 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanglishRev: A Large-Scale Bangla-English and Code-mixed Dataset of Product Reviews in E-Commerce
Dec 17, 2024



This work presents the BanglishRev Dataset, the largest e-commerce product review dataset to date for reviews written in Bengali, English, a mixture of both and Banglish, Bengali words written with English alphabets. The dataset comprises of 1.74 million written reviews from 3.2 million ratings information collected from a total of 128k products being sold in online e-commerce platforms targeting the Bengali population. It includes an extensive array of related metadata for each of the reviews including the rating given by the reviewer, date the review was posted and date of purchase, number of likes, dislikes, response from the seller, images associated with the review etc. With sentiment analysis being the most prominent usage of review datasets, experimentation with a binary sentiment analysis model with the review rating serving as an indicator of positive or negative sentiment was conducted to evaluate the effectiveness of the large amount of data presented in BanglishRev for sentiment analysis tasks. A BanglishBERT model is trained on the data from BanglishRev with reviews being considered labeled positive if the rating is greater than 3 and negative if the rating is less than or equal to 3. The model is evaluated by being testing against a previously published manually annotated dataset for e-commerce reviews written in a mixture of Bangla, English and Banglish. The experimental model achieved an exceptional accuracy of 94\% and F1 score of 0.94, demonstrating the dataset's efficacy for sentiment analysis. Some of the intriguing patterns and observations seen within the dataset and future research directions where the dataset can be utilized is also discussed and explored. The dataset can be accessed through https://huggingface.co/datasets/BanglishRev/bangla-english-and-code-mixed-ecommerce-review-dataset.
Deep Transfer Learning Based Peer Review Aggregation and Meta-review Generation for Scientific Articles
Oct 05, 2024



Peer review is the quality assessment of a manuscript by one or more peer experts. Papers are submitted by the authors to scientific venues, and these papers must be reviewed by peers or other authors. The meta-reviewers then gather the peer reviews, assess them, and create a meta-review and decision for each manuscript. As the number of papers submitted to these venues has grown in recent years, it becomes increasingly challenging for meta-reviewers to collect these peer evaluations on time while still maintaining the quality that is the primary goal of meta-review creation. In this paper, we address two peer review aggregation challenges a meta-reviewer faces: paper acceptance decision-making and meta-review generation. Firstly, we propose to automate the process of acceptance decision prediction by applying traditional machine learning algorithms. We use pre-trained word embedding techniques BERT to process the reviews written in natural language text. For the meta-review generation, we propose a transfer learning model based on the T5 model. Experimental results show that BERT is more effective than the other word embedding techniques, and the recommendation score is an important feature for the acceptance decision prediction. In addition, we figure out that fine-tuned T5 outperforms other inference models. Our proposed system takes peer reviews and other relevant features as input to produce a meta-review and make a judgment on whether or not the paper should be accepted. In addition, experimental results show that the acceptance decision prediction system of our task outperforms the existing models, and the meta-review generation task shows significantly improved scores compared to the existing models. For the statistical test, we utilize the Wilcoxon signed-rank test to assess whether there is a statistically significant improvement between paired observations.
VoltaVision: A Transfer Learning model for electronic component classification
Apr 05, 2024



In this paper, we analyze the effectiveness of transfer learning on classifying electronic components. Transfer learning reuses pre-trained models to save time and resources in building a robust classifier rather than learning from scratch. Our work introduces a lightweight CNN, coined as VoltaVision, and compares its performance against more complex models. We test the hypothesis that transferring knowledge from a similar task to our target domain yields better results than state-of-the-art models trained on general datasets. Our dataset and code for this work are available at https://github.com/AnasIshfaque/VoltaVision.
An Artificial Intelligence-based Framework to Achieve the Sustainable Development Goals in the Context of Bangladesh
Apr 23, 2023



