 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoiceNet: CNN learning through choice of multiple feature map representations
Apr 20, 2019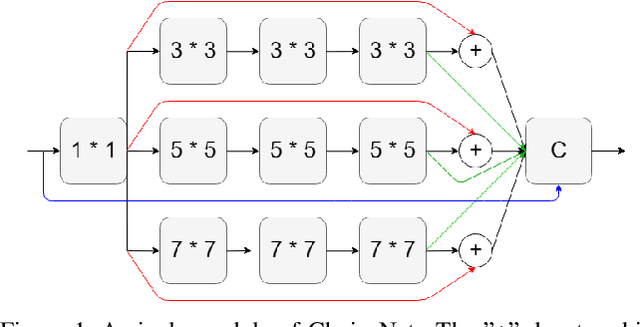
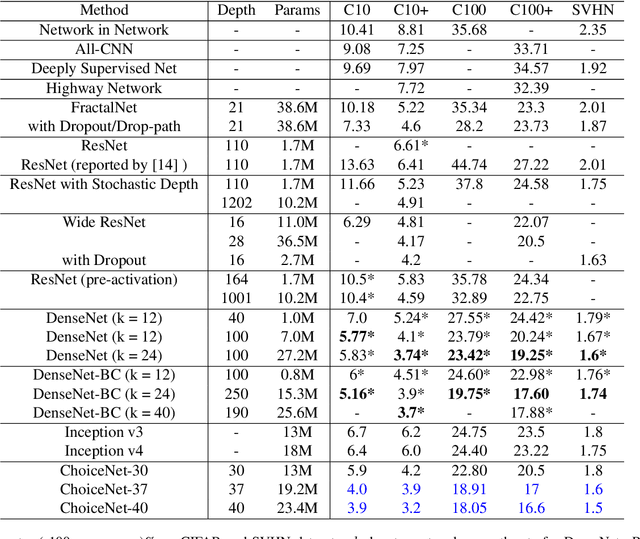
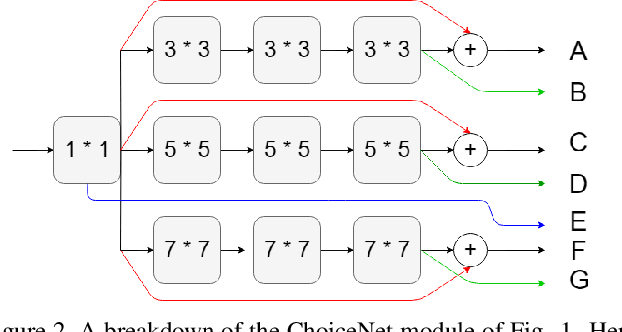
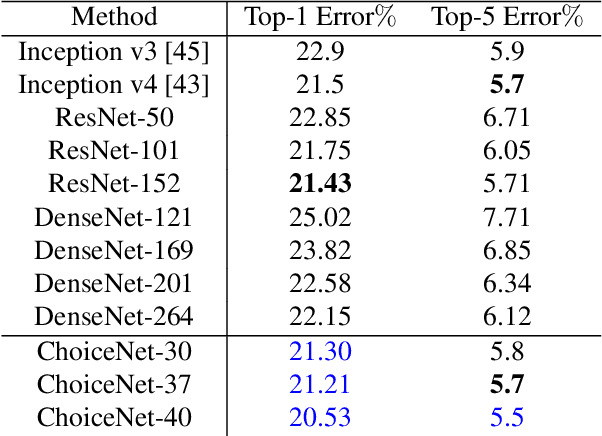
We introduce a new architecture called ChoiceNet where each layer of the network is highly connected with skip connections and channelwise concatenations. This enables the network to alleviate the problem of vanishing gradients, reduces the number of parameters without sacrificing performance, and encourages feature reuse. We evaluate our proposed architecture on three benchmark datasetsforobjectrecognitiontasks(CIFAR-10,CIFAR100, SVHN) and on a semantic segmentation dataset (CamVid).
