 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivity Recognition Using mm-Wave Radar and Deep Learning: Prayer Tracker Case Study
Apr 06, 2026The issue of privacy has gained significant attention in recent times. Many real-world applications increasingly require the use of sensitive data, such as in surveillance or tracking and assistance systems. To address these concerns, we propose a framework based on mm-wave radar technology that not only meets privacy requirements but also provides the necessary capabilities for these systems, including reliable current position tracking, sequence tracking, and feedback to the user. While the use of radar technology for surveillance purposes is gaining momentum, there has been no research to date on its application for prayer tracking and assistance systems. Furthermore, there is a lack of comprehensive research that covers all aspects of implementing such a system. Proposed approach offers a versatile solution that can be applied to a broad range of scenarios. Instead of utilizing raw I-Q data, we addressed the challenge of classification based on point cloud information generated by the conventional processing chain of the frequency-modulated continuous wave radar. This information contains corresponding range, reflection amplitude, Doppler and angular values. We have developed and compared different machine-learning classification algorithms to identify the most effective one. Our findings reveal that the convolutional neural network ResNet achieves the best results, with accuracy rates reaching up to 95.4 percent when applied to unknown data. The demonstration video of the developed system can be viewed at the following link: https://youtu.be/PnpGQZWqCr4.
Design of Frequency Index Modulated Waveforms for Integrated SAR and Communication on High-Altitude Platforms (HAPs)
Dec 22, 2024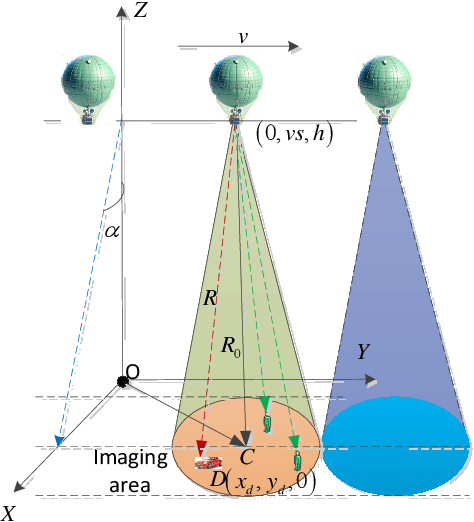
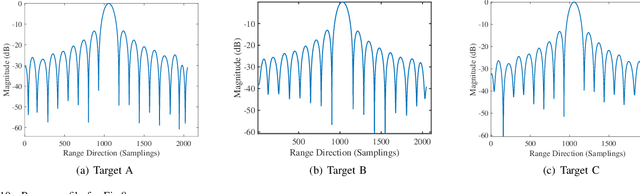