Sustainable development is a framework for achieving human development goals. It provides natural systems' ability to deliver natural resources and ecosystem services. Sustainable development is crucial for the economy and society. Artificial intelligence (AI) has attracted increasing attention in recent years, with the potential to have a positive influence across many domains. AI is a commonly employed component in the quest for long-term sustainability. In this study, we explore the impact of AI on three pillars of sustainable development: society, environment, and economy, as well as numerous case studies from which we may deduce the impact of AI in a variety of areas, i.e., agriculture, classifying waste, smart water management, and Heating, Ventilation, and Air Conditioning (HVAC) systems. Furthermore, we present AI-based strategies for achieving Sustainable Development Goals (SDGs) which are effective for developing countries like Bangladesh. The framework that we propose may reduce the negative impact of AI and promote the proactiveness of this technology.
DoubleU-NetPlus: A Novel Attention and Context Guided Dual U-Net with Multi-Scale Residual Feature Fusion Network for Semantic Segmentation of Medical Images
Nov 25, 2022Accurate segmentation of the region of interest in medical images can provide an essential pathway for devising effective treatment plans for life-threatening diseases. It is still challenging for U-Net, and its state-of-the-art variants, such as CE-Net and DoubleU-Net, to effectively model the higher-level output feature maps of the convolutional units of the network mostly due to the presence of various scales of the region of interest, intricacy of context environments, ambiguous boundaries, and multiformity of textures in medical images. In this paper, we exploit multi-contextual features and several attention strategies to increase networks' ability to model discriminative feature representation for more accurate medical image segmentation, and we present a novel dual U-Net-based architecture named DoubleU-NetPlus. The DoubleU-NetPlus incorporates several architectural modifications. In particular, we integrate EfficientNetB7 as the feature encoder module, a newly designed multi-kernel residual convolution module, and an