FRnet-DTI: Deep Convolutional Neural Networks with Evolutionary and Structural Features for Drug-Target Interaction
Aug 31, 2018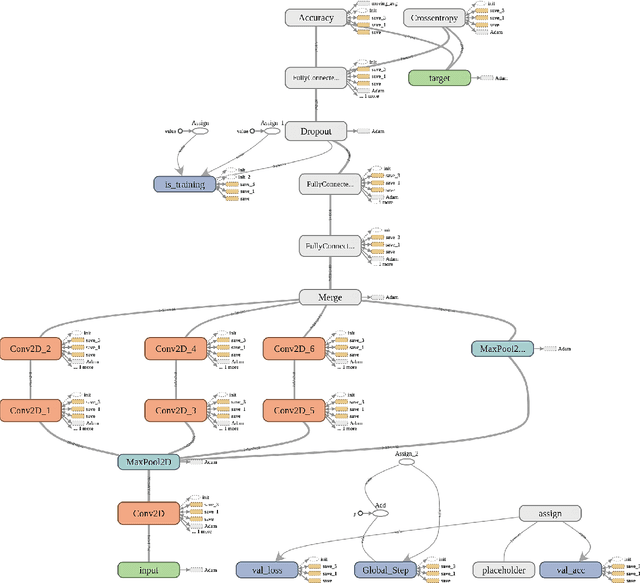


The task of drug-target interaction prediction holds significant importance in pharmacology and therapeutic drug design. In this paper, we present FRnet-DTI, an auto encoder and a convolutional classifier for feature manipulation and drug target interaction prediction. Two convolutional neural neworks are proposed where one model is used for feature manipulation and the other one for classification. Using the first method FRnet-1, we generate 4096 features for each of the instances in each of the datasets and use the second method, FRnet-2, to identify interaction probability employing those features. We have tested our method on four gold standard datasets exhaustively used by other researchers. Experimental results shows that our method significantly improves over the state-of-the-art method on three of the four drug-target interaction gold standard datasets on both area under curve for Receiver Operating Characteristic(auROC) and area under Precision Recall curve(auPR) metric. We also introduce twenty new potential drug-target pairs for interaction based on high prediction scores. Codes Available: https: // github. com/ farshidrayhanuiu/ FRnet-DTI/ Web Implementation: http: // farshidrayhan. pythonanywhere. com/ FRnet-DTI/
MEBoost: Mixing Estimators with Boosting for Imbalanced Data Classification
Jan 13, 2018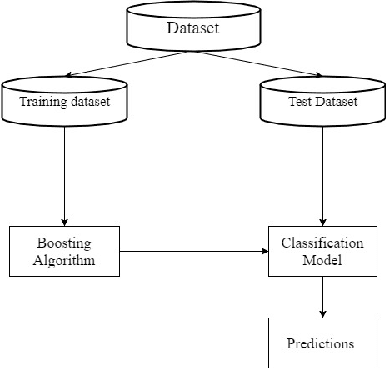
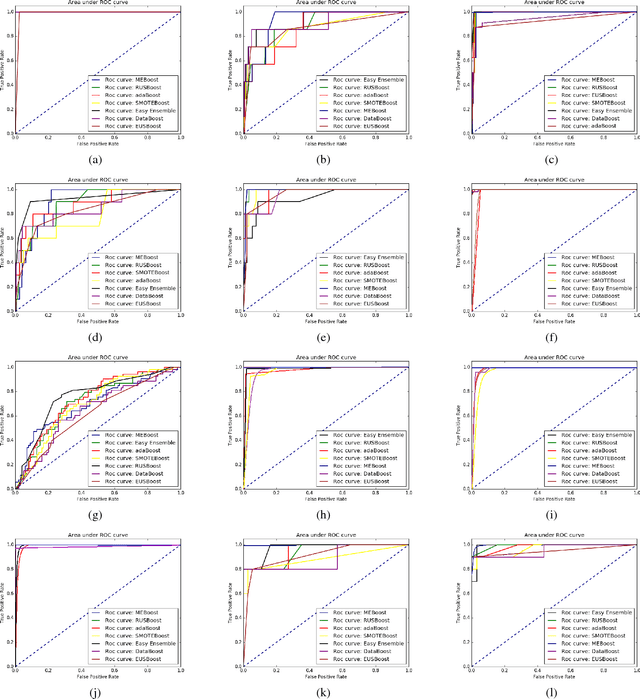
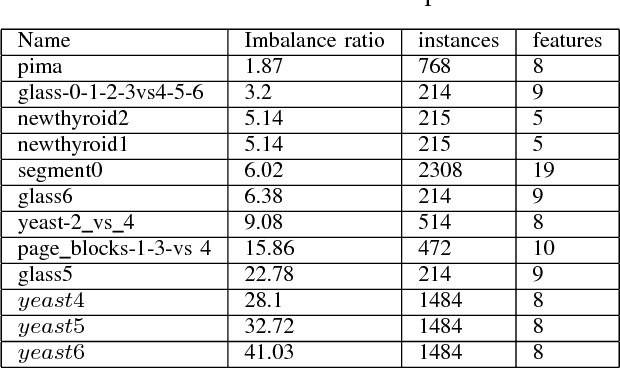
Class imbalance problem has been a challenging research problem in the fields of machine learning and data mining as most real life datasets are imbalanced. Several existing machine learning algorithms try to maximize the accuracy classification by correctly identifying majority class samples while ignoring the minority class. However, the concept of the minority class