 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Speech Emotion Recognition with Efficient Channel Attention Guided Deep CNN-BiLSTM Framework
Dec 13, 2024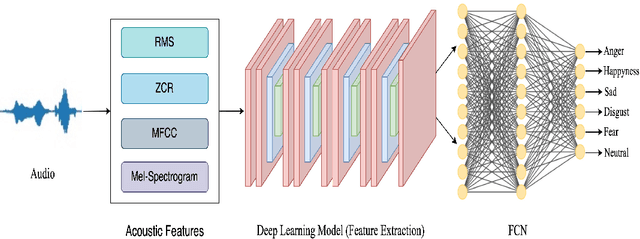
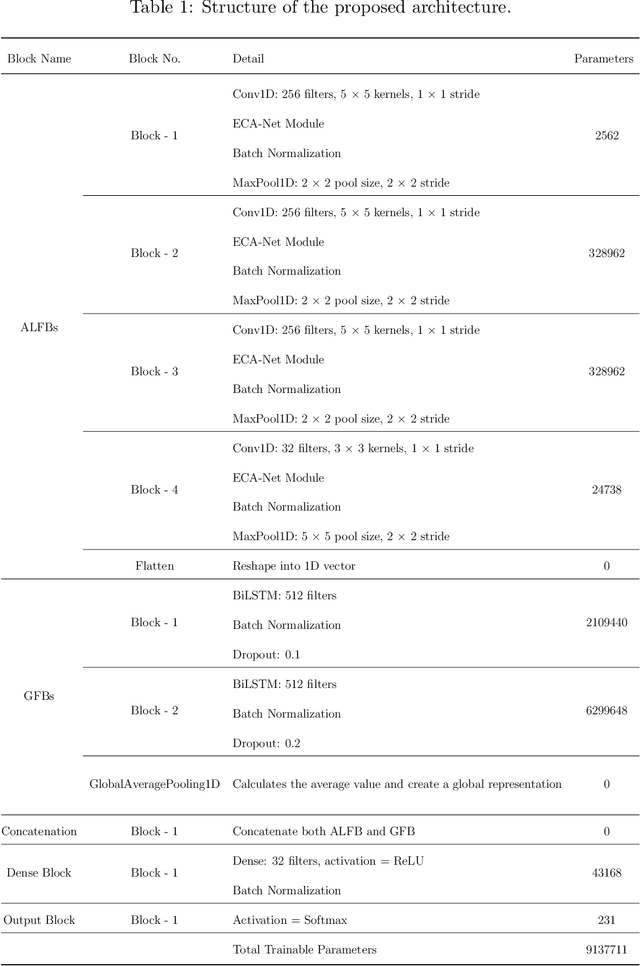
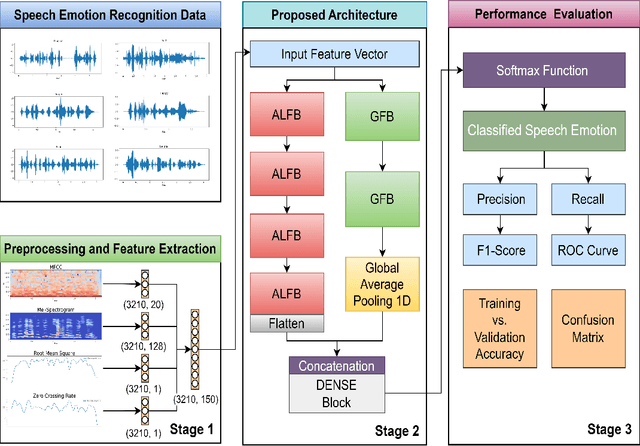
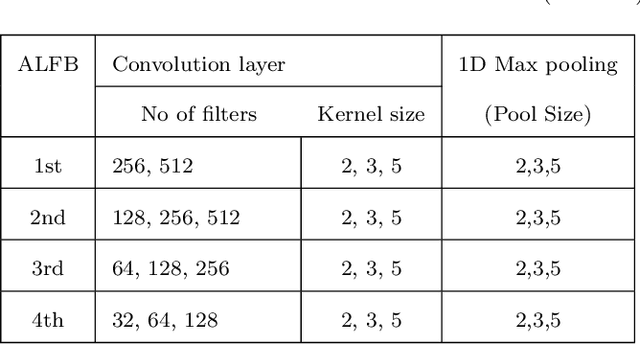
Speech emotion recognition (SER) is crucial for enhancing affective computing and enriching the domain of human-computer interaction. However, the main challenge in SER lies in selecting relevant feature representations from speech signals with lower computational costs. In this paper, we propose a lightweight SER architecture that integrates attention-based local feature blocks (ALFBs) to capture high-level relevant feature vectors from speech signals. We also incorporate a global feature block (GFB) technique to capture sequential, global information and long-term dependencies in speech signals. By aggregating attention-based local and global contextual feature vectors, our model effectively captures the internal correlation between salient features that reflect complex human emotional cues. To evaluate our approach, we extracted four types of spectral features from speech audio samples: mel-frequency cepstral coefficients, mel-spectrogram, root mean square value, and zero-crossing rate. Through a 5-fold cross-validation strategy, we tested the proposed method on five multi-lingual standard benchmark datasets: TESS, RAVDESS, BanglaSER, SUBESCO, and Emo-DB, and obtained a mean accuracy of 99.65%, 94.88%, 98.12%, 97.94%, and 97.19% respectively. The results indicate that our model achieves state-of-the-art (SOTA) performance compared to most existing methods.