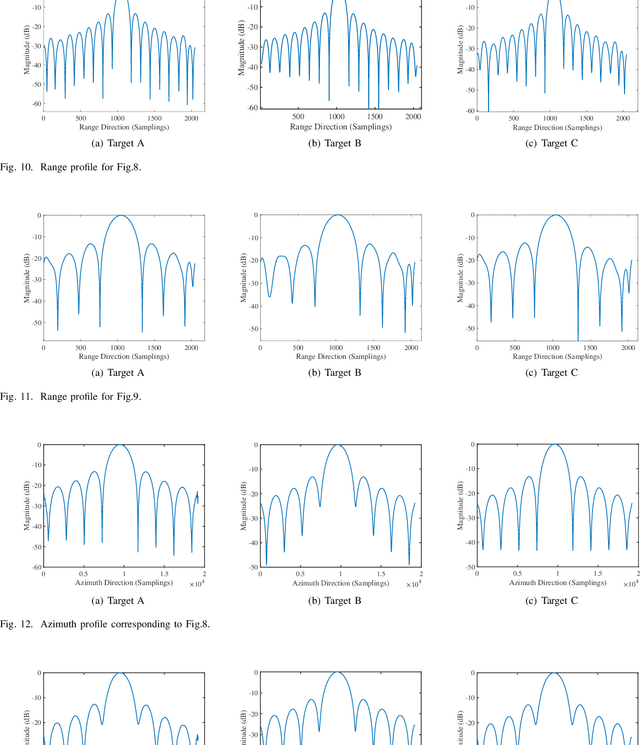
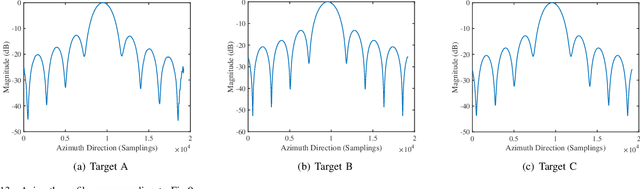
This paper, addressing the integration requirements of radar imaging and communication for High-Altitude Platform Stations (HAPs) platforms, designs a waveform based on linear frequency modulated (LFM) frequency-hopping signals that combines synthetic aperture radar (SAR) and communication functionalities. Specifically, each pulse of an LFM signal is segmented into multiple parts, forming a sequence of sub-pulses. Each sub-pulse can adopt a different carrier frequency, leading to frequency hops between sub-pulses. This design is termed frequency index modulation (FIM), enabling the embedding of communication information into different carrier frequencies for transmission. To further enhance the data transmission rate at the communication end, this paper incorporates quadrature amplitude modulation (QAM) into waveform design. %For the SAR portion, this approach reduces the ADC sampling requirements while maintaining range resolution. The paper derives the ambiguity function of the proposed waveform and analyzes its Doppler and range resolution, establishing upper and lower bounds for the range resolution. In processing SAR signals, the receiver first removes QAM symbols, and to address phase discontinuities between sub-pulses, a phase compensation algorithm is proposed to achieve coherent processing. For the communication receiver, the user first performs de-chirp processing and then demodulates QAM symbols and FIM index symbols using a two-step maximum likelihood (ML) algorithm. Numerical simulations further confirm the theoretical validity of the proposed approach.
Exploring the Synergy: A Review of Dual-Functional Radar Communication Systems