instances usually represents a higher interest than the majority class. Recently, several cost sensitive methods, ensemble models and sampling techniques have been used in literature in order to classify imbalance datasets. In this paper, we propose MEBoost, a new boosting algorithm for imbalanced datasets. MEBoost mixes two different weak learners with boosting to improve the performance on imbalanced datasets. MEBoost is an alternative to the existing techniques such as SMOTEBoost, RUSBoost, Adaboost, etc. The performance of MEBoost has been evaluated on 12 benchmark imbalanced datasets with state of the art ensemble methods like SMOTEBoost, RUSBoost, Easy Ensemble, EUSBoost, DataBoost. Experimental results show significant improvement over the other methods and it can be concluded that MEBoost is an effective and promising algorithm to deal with imbalance datasets. The python version of the code is available here: https://github.com/farshidrayhanuiu/
CUSBoost: Cluster-based Under-sampling with Boosting for Imbalanced Classification
Dec 12, 2017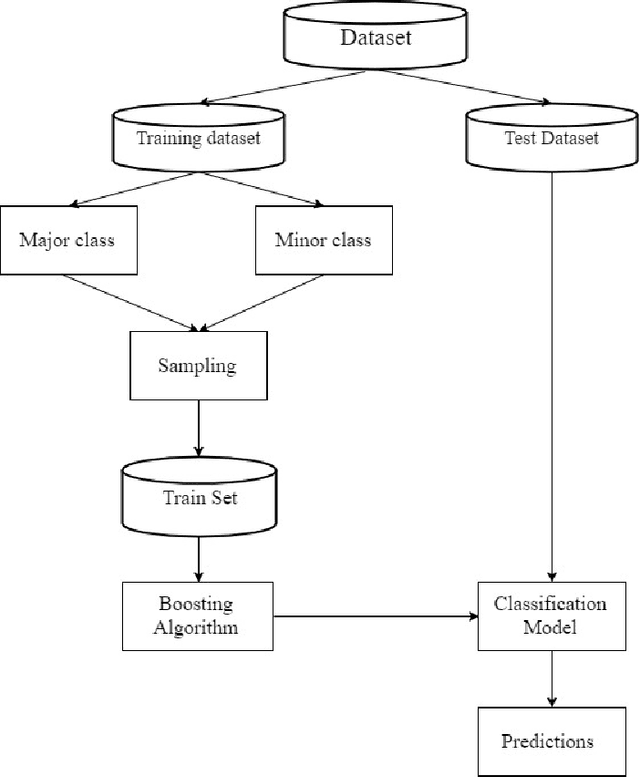


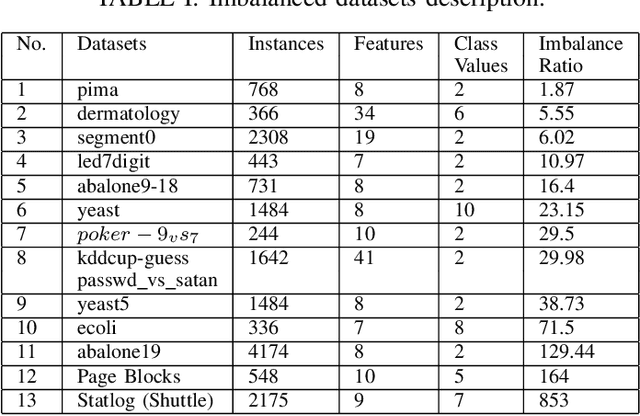
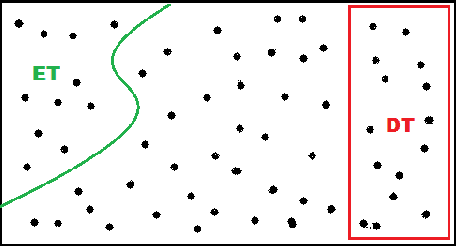
Class imbalance classification is a challenging research problem in data mining and machine learning, as most of the real-life datasets are often imbalanced in nature. Existing learning algorithms maximise the classification accuracy by correctly classifying the majority class, but misclassify the minority class. However, the minority class instances are representing the concept with greater interest than the majority class instances in real-life applications. Recently, several techniques based on sampling methods (under-sampling of the majority class and over-sampling the minority class), cost-sensitive learning methods, and ensemble learning have been used in the literature for classifying imbalanced datasets. In this paper, we introduce a new clustering-based under-sampling approach with boosting (AdaBoost) algorithm, called CUSBoost, for effective imbalanced classification. The proposed algorithm provides an alternative to RUSBoost (random under-sampling with AdaBoost) and SMOTEBoost (synthetic minority over-sampling with AdaBoost) algorithms. We evaluated the performance of CUSBoost algorithm with the state-of-the-art methods based on ensemble learning like AdaBoost, RUSBoost, SMOTEBoost on 13 imbalance binary and multi-class datasets with various imbalance ratios. The experimental results show that the CUSBoost is a promising and effective approach for dealing with highly imbalanced datasets.
LIUBoost : Locality Informed Underboosting for Imbalanced Data Classification
Nov 15, 2017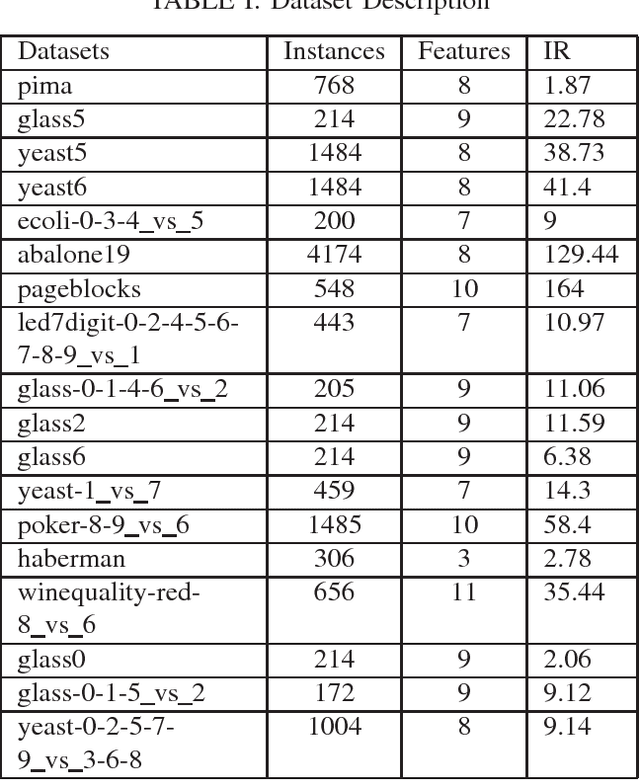



The problem of class imbalance along with class-overlapping has become a major issue in the domain of supervised learning. Most supervised learning algorithms assume equal cardinality of the classes under consideration while optimizing the cost function and this assumption does not hold true for imbalanced datasets which results in sub-optimal classification. Therefore, various approaches, such as undersampling, oversampling, cost-sensitive learning and ensemble based methods have been proposed for dealing with imbalanced datasets. However, undersampling suffers from information loss, oversampling suffers from increased runtime and potential overfitting while cost-sensitive methods suffer due to inadequately defined cost assignment schemes. In this paper, we propose a novel boosting based method called LIUBoost. LIUBoost uses under sampling for balancing the datasets in every boosting iteration like RUSBoost while incorporating a cost term for every instance based on their hardness into the weight update formula minimizing the information loss introduced by undersampling. LIUBoost has been extensively evaluated on 18 imbalanced datasets and the results indicate significant improvement over existing best performing method RUSBoost.