adaptive feature re-calibrating attention-based atrous spatial pyramid pooling module to progressively and precisely accumulate discriminative multi-scale high-level contextual feature maps and emphasize the salient regions. In addition, we introduce a novel triple attention gate module and a hybrid triple attention module to encourage selective modeling of relevant medical image features. Moreover, to mitigate the gradient vanishing issue and incorporate high-resolution features with deeper spatial details, the standard convolution operation is replaced with the attention-guided residual convolution operations, ...
Classification of Human Monkeypox Disease Using Deep Learning Models and Attention Mechanisms
Nov 21, 2022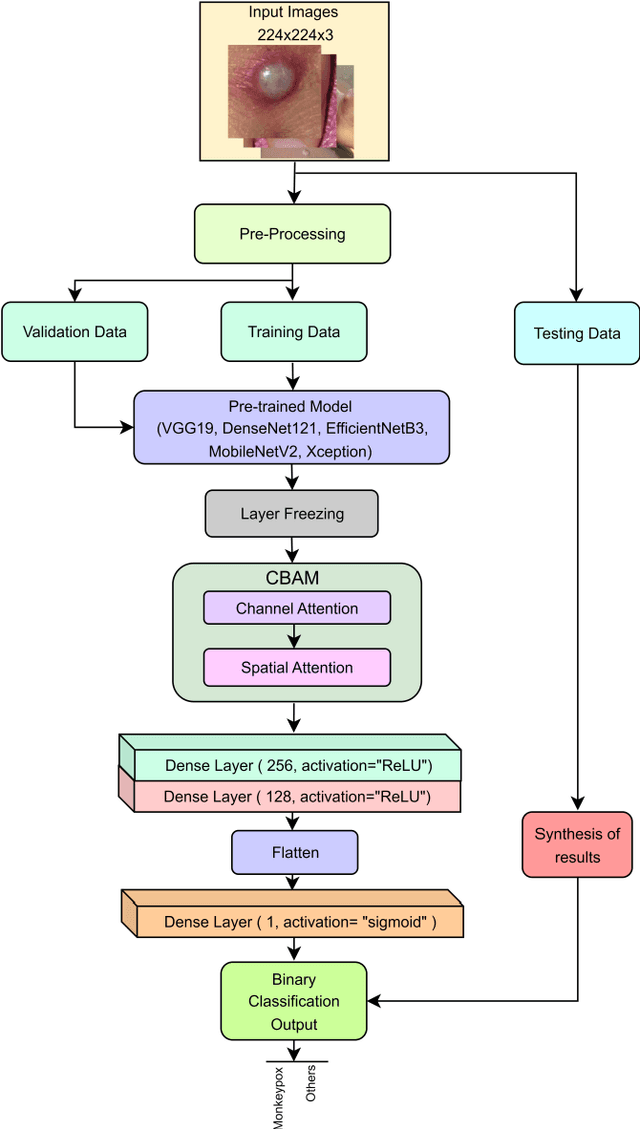
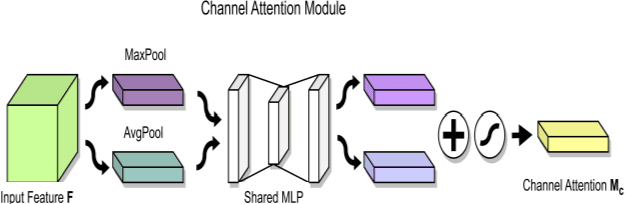
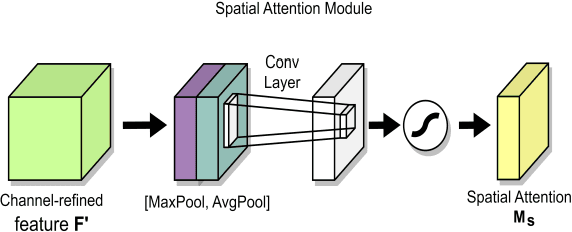
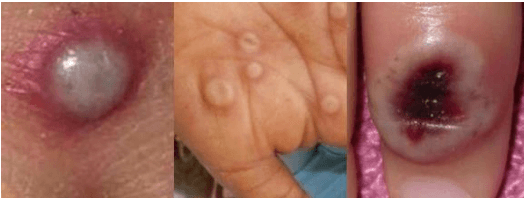
As the world is still trying to rebuild from the destruction caused by the widespread reach of the COVID-19 virus, and the recent alarming surge of human monkeypox disease outbreaks in numerous countries threatens to become a new global pandemic too. Human monkeypox disease syndromes are quite similar to chickenpox, and measles classic symptoms, with very intricate differences such as skin blisters, which come in diverse forms. Various deep-learning methods have shown promising performances in the image-based diagnosis of COVID-19, tumor cell, and skin disease classification tasks. In this paper, we try to integrate deep transfer-learning-based methods, along with a convolutional block attention module (CBAM), to focus on the relevant portion of the feature maps to conduct an image-based classification of human monkeypox disease. We implement five deep-learning models, VGG19, Xception, DenseNet121, EfficientNetB3, and MobileNetV2, along with integrated channel and spatial attention mechanisms, and perform a comparative analysis among them. An architecture consisting of Xception-CBAM-Dense layers performed better than the other models at classifying human monkeypox and other diseases with a validation accuracy of 83.89%.
DPCSpell: A Transformer-based Detector-Purificator-Corrector Framework for Spelling Error Correction of Bangla and Resource Scarce Indic Languages
Nov 07, 2022