Dec 31, 2023This review paper examines the concept and advancements in the evolving landscape of Dual-functional Radar Communication (DFRC) systems. Traditionally, radar and communication systems have functioned independently, but current research is actively investigating the integration of these functionalities into a unified platform. This paper discusses the motivations behind the development of DFRC systems, the challenges involved, and the potential benefits they offer. A discussion on the performance bounds for DFRC systems is also presented. The paper encompasses a comprehensive analysis of various techniques, architectures, and technologies used in the design and optimization of DFRC systems, along with their performance and trade-offs. Additionally, we explore potential application scenarios for these joint communication and sensing systems, offering a comprehensive perspective on the multifaceted landscape of DFRC technology.
Machine Learning-Based Automatic Cardiovascular Disease Diagnosis Using Two ECG Leads
May 25, 2023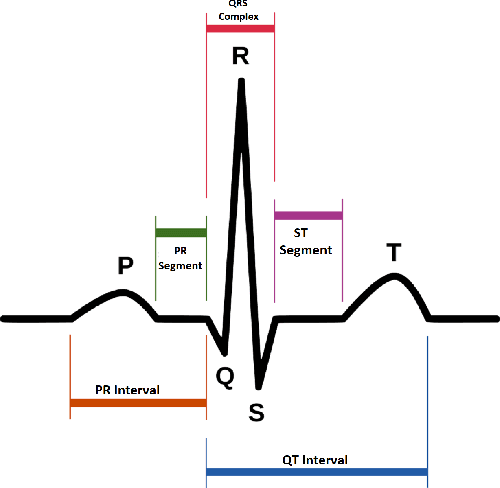

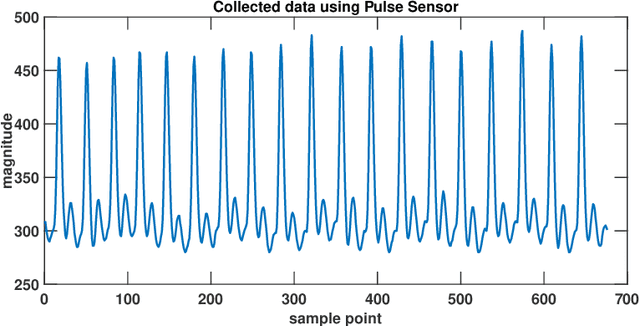
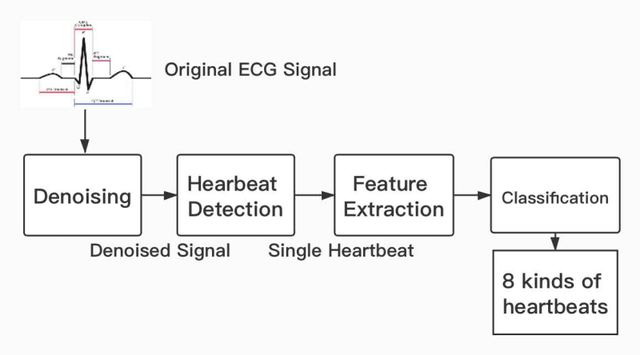
The state-of-the-art cardiovascular disease diagnosis techniques use machine-learning algorithms based on feature extraction and classification. In this work, in contrast to a conventional single Electrocardiogram (ECG) lead, two leads are used, and autoregressive (AR) coefficients and statistical parameters are extracted to be used as features. Four machine-learning classifiers support-vector-machine (SVM), K-nearest neighbors (KNN), multi-layer perceptron (MLP), and Naive Bayes are applied on these features to test the accuracy of each classifier. For simulation, data is collected from the MIT-BIH and Shaoxing Peoples Hospital China (SPHC) database. To test the generalization ability of our proposed methodology machine-learning model is built on the SPHC database and tested on the MIT-BIH database and self-collected datasets. In the single-database simulation, the MLP performs better than the other three