MCFFA-Net: Multi-Contextual Feature Fusion and Attention Guided Network for Apple Foliar Disease Classification
Nov 25, 2022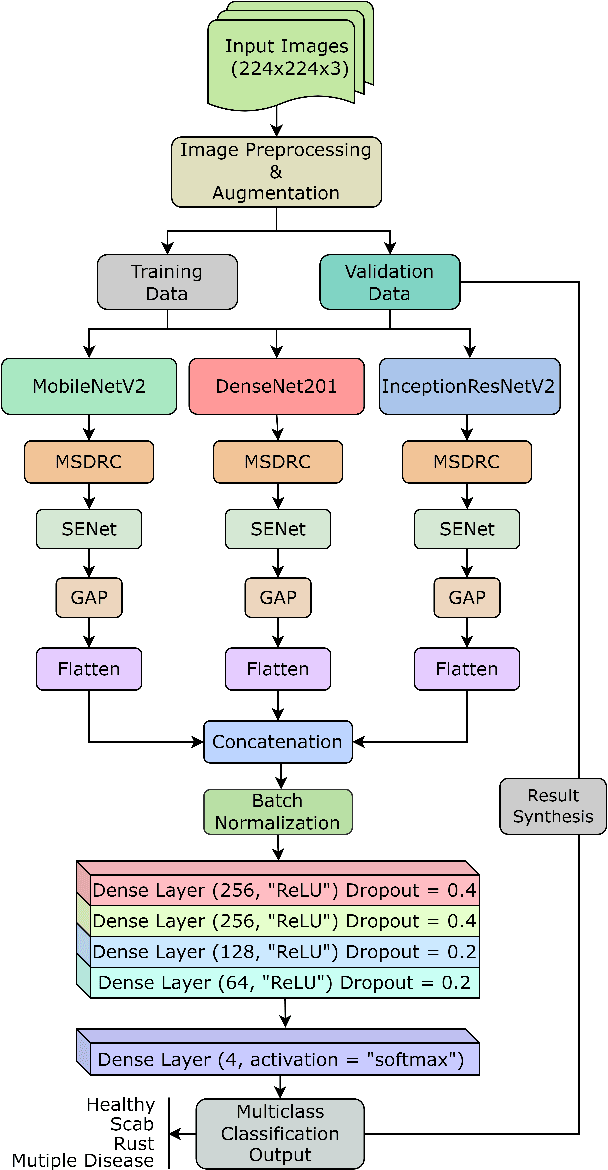
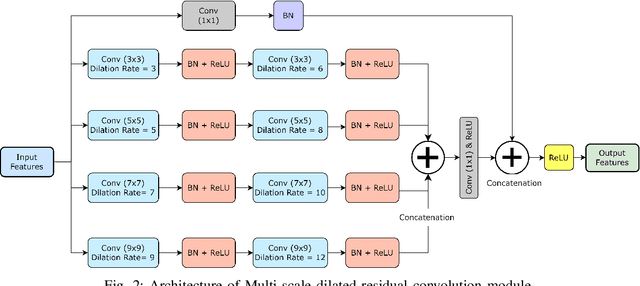
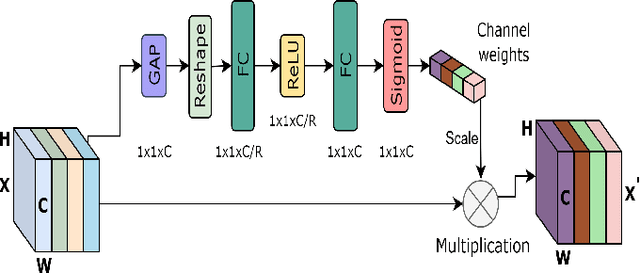
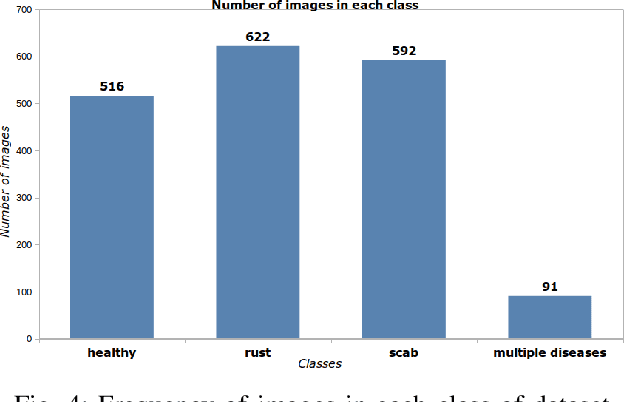
Numerous diseases cause severe economic loss in the apple production-based industry. Early disease identification in apple leaves can help to stop the spread of infections and provide better productivity. Therefore, it is crucial to study the identification and classification of different apple foliar diseases. Various traditional machine learning and deep learning methods have addressed and investigated this issue. However, it is still challenging to classify these diseases because of their complex background, variation in the diseased spot in the images, and the presence of several symptoms of multiple diseases on the same leaf. This paper proposes a novel transfer learning-based stacked ensemble architecture named MCFFA-Net, which is composed of three pre-trained architectures named MobileNetV2, DenseNet201, and InceptionResNetV2 as backbone networks. We also propose a novel multi-scale dilated residual convolution module to capture multi-scale contextual information with several dilated receptive fields from the extracted features. Channel-based attention mechanism is provided through squeeze and excitation networks to make the MCFFA-Net focused on the relevant information in the multi-receptive fields. The proposed MCFFA-Net achieves a classification accuracy of 90.86%.
DoubleU-NetPlus: A Novel Attention and Context Guided Dual U-Net with Multi-Scale Residual Feature Fusion Network for Semantic Segmentation of Medical Images