Spelling error correction is the task of identifying and rectifying misspelled words in texts. It is a potential and active research topic in Natural Language Processing because of numerous applications in human language understanding. The phonetically or visually similar yet semantically distinct characters make it an arduous task in any language. Earlier efforts on spelling error correction in Bangla and resource-scarce Indic languages focused on rule-based, statistical, and machine learning-based methods which we found rather inefficient. In particular, machine learning-based approaches, which exhibit superior performance to rule-based and statistical methods, are ineffective as they correct each character regardless of its appropriateness. In this work, we propose a novel detector-purificator-corrector framework based on denoising transformers by addressing previous issues. Moreover, we present a method for large-scale corpus creation from scratch which in turn resolves the resource limitation problem of any left-to-right scripted language. The empirical outcomes demonstrate the effectiveness of our approach that outperforms previous state-of-the-art methods by a significant margin for Bangla spelling error correction. The models and corpus are publicly available at https://tinyurl.com/DPCSpell.
An Ensemble 1D-CNN-LSTM-GRU Model with Data Augmentation for Speech Emotion Recognition
Dec 10, 2021
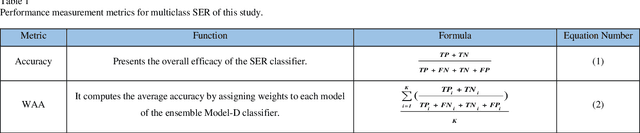
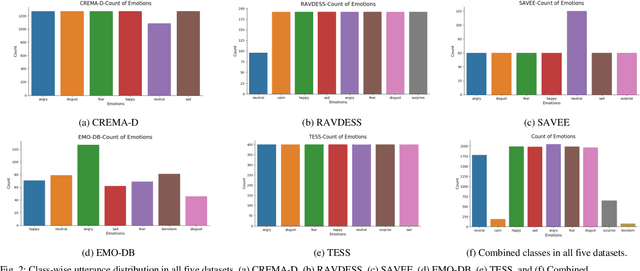
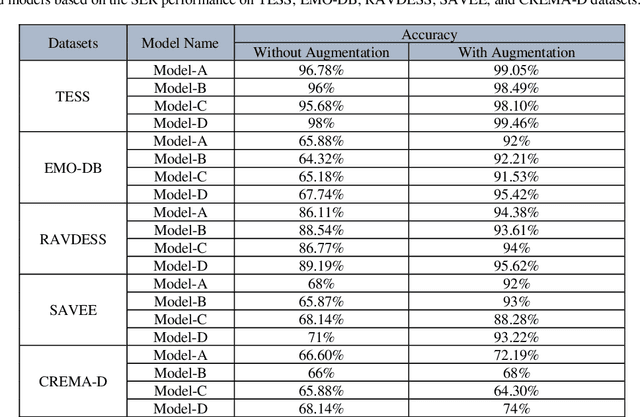
In this paper, we propose an ensemble of deep neural networks along with data augmentation (DA) learned using effective speech-based features to recognize emotions from speech. Our ensemble model is built on three deep neural network-based models. These neural networks are built using the basic local feature acquiring blocks (LFAB) which are consecutive layers of dilated 1D Convolutional Neural networks followed by the max pooling and batch normalization layers. To acquire the long-term dependencies in speech signals further two variants are proposed by adding Gated Recurrent Unit (GRU) and Long Short Term Memory (LSTM) layers respectively. All three network models have consecutive fully connected layers before the final softmax layer for classification. The ensemble model uses a weighted average to provide the final classification. We have utilized five standard benchmark datasets: TESS, EMO-DB, RAVDESS, SAVEE, and CREMA-D for evaluation. We have performed DA by injecting Additive White Gaussian Noise, pitch shifting, and stretching the signal level to generalize the models, and thus increasing the accuracy of the models and reducing the overfitting as well. We handcrafted five categories of features: Mel-frequency cepstral coefficients, Log Mel-Scaled Spectrogram, Zero-Crossing Rate, Chromagram, and statistical Root Mean Square Energy value from each audio sample. These features are used as the input to the LFAB blocks that further extract the hidden local features which are then fed to either fully connected layers or to LSTM or GRU based on the model type to acquire the additional long-term contextual representations. LFAB followed by GRU or LSTM results in better performance compared to the baseline model. The ensemble model achieves the state-of-the-art weighted average accuracy in all the datasets.
A Comprehensive Comparison of Machine Learning Based Methods Used in Bengali Question Classification
Nov 19, 2019

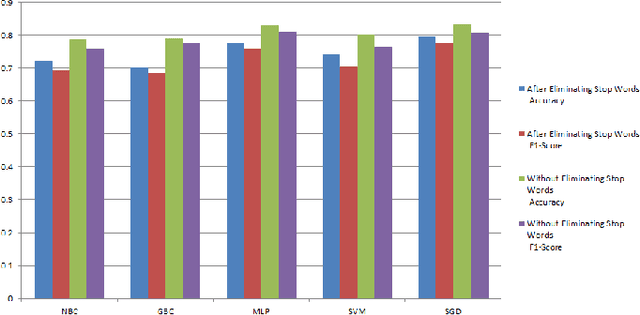

QA classification system maps questions asked by humans to an appropriate answer category. A sound question classification (QC) system model is the pre-requisite of a sound QA system. This work demonstrates phases of assembling a QA type classification model. We present a comprehensive comparison (performance and computational complexity) among some machine learning based approaches used in QC for Bengali language.