classifiers. While in the cross-database simulation, the SVM-based model trained by the SPHC database shows superiority. For normal and LBBB heartbeats, the predicted recall respectively reaches 100% and 98.4%. Simulation results show that the performance of our proposed methodology is better than the state-of-the-art techniques for the same database. While for cross-database simulation, the results are promising too. Finally, in the demonstration of our realized system, all heartbeats collected from healthy people are classified as normal beats.
Generalized Fully Coherent Closed-form Receiver Design for Joint Radar and Communication System
Nov 28, 2021
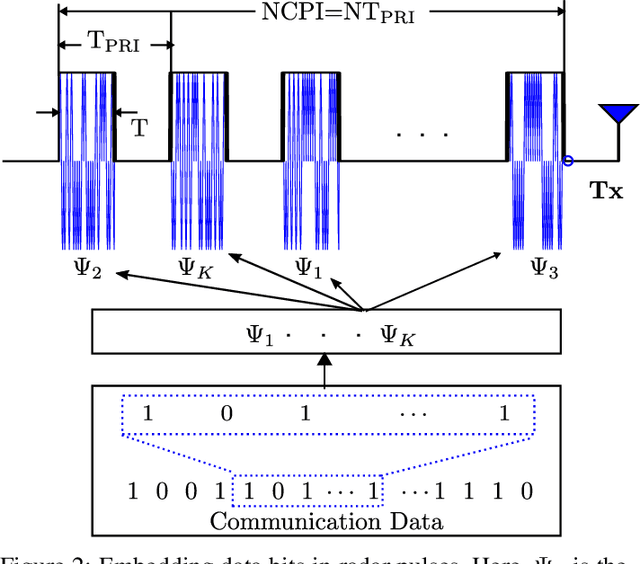
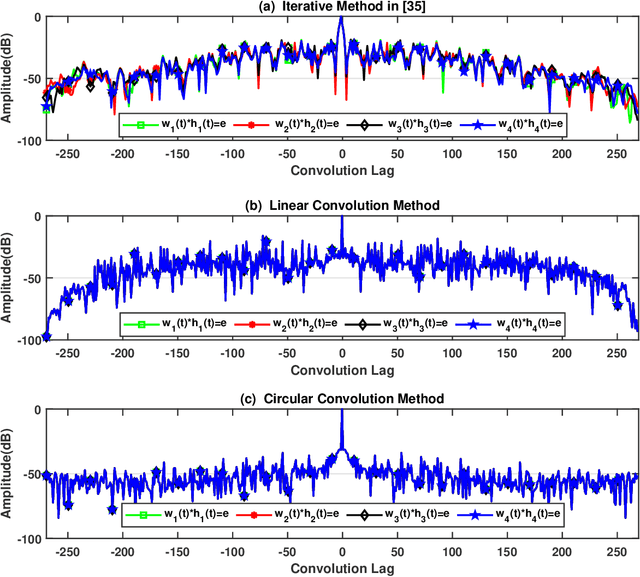
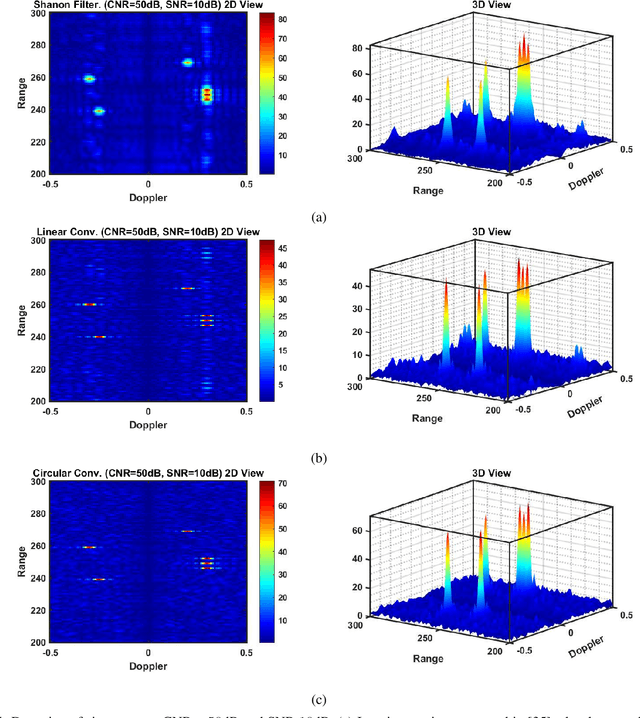
In conventional radar, the transmission of the same waveform is repeated after a predefined interval of time called pulse-repetition-interval (PRI). This technique helps to estimate the range and Doppler shift of targets and suppress clutter. In dual-function radar communication (DFRC), different waveforms are transmitted after each PRI. Thus, each waveform yields different range-side-lobe (RSL) levels at the receiver's output. As a consequence, Doppler shift estimation and clutter suppression become challenging tasks. A state-of-the-art (SOTA) method claims that if the number of waveforms is more than two, it is impossible to achieve fully coherent RSL levels with both waveforms. Therefore, this algorithm uses iterative methods to achieve as much as possible coherency and minimize the RSL levels. In contrast to that SOTA method, we proposed two novel closed-form receivers for the DFRC that yield a fully coherent response for several waveforms and suppress the RSL levels. Experimental results demonstrate that the proposed receivers achieve full coherency and the RSL levels are significantly lower than the conventional method.