Nov 25, 2022Accurate segmentation of the region of interest in medical images can provide an essential pathway for devising effective treatment plans for life-threatening diseases. It is still challenging for U-Net, and its state-of-the-art variants, such as CE-Net and DoubleU-Net, to effectively model the higher-level output feature maps of the convolutional units of the network mostly due to the presence of various scales of the region of interest, intricacy of context environments, ambiguous boundaries, and multiformity of textures in medical images. In this paper, we exploit multi-contextual features and several attention strategies to increase networks' ability to model discriminative feature representation for more accurate medical image segmentation, and we present a novel dual U-Net-based architecture named DoubleU-NetPlus. The DoubleU-NetPlus incorporates several architectural modifications. In particular, we integrate EfficientNetB7 as the feature encoder module, a newly designed multi-kernel residual convolution module, and an adaptive feature re-calibrating attention-based atrous spatial pyramid pooling module to progressively and precisely accumulate discriminative multi-scale high-level contextual feature maps and emphasize the salient regions. In addition, we introduce a novel triple attention gate module and a hybrid triple attention module to encourage selective modeling of relevant medical image features. Moreover, to mitigate the gradient vanishing issue and incorporate high-resolution features with deeper spatial details, the standard convolution operation is replaced with the attention-guided residual convolution operations, ...
