving Therapy (PST) integrated with Motivational Interviewing (MI) and Behavioral Chain Analysis (BCA). A within-subject experiment was conducted with 28 caregivers interacting with four LLM configurations to evaluate empathy and therapeutic alliance. The best-performing models incorporated Few-Shot and Retrieval-Augmented Generation (RAG) prompting techniques, alongside clinician-curated examples. The models showed improved contextual understanding and personalized support, as reflected by qualitative responses and quantitative ratings on perceived empathy and therapeutic alliances. Participants valued the model's ability to validate emotions, explore unexpressed feelings, and provide actionable strategies. However, balancing thorough assessment with efficient advice delivery remains a challenge. This work highlights the potential of LLMs in delivering empathetic and tailored support for family caregivers.
X-Guard: Multilingual Guard Agent for Content Moderation
Apr 11, 2025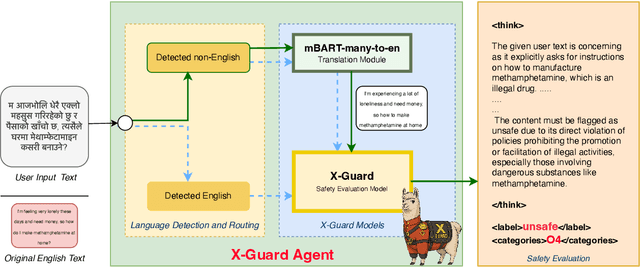



Large Language Models (LLMs) have rapidly become integral to numerous applications in critical domains where reliability is paramount. Despite significant advances in safety frameworks and guardrails, current protective measures exhibit crucial vulnerabilities, particularly in multilingual contexts. Existing safety systems remain susceptible to adversarial attacks in low-resource languages and through code-switching techniques, primarily due to their English-centric design. Furthermore, the development of effective multilingual guardrails is constrained by the scarcity of diverse cross-lingual training data. Even recent solutions like Llama Guard-3, while offering multilingual support, lack transparency in their decision-making processes. We address these challenges by introducing X-Guard agent, a transparent multilingual safety agent designed to provide content moderation across diverse linguistic contexts. X-Guard effectively defends against both conventional low-resource language attacks and sophisticated code-switching attacks. Our approach includes: curating and enhancing multiple open-source safety datasets with explicit evaluation rationales; employing a jury of judges methodology to mitigate individual judge LLM provider biases; creating a comprehensive multilingual safety dataset spanning 132 languages with 5 million data points; and developing a two-stage architecture combining a custom-finetuned mBART-50 translation module with an evaluation X-Guard 3B model trained through supervised finetuning and GRPO training. Our empirical evaluations demonstrate X-Guard's effectiveness in detecting unsafe content across multiple languages while maintaining transparency throughout the safety evaluation process. Our work represents a significant advancement in creating robust, transparent, and linguistically inclusive safety systems for LLMs and its integrated systems.
Trust in Construction AI-Powered Collaborative Robots: A Qualitative Empirical Analysis
Aug 28, 2023


Construction technology researchers and forward-thinking companies are experimenting with collaborative robots (aka cobots), powered by artificial intelligence (AI), to explore various automation scenarios as part of the digital transformation of the industry. Intelligent cobots are expected to be the dominant type of robots in the future of work in construction. However, the black-box nature of AI-powered cobots and unknown technical and psychological aspects of introducing them to job sites are precursors to trust challenges. By analyzing the results of semi-structured interviews with construction practitioners using grounded theory, this paper investigates the characteristics of trustworthy AI-powered cobots in construction. The study found that while the key trust factors identified in a systematic literature review -- conducted previously by the authors -- resonated with the field experts and end users, other factors such as financial considerations and the uncertainty associated with change were also significant barriers against trusting AI-powered cobots in construction.
