 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextEconomizer: Enhancing Lossy Text Compression with Denoising Transformers and Entropy Coding
Jun 06, 2026Lossy text compression reduces data size while preserving core meaning, making it well-suited for summarization, automated analysis, and digital archives. Despite the dominance of transformer-based models in language modeling, integrating context vectors and entropy coding into Sequence-to-Sequence (Seq2Seq) generation remains underexplored. A key challenge lies in identifying the most informative context vectors from encoder output and incorporating entropy coding to enhance storage efficiency while maintaining high-quality outputs, even under noisy text. We introduce TextEconomizer, an encoder-decoder framework paired with a transformer neural network that reduces variable-sized inputs by 50% to 80% without prior knowledge of dataset dimensions. Our model achieves competitive compression ratios via entropy coding while delivering near-perfect text quality, assessed by BLEU, ROUGE, METEOR, and semantic similarity scores. TextEconomizer operates with approximately 153x fewer parameters than comparable models, achieving a 5.39x compression ratio without sacrificing semantic quality. We also evaluate an LSTM-based autoencoder achieving a state-of-the-art 67x compression ratio with 196x fewer parameters, and LLaMAFormer, a modified transformer with 263x fewer parameters than ICAE while maintaining competitive text quality. TextEconomizer significantly surpasses existing transformer-based models in balancing memory efficiency and high-fidelity outputs, marking a breakthrough in lossy compression with optimal space utilization.
* Published in Neural Networks (Elsevier), Vol. 203, 2026
An Enhanced Text Compression Approach Using Transformer-based Language Models
Dec 15, 2024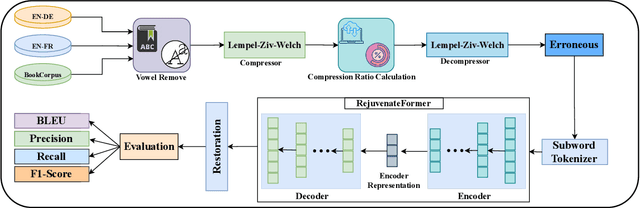

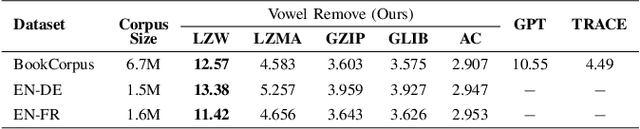
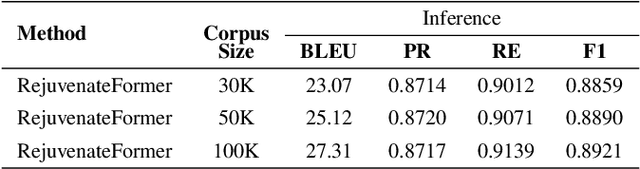
Text compression shrinks textual data while keeping crucial information, eradicating constraints on storage, bandwidth, and computational efficacy. The integration of lossless compression techniques with transformer-based text decompression has received negligible attention, despite the increasing volume of English text data in communication. The primary barrier in advancing text compression and restoration involves optimizing transformer-based approaches with efficient pre-processing and integrating lossless compression algorithms, that remained unresolved in the prior attempts. Here, we propose a transformer-based method named RejuvenateForme for text decompression, addressing prior issues by harnessing a new pre-processing technique and a lossless compression method. Our meticulous pre-processing technique incorporating the Lempel-Ziv-Welch algorithm achieves compression ratios of 12.57, 13.38, and 11.42 on the BookCorpus, EN-DE, and EN-FR corpora, thus showing state-of-the-art compression ratios compared to other deep learning and traditional approaches. Furthermore, the RejuvenateForme achieves a BLEU score of 27.31, 25.78, and 50.45 on the EN-DE, EN-FR, and BookCorpus corpora, showcasing its comprehensive efficacy. In contrast, the pre-trained T5-Small exhibits better performance over prior state-of-the-art models.
