 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany Dialects, Many Languages, One Cultural Lens: Evaluating Multilingual VLMs for Bengali Culture Understanding Across Historically Linked Languages and Regional Dialects
Mar 22, 2026Bangla culture is richly expressed through region, dialect, history, food, politics, media, and everyday visual life, yet it remains underrepresented in multimodal evaluation. To address this gap, we introduce BanglaVerse, a culturally grounded benchmark for evaluating multilingual vision-language models (VLMs) on Bengali culture across historically linked languages and regional dialects. Built from 1,152 manually curated images across nine domains, the benchmark supports visual question answering and captioning, and is expanded into four languages and five Bangla dialects, yielding ~32.3K artifacts. Our experiments show that evaluating only standard Bangla overestimates true model capability: performance drops under dialectal variation, especially for caption generation, while historically linked languages such as Hindi and Urdu retain some cultural meaning but remain weaker for structured reasoning. Across domains, the main bottleneck is missing cultural knowledge rather than visual grounding alone, with knowledge-intensive categories. These findings position BanglaVerse as a more realistic test bed for measuring culturally grounded multimodal understanding under linguistic variation.
KEMP-PIP: A Feature-Fusion Based Approach for Pro-inflammatory Peptide Prediction
Feb 22, 2026Pro-inflammatory peptides (PIPs) play critical roles in immune signaling and inflammation but are difficult to identify experimentally due to costly and time-consuming assays. To address this challenge, we present KEMP-PIP, a hybrid machine learning framework that integrates deep protein embeddings with handcrafted descriptors for robust PIP prediction. Our approach combines contextual embeddings from pretrained ESM protein language models with multi-scale k-mer frequencies, physicochemical descriptors, and modlAMP sequence features. Feature pruning and class-weighted logistic regression manage high dimensionality and class imbalance, while ensemble averaging with an optimized decision threshold enhances the sensitivity--specificity balance. Through systematic ablation studies, we demonstrate that integrating complementary feature sets consistently improves predictive performance. On the standard benchmark dataset, KEMP-PIP achieves an MCC of 0.505, accuracy of 0.752, and AUC of 0.762, outperforming ProIn-fuse, MultiFeatVotPIP, and StackPIP. Relative to StackPIP, these results represent improvements of 9.5% in MCC and 4.8% in both accuracy and AUC. The KEMP-PIP web server is freely available at https://nilsparrow1920-kemp-pip.hf.space/ and the full implementation at https://github.com/S18-Niloy/KEMP-PIP.
Deepfake Synthesis vs. Detection: An Uneven Contest
Feb 08, 2026The rapid advancement of deepfake technology has significantly elevated the realism and accessibility of synthetic media. Emerging techniques, such as diffusion-based models and Neural Radiance Fields (NeRF), alongside enhancements in traditional Generative Adversarial Networks (GANs), have contributed to the sophisticated generation of deepfake videos. Concurrently, deepfake detection methods have seen notable progress, driven by innovations in Transformer architectures, contrastive learning, and other machine learning approaches. In this study, we conduct a comprehensive empirical analysis of state-of-the-art deepfake detection techniques, including human evaluation experiments against cutting-edge synthesis methods. Our findings highlight a concerning trend: many state-of-the-art detection models exhibit markedly poor performance when challenged with deepfakes produced by modern synthesis techniques, including poor performance by human participants against the best quality deepfakes. Through extensive experimentation, we provide evidence that underscores the urgent need for continued refinement of detection models to keep pace with the evolving capabilities of deepfake generation technologies. This research emphasizes the critical gap between current detection methodologies and the sophistication of new generation techniques, calling for intensified efforts in this crucial area of study.
Understanding QA generation: Extracting Parametric and Contextual Knowledge with CQA for Low Resource Bangla Language
Feb 01, 2026Question-Answering (QA) models for low-resource languages like Bangla face challenges due to limited annotated data and linguistic complexity. A key issue is determining whether models rely more on pre-encoded (parametric) knowledge or contextual input during answer generation, as existing Bangla QA datasets lack the structure required for such analysis. We introduce BanglaCQA, the first Counterfactual QA dataset in Bangla, by extending a Bangla dataset while integrating counterfactual passages and answerability annotations. In addition, we propose fine-tuned pipelines for encoder-decoder language-specific and multilingual baseline models, and prompting-based pipelines for decoder-only LLMs to disentangle parametric and contextual knowledge in both factual and counterfactual scenarios. Furthermore, we apply LLM-based and human evaluation techniques that measure answer quality based on semantic similarity. We also present a detailed analysis of how models perform across different QA settings in low-resource languages, and show that Chain-of-Thought (CoT) prompting reveals a uniquely effective mechanism for extracting parametric knowledge in counterfactual scenarios, particularly in decoder-only LLMs. Our work not only introduces a novel framework for analyzing knowledge sources in Bangla QA but also uncovers critical findings that open up broader directions for counterfactual reasoning in low-resource language settings.