Classification of Human Monkeypox Disease Using Deep Learning Models and Attention Mechanisms
Nov 21, 2022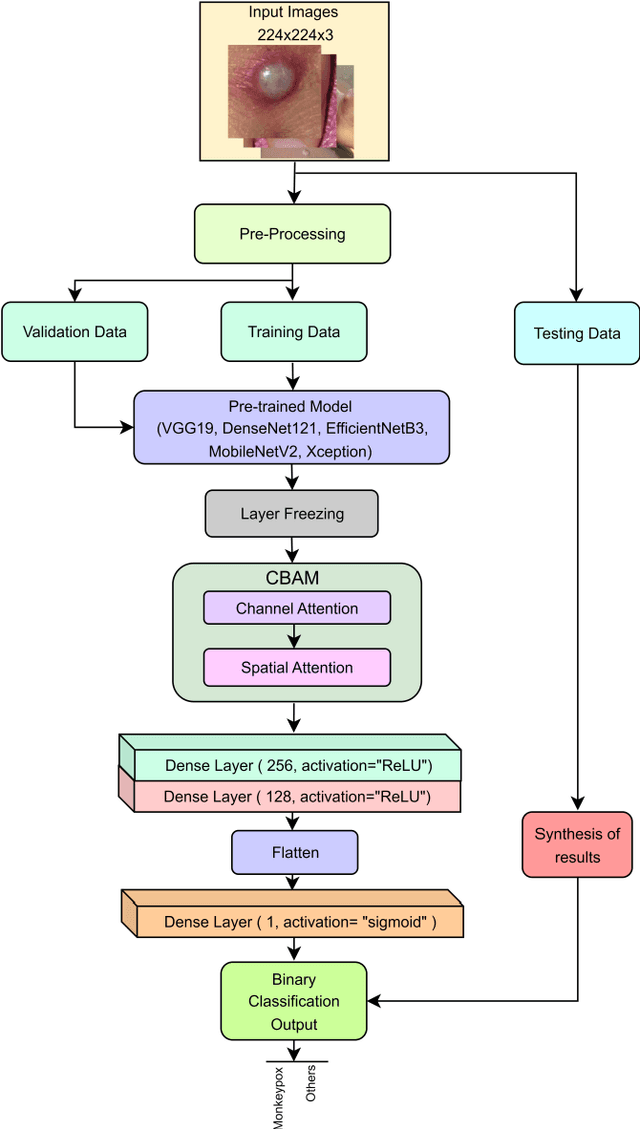
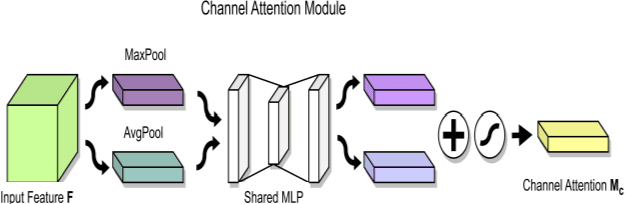
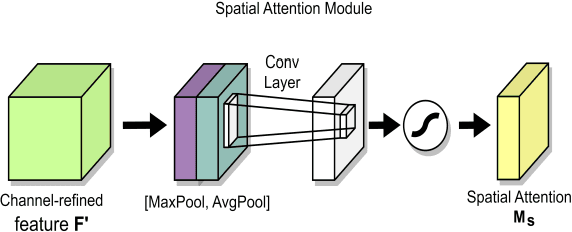
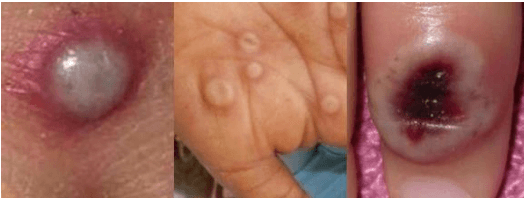
As the world is still trying to rebuild from the destruction caused by the widespread reach of the COVID-19 virus, and the recent alarming surge of human monkeypox disease outbreaks in numerous countries threatens to become a new global pandemic too. Human monkeypox disease syndromes are quite similar to chickenpox, and measles classic symptoms, with very intricate differences such as skin blisters, which come in diverse forms. Various deep-learning methods have shown promising performances in the image-based diagnosis of COVID-19, tumor cell, and skin disease classification tasks. In this paper, we try to integrate deep transfer-learning-based methods, along with a convolutional block attention module (CBAM), to focus on the relevant portion of the feature maps to conduct an image-based classification of human monkeypox disease. We implement five deep-learning models, VGG19, Xception, DenseNet121, EfficientNetB3, and MobileNetV2, along with integrated channel and spatial attention mechanisms, and perform a comparative analysis among them. An architecture consisting of Xception-CBAM-Dense layers performed better than the other models at classifying human monkeypox and other diseases with a validation accuracy of 83.89%.