iPromoter-BnCNN: a Novel Branched CNN Based Predictor for Identifying and Classifying Sigma Promoters
Jan 10, 2020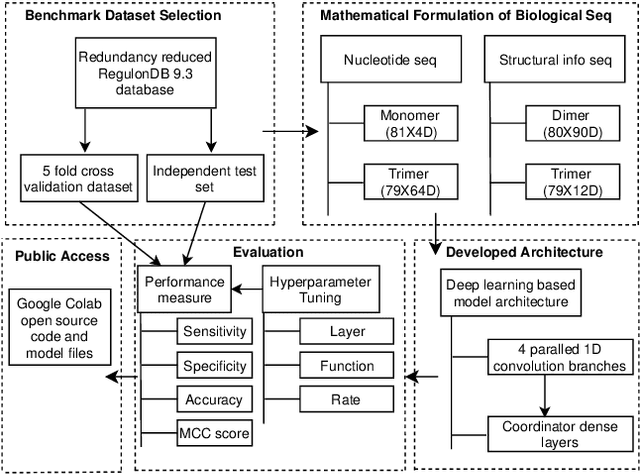
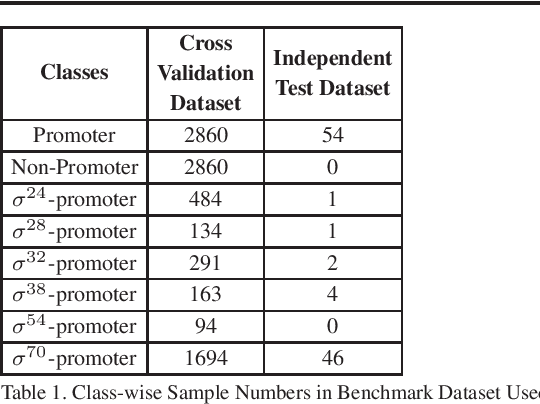
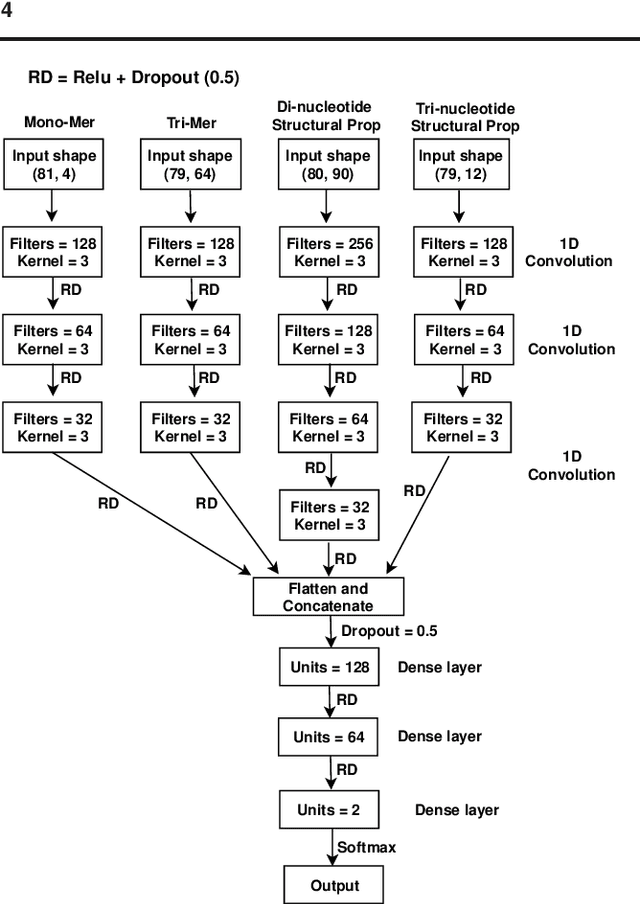
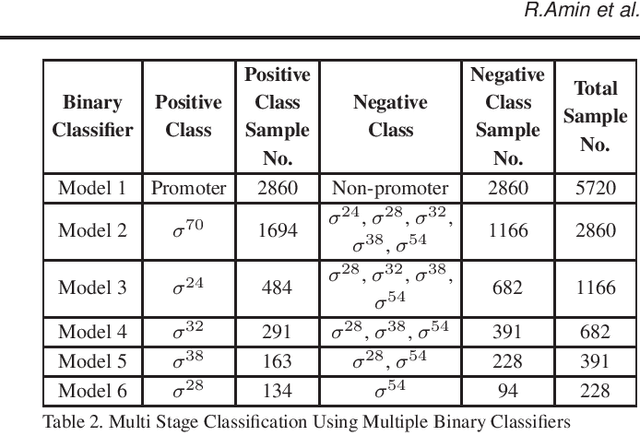
Promoter is a short region of DNA which is responsible for initiating transcription of specific genes. Development of computational tools for automatic identification of promoters is in high demand. According to the difference of functions, promoters can be of different types. Promoters may have both intra and inter class variation and similarity in terms of consensus sequences. Accurate classification of various types of sigma promoters still remains a challenge. We present iPromoter-BnCNN for identification and accurate classification of six types of promoters - sigma24, sigma28, sigma32, sigma38, sigma54, sigma70. It is a Convolutional Neural Network (CNN) based classifier which combines local features related to monomer nucleotide sequence, trimer nucleotide sequence, dimer structural properties and trimer structural properties through the use of parallel branching. We conducted experiments on a benchmark dataset and compared with two state-of-the-art tools to show our supremacy on 5-fold cross-validation. Moreover, we tested our classifier on an independent test dataset. Our proposed tool iPromoter-BnCNN along with the source code is freely available at https://cutt.ly/te6XISV.