Can LLMs Solve My Grandma's Riddle? Evaluating Multilingual Large Language Models on Reasoning Traditional Bangla Tricky Riddles
Dec 23, 2025Large Language Models (LLMs) show impressive performance on many NLP benchmarks, yet their ability to reason in figurative, culturally grounded, and low-resource settings remains underexplored. We address this gap for Bangla by introducing BanglaRiddleEval, a benchmark of 1,244 traditional Bangla riddles instantiated across four tasks (4,976 riddle-task artifacts in total). Using an LLM-based pipeline, we generate Chain-of-Thought explanations, semantically coherent distractors, and fine-grained ambiguity annotations, and evaluate a diverse suite of open-source and closed-source models under different prompting strategies. Models achieve moderate semantic overlap on generative QA but low correctness, MCQ accuracy peaks at only about 56% versus an 83% human baseline, and ambiguity resolution ranges from roughly 26% to 68%, with high-quality explanations confined to the strongest models. These results show that current LLMs capture some cues needed for Bangla riddle reasoning but remain far from human-level performance, establishing BanglaRiddleEval as a challenging new benchmark for low-resource figurative reasoning. All data, code, and evaluation scripts are available on GitHub: https://github.com/Labib1610/BanglaRiddleEval.
Do Multi-Agents Solve Better Than Single? Evaluating Agentic Frameworks for Diagram-Grounded Geometry Problem Solving and Reasoning
Dec 18, 2025Diagram-grounded geometry problem solving is a critical benchmark for multimodal large language models (MLLMs), yet the benefits of multi-agent design over single-agent remain unclear. We systematically compare single-agent and multi-agent pipelines on four visual math benchmarks: Geometry3K, MathVerse, OlympiadBench, and We-Math. For open-source models, multi-agent consistently improves performance. For example, Qwen-2.5-VL (7B) gains +6.8 points and Qwen-2.5-VL (32B) gains +3.3 on Geometry3K, and both Qwen-2.5-VL variants see further gains on OlympiadBench and We-Math. In contrast, the closed-source Gemini-2.0-Flash generally performs better in single-agent mode on classic benchmarks, while multi-agent yields only modest improvements on the newer We-Math dataset. These findings show that multi-agent pipelines provide clear benefits for open-source models and can assist strong proprietary systems on newer, less familiar benchmarks, but agentic decomposition is not universally optimal. All code, data, and reasoning files are available at https://github.com/faiyazabdullah/Interpreter-Solver
MathMist: A Parallel Multilingual Benchmark Dataset for Mathematical Problem Solving and Reasoning
Oct 16, 2025Mathematical reasoning remains one of the most challenging domains for large language models (LLMs), requiring not only linguistic understanding but also structured logical deduction and numerical precision. While recent LLMs demonstrate strong general-purpose reasoning abilities, their mathematical competence across diverse languages remains underexplored. Existing benchmarks primarily focus on English or a narrow subset of high-resource languages, leaving significant gaps in assessing multilingual and cross-lingual mathematical reasoning. To address this, we introduce MathMist, a parallel multilingual benchmark for mathematical problem solving and reasoning. MathMist encompasses over 21K aligned question-answer pairs across seven languages, representing a balanced coverage of high-, medium-, and low-resource linguistic settings. The dataset captures linguistic variety, multiple types of problem settings, and solution synthesizing capabilities. We systematically evaluate a diverse suite of models, including open-source small and medium LLMs, proprietary systems, and multilingual-reasoning-focused models, under zero-shot, chain-of-thought (CoT), and code-switched reasoning paradigms. Our results reveal persistent deficiencies in LLMs' ability to perform consistent and interpretable mathematical reasoning across languages, with pronounced degradation in low-resource settings. All the codes and data are available at GitHub: https://github.com/mahbubhimel/MathMist