An Ensemble 1D-CNN-LSTM-GRU Model with Data Augmentation for Speech Emotion Recognition
Dec 10, 2021
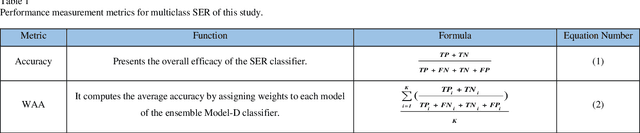
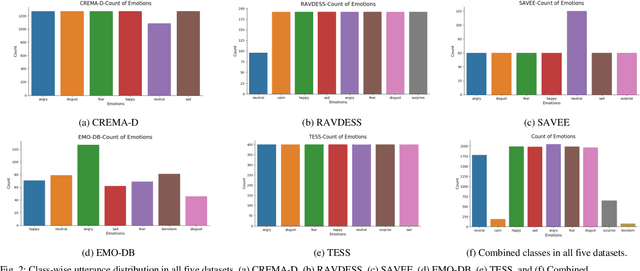
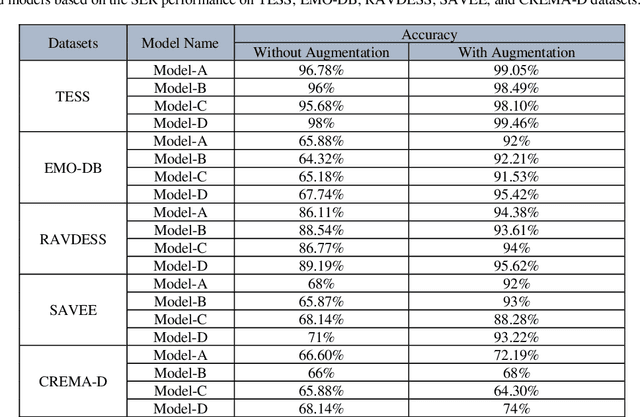
In this paper, we propose an ensemble of deep neural networks along with data augmentation (DA) learned using effective speech-based features to recognize emotions from speech. Our ensemble model is built on three deep neural network-based models. These neural networks are built using the basic local feature acquiring blocks (LFAB) which are consecutive layers of dilated 1D Convolutional Neural networks followed by the max pooling and batch normalization layers. To acquire the long-term dependencies in speech signals further two variants are proposed by adding Gated Recurrent Unit (GRU) and Long Short Term Memory (LSTM) layers respectively. All three network models have consecutive fully connected layers before the final softmax layer for classification. The ensemble model uses a weighted average to provide the final classification. We have utilized five standard benchmark datasets: TESS, EMO-DB, RAVDESS, SAVEE, and CREMA-D for evaluation. We have performed DA by injecting Additive White Gaussian Noise, pitch shifting, and stretching the signal level to generalize the models, and thus increasing the accuracy of the models and reducing the overfitting as well. We handcrafted five categories of features: Mel-frequency cepstral coefficients, Log Mel-Scaled Spectrogram, Zero-Crossing Rate, Chromagram, and statistical Root Mean Square Energy value from each audio sample. These features are used as the input to the LFAB blocks that further extract the hidden local features which are then fed to either fully connected layers or to LSTM or GRU based on the model type to acquire the additional long-term contextual representations. LFAB followed by GRU or LSTM results in better performance compared to the baseline model. The ensemble model achieves the state-of-the-art weighted average accuracy in all the datasets.