MEBoost: Mixing Estimators with Boosting for Imbalanced Data Classification
Jan 13, 2018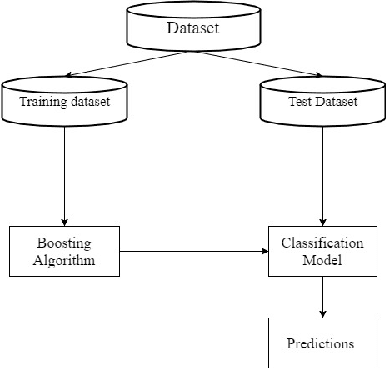
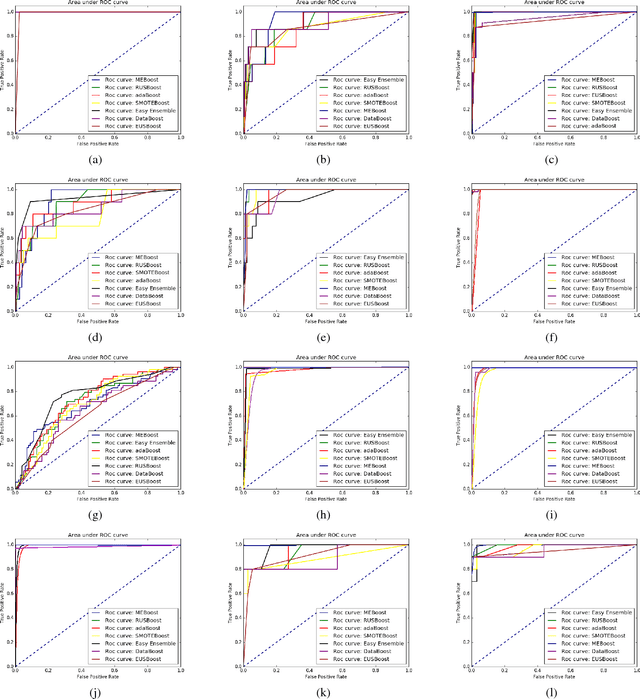
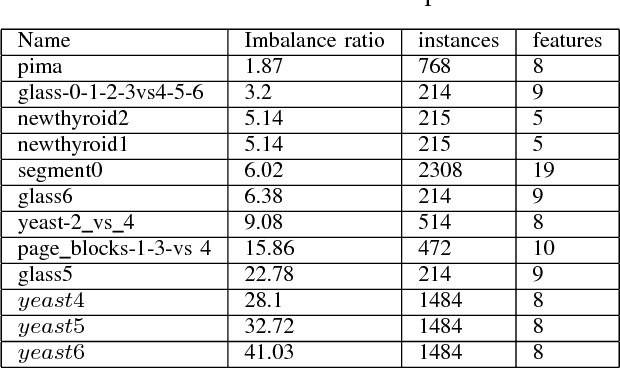
Class imbalance problem has been a challenging research problem in the fields of machine learning and data mining as most real life datasets are imbalanced. Several existing machine learning algorithms try to maximize the accuracy classification by correctly identifying majority class samples while ignoring the minority class. However, the concept of the minority class instances usually represents a higher interest than the majority class. Recently, several cost sensitive methods, ensemble models and sampling techniques have been used in literature in order to classify imbalance datasets. In this paper, we propose MEBoost, a new boosting algorithm for imbalanced datasets. MEBoost mixes two different weak learners with boosting to improve the performance on imbalanced datasets. MEBoost is an alternative to the existing techniques such as SMOTEBoost, RUSBoost, Adaboost, etc. The performance of MEBoost has been evaluated on 12 benchmark imbalanced datasets with state of the art ensemble methods like SMOTEBoost, RUSBoost, Easy Ensemble, EUSBoost, DataBoost. Experimental results show significant improvement over the other methods and it can be concluded that MEBoost is an effective and promising algorithm to deal with imbalance datasets. The python version of the code is available here: https://github.com/farshidrayhanuiu/
LIUBoost : Locality Informed Underboosting for Imbalanced Data Classification
Nov 15, 2017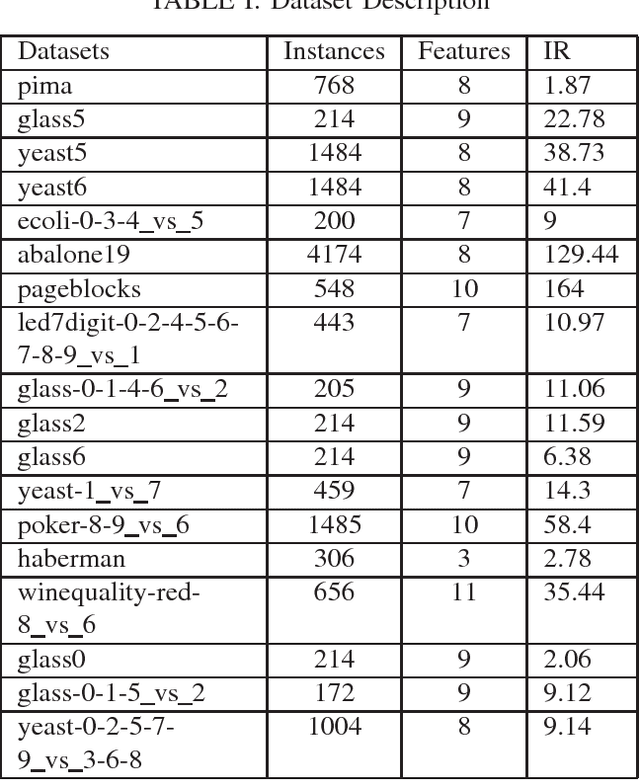



The problem of class imbalance along with class-overlapping has become a major issue in the domain of supervised learning. Most supervised learning algorithms assume equal cardinality of the classes under consideration while optimizing the cost function and this assumption does not hold true for imbalanced datasets which results in sub-optimal classification. Therefore, various approaches, such as undersampling, oversampling, cost-sensitive learning and ensemble based methods have been proposed for dealing with imbalanced datasets. However, undersampling suffers from information loss, oversampling suffers from increased runtime and potential overfitting while cost-sensitive methods suffer due to inadequately defined cost assignment schemes. In this paper, we propose a novel boosting based method called LIUBoost. LIUBoost uses under sampling for balancing the datasets in every boosting iteration like RUSBoost while incorporating a cost term for every instance based on their hardness into the weight update formula minimizing the information loss introduced by undersampling. LIUBoost has been extensively evaluated on 18 imbalanced datasets and the results indicate significant improvement over existing best performing method RUSBoost.