FRnet-DTI: Deep Convolutional Neural Networks with Evolutionary and Structural Features for Drug-Target Interaction
Aug 31, 2018


The task of drug-target interaction prediction holds significant importance in pharmacology and therapeutic drug design. In this paper, we present FRnet-DTI, an auto encoder and a convolutional classifier for feature manipulation and drug target interaction prediction. Two convolutional neural neworks are proposed where one model is used for feature manipulation and the other one for classification. Using the first method FRnet-1, we generate 4096 features for each of the instances in each of the datasets and use the second method, FRnet-2, to identify interaction probability employing those features. We have tested our method on four gold standard datasets exhaustively used by other researchers. Experimental results shows that our method significantly improves over the state-of-the-art method on three of the four drug-target interaction gold standard datasets on both area under curve for Receiver Operating Characteristic(auROC) and area under Precision Recall curve(auPR) metric. We also introduce twenty new potential drug-target pairs for interaction based on high prediction scores. Codes Available: https: // github. com/ farshidrayhanuiu/ FRnet-DTI/ Web Implementation: http: // farshidrayhan. pythonanywhere. com/ FRnet-DTI/
MEBoost: Mixing Estimators with Boosting for Imbalanced Data Classification
Jan 13, 2018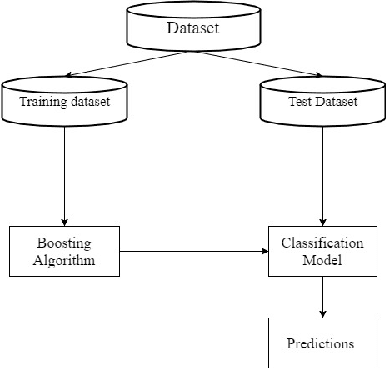
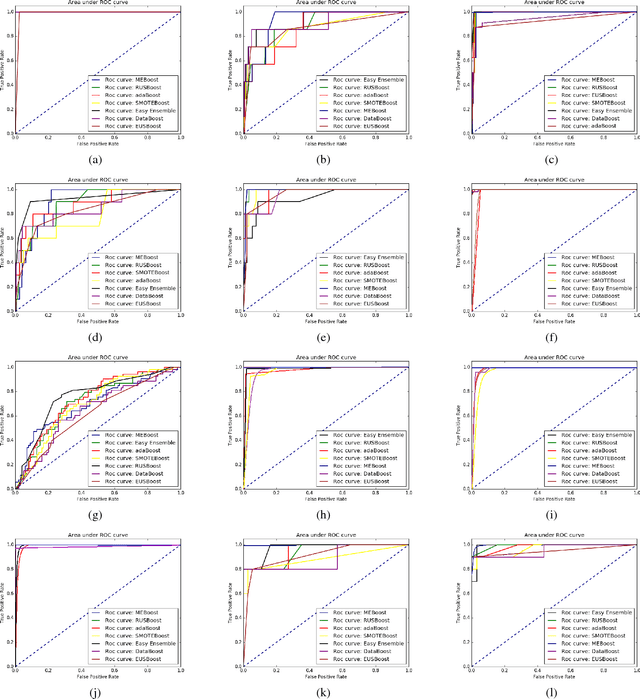