Ready to Translate, Not to Represent? Bias and Performance Gaps in Multilingual LLMs Across Language Families and Domains
Oct 09, 2025The rise of Large Language Models (LLMs) has redefined Machine Translation (MT), enabling context-aware and fluent translations across hundreds of languages and textual domains. Despite their remarkable capabilities, LLMs often exhibit uneven performance across language families and specialized domains. Moreover, recent evidence reveals that these models can encode and amplify different biases present in their training data, posing serious concerns for fairness, especially in low-resource languages. To address these gaps, we introduce Translation Tangles, a unified framework and dataset for evaluating the translation quality and fairness of open-source LLMs. Our approach benchmarks 24 bidirectional language pairs across multiple domains using different metrics. We further propose a hybrid bias detection pipeline that integrates rule-based heuristics, semantic similarity filtering, and LLM-based validation. We also introduce a high-quality, bias-annotated dataset based on human evaluations of 1,439 translation-reference pairs. The code and dataset are accessible on GitHub: https://github.com/faiyazabdullah/TranslationTangles
Watch, Listen, Understand, Mislead: Tri-modal Adversarial Attacks on Short Videos for Content Appropriateness Evaluation
Jul 16, 2025Multimodal Large Language Models (MLLMs) are increasingly used for content moderation, yet their robustness in short-form video contexts remains underexplored. Current safety evaluations often rely on unimodal attacks, failing to address combined attack vulnerabilities. In this paper, we introduce a comprehensive framework for evaluating the tri-modal safety of MLLMs. First, we present the Short-Video Multimodal Adversarial (SVMA) dataset, comprising diverse short-form videos with human-guided synthetic adversarial attacks. Second, we propose ChimeraBreak, a novel tri-modal attack strategy that simultaneously challenges visual, auditory, and semantic reasoning pathways. Extensive experiments on state-of-the-art MLLMs reveal significant vulnerabilities with high Attack Success Rates (ASR). Our findings uncover distinct failure modes, showing model biases toward misclassifying benign or policy-violating content. We assess results using LLM-as-a-judge, demonstrating attack reasoning efficacy. Our dataset and findings provide crucial insights for developing more robust and safe MLLMs.
VisText-Mosquito: A Multimodal Dataset and Benchmark for AI-Based Mosquito Breeding Site Detection and Reasoning
Jun 17, 2025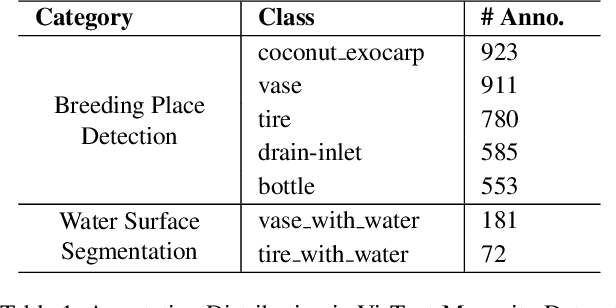

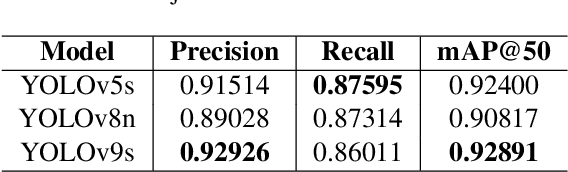
Mosquito-borne diseases pose a major global health risk, requiring early detection and proactive control of breeding sites to prevent outbreaks. In this paper, we present VisText-Mosquito, a multimodal dataset that integrates visual and textual data to support automated detection, segmentation, and reasoning for mosquito breeding site analysis. The dataset includes 1,828 annotated images for object detection, 142 images for water surface segmentation, and natural language reasoning texts linked to each image. The YOLOv9s model achieves the highest precision of 0.92926 and mAP@50 of 0.92891 for object detection, while YOLOv11n-Seg reaches a segmentation precision of 0.91587 and mAP@50 of 0.79795. For reasoning generation, our fine-tuned BLIP model achieves a final loss of 0.0028, with a BLEU score of 54.7, BERTScore of 0.91, and ROUGE-L of 0.87. This dataset and model framework emphasize the theme "Prevention is Better than Cure", showcasing how AI-based detection can proactively address mosquito-borne disease risks. The dataset and implementation code are publicly available at GitHub: https://github.com/adnanul-islam-jisun/VisText-Mosquito