Text Classification using the Concept of Association Rule of Data Mining
Sep 23, 2010
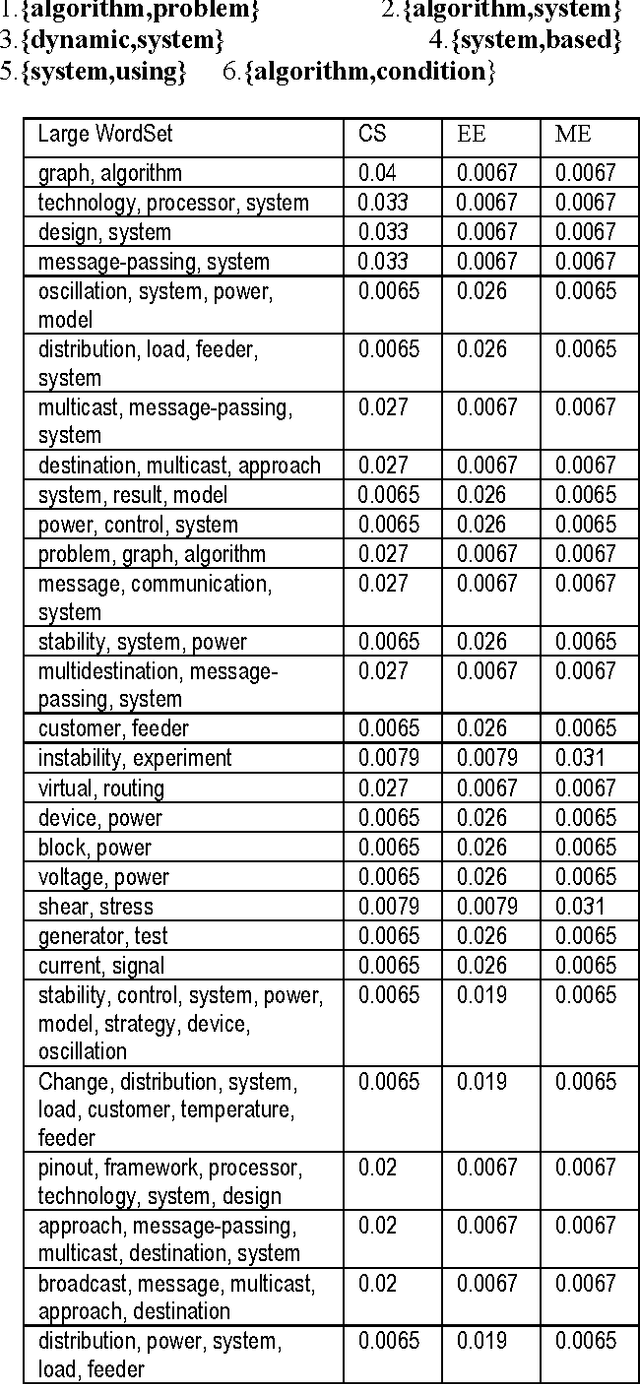
As the amount of online text increases, the demand for text classification to aid the analysis and management of text is increasing. Text is cheap, but information, in the form of knowing what classes a text belongs to, is expensive. Automatic classification of text can provide this information at low cost, but the classifiers themselves must be built with expensive human effort, or trained from texts which have themselves been manually classified. In this paper we will discuss a procedure of classifying text using the concept of association rule of data mining. Association rule mining technique has been used to derive feature set from pre-classified text documents. Naive Bayes classifier is then used on derived features for final classification.
* 8 Pages, International Conference