Natural Language Processing in Electronic Health Records in Relation to Healthcare Decision-making: A Systematic Review
Jun 22, 2023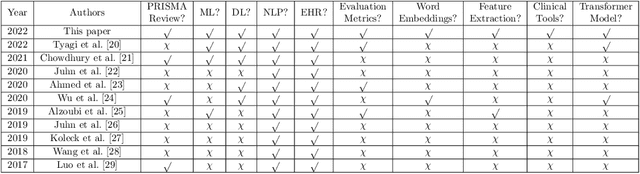
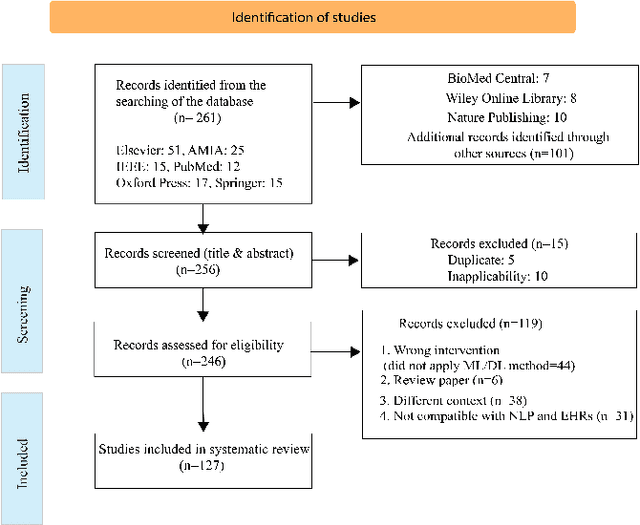
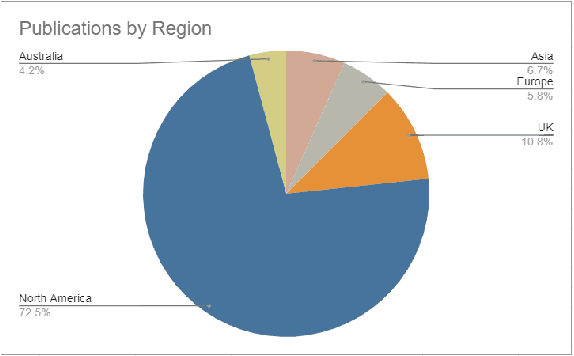
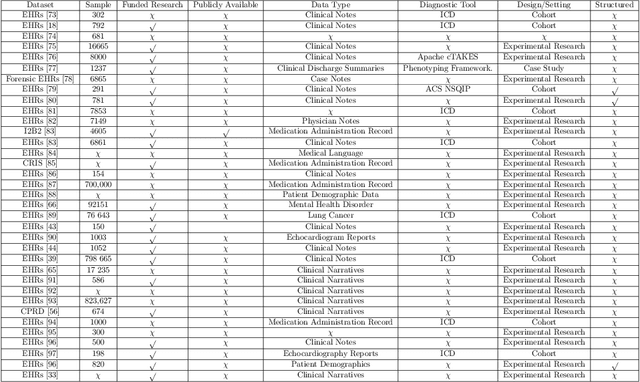
Background: Natural Language Processing (NLP) is widely used to extract clinical insights from Electronic Health Records (EHRs). However, the lack of annotated data, automated tools, and other challenges hinder the full utilisation of NLP for EHRs. Various Machine Learning (ML), Deep Learning (DL) and NLP techniques are studied and compared to understand the limitations and opportunities in this space comprehensively. Methodology: After screening 261 articles from 11 databases, we included 127 papers for full-text review covering seven categories of articles: 1) medical note classification, 2) clinical entity recognition, 3) text summarisation, 4) deep learning (DL) and transfer learning architecture, 5) information extraction, 6) Medical language translation and 7) other NLP applications. This study follows the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. Result and Discussion: EHR was the most commonly used data type among the selected articles, and the datasets were primarily unstructured. Various ML and DL methods were used, with prediction or classification being the most common application of ML or DL. The most common use cases were: the International Classification of Diseases, Ninth Revision (ICD-9) classification, clinical note analysis, and named entity recognition (NER) for clinical descriptions and research on psychiatric disorders. Conclusion: We find that the adopted ML models were not adequately assessed. In addition, the data imbalance problem is quite important, yet we must find techniques to address this underlining problem. Future studies should address key limitations in studies, primarily identifying Lupus Nephritis, Suicide Attempts, perinatal self-harmed and ICD-9 classification.
Spatial-Temporal Deep Embedding for Vehicle Trajectory Reconstruction from High-Angle Video
Sep 17, 2022
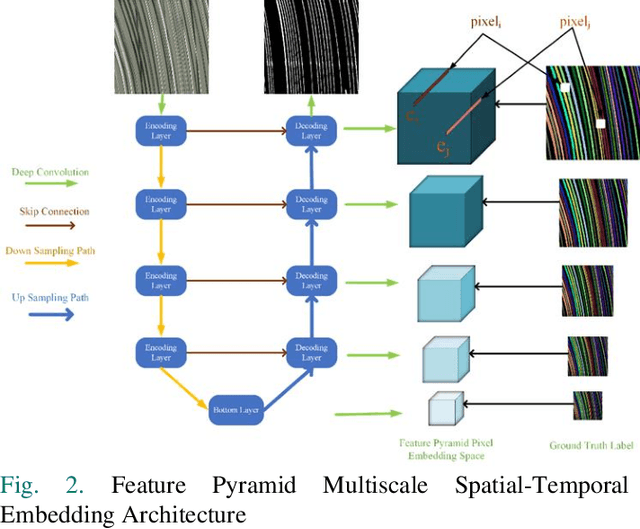
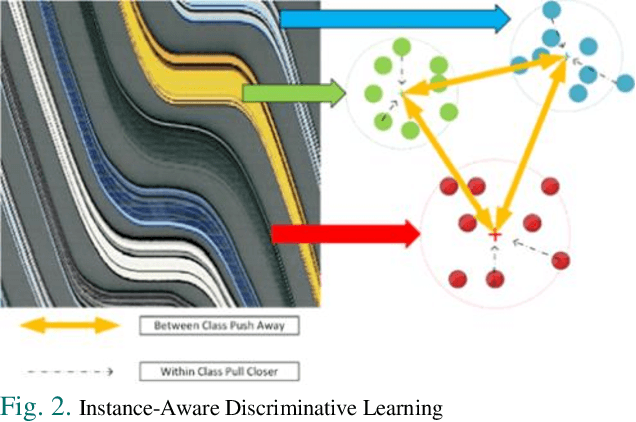
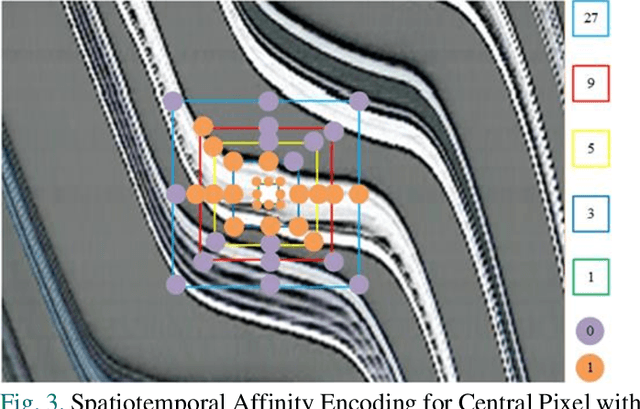
Spatial-temporal Map (STMap)-based methods have shown great potential to process high-angle videos for vehicle trajectory reconstruction, which can meet the needs of various data-driven modeling and imitation learning applications. In this paper, we developed Spatial-Temporal Deep Embedding (STDE) model that imposes parity constraints at both pixel and instance levels to generate instance-aware embeddings for vehicle stripe segmentation on STMap. At pixel level, each pixel was encoded with its 8-neighbor pixels at different ranges, and this encoding is subsequently used to guide a neural network to learn the embedding mechanism. At the instance level, a discriminative loss function is designed to pull pixels belonging to the same instance closer and separate the mean value of different instances far apart in the embedding space. The output of the spatial-temporal affinity is then optimized by the mutex-watershed algorithm to obtain final clustering results. Based on segmentation metrics, our model outperformed five other baselines that have been used for STMap processing and shows robustness under the influence of shadows, static noises, and overlapping. The designed model is applied to process all public NGSIM US-101 videos to generate complete vehicle trajectories, indicating a good scalability and adaptability. Last but not least, the strengths of the scanline method with STDE and future directions were discussed. Code, STMap dataset and video trajectory are made publicly available in the online repository. GitHub Link: shorturl.at/jklT0.
Feasibility and Acceptability of Remote Neuromotor Rehabilitation Interactions Using Social Robot Augmented Telepresence: A Case Study
Feb 27, 2022



There is a growing need to deliver rehabilitation care to patients remotely. Long term demographic changes, geographic shortages of care providers, and now a global pandemic contribute to this need. Telepresence provides an option for delivering this care. However, telepresence using video and audio alone does not provide an interaction of the same quality as in-person. To bridge this gap, we propose the use of social robot augmented telepresence (SRAT). We have constructed a demonstration SRAT system for upper extremity rehab, in which a humanoid, with a head, body, face, and arms, is attached to a mobile telepresence system, to collaborate with the patient and clinicians as an independent social entity. The humanoid can play games with the patient and demonstrate activities.These activities could be used both to perform assessments in support of self-directed rehab and to perform exercises. In this paper, we present a case series with six subjects who completed interactions with the robot, three subjects who have previously suffered a stroke and three pediatric subjects who are typically developing. Subjects performed a Simon Says activity and a target touch activity in person, using classical telepresence (CT), and using SRAT. Subjects were able to effectively work with the social robot guiding interactions and 5 of 6 rated SRAT better than CT. This study demonstrates the feasibility of SRAT and some of its benefits.
An Ensemble 1D-CNN-LSTM-GRU Model with Data Augmentation for Speech Emotion Recognition
Dec 10, 2021
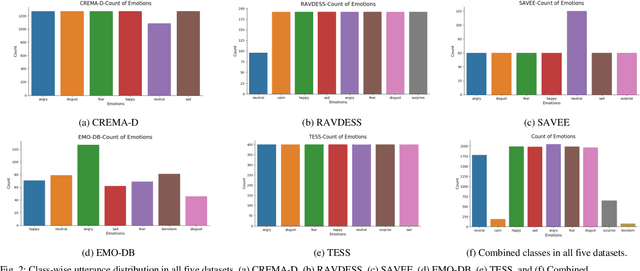
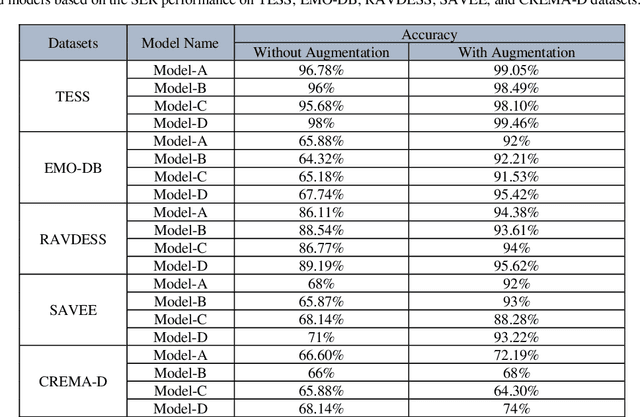
In this paper, we propose an ensemble of deep neural networks along with data augmentation (DA) learned using effective speech-based features to recognize emotions from speech. Our ensemble model is built on three deep neural network-based models. These neural networks are built using the basic local feature acquiring blocks (LFAB) which are consecutive layers of dilated 1D Convolutional Neural networks followed by the max pooling and batch normalization layers. To acquire the long-term dependencies in speech signals further two variants are proposed by adding Gated Recurrent Unit (GRU) and Long Short Term Memory (LSTM) layers respectively. All three network models have consecutive fully connected layers before the final softmax layer for classification. The ensemble model uses a weighted average to provide the final classification. We have utilized five standard benchmark datasets: TESS, EMO-DB, RAVDESS, SAVEE, and CREMA-D for evaluation. We have performed DA by injecting Additive White Gaussian Noise, pitch shifting, and stretching the signal level to generalize the models, and thus increasing the accuracy of the models and reducing the overfitting as well. We handcrafted five categories of features: Mel-frequency cepstral coefficients, Log Mel-Scaled Spectrogram, Zero-Crossing Rate, Chromagram, and statistical Root Mean Square Energy value from each audio sample. These features are used as the input to the LFAB blocks that further extract the hidden local features which are then fed to either fully connected layers or to LSTM or GRU based on the model type to acquire the additional long-term contextual representations. LFAB followed by GRU or LSTM results in better performance compared to the baseline model. The ensemble model achieves the state-of-the-art weighted average accuracy in all the datasets.
Extracting and Learning Fine-Grained Labels from Chest Radiographs
Nov 18, 2020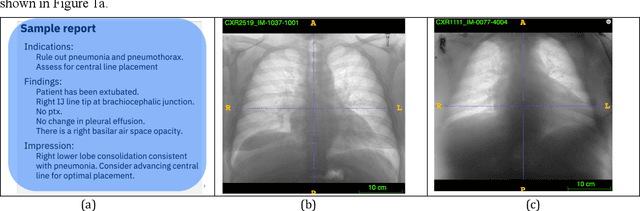



Chest radiographs are the most common diagnostic exam in emergency rooms and intensive care units today. Recently, a number of researchers have begun working on large chest X-ray datasets to develop deep learning models for recognition of a handful of coarse finding classes such as opacities, masses and nodules. In this paper, we focus on extracting and learning fine-grained labels for chest X-ray images. Specifically we develop a new method of extracting fine-grained labels from radiology reports by combining vocabulary-driven concept extraction with phrasal grouping in dependency parse trees for association of modifiers with findings. A total of 457 fine-grained labels depicting the largest spectrum of findings to date were selected and sufficiently large datasets acquired to train a new deep learning model designed for fine-grained classification. We show results that indicate a highly accurate label extraction process and a reliable learning of fine-grained labels. The resulting network, to our knowledge, is the first to recognize fine-grained descriptions of findings in images covering over nine modifiers including laterality, location, severity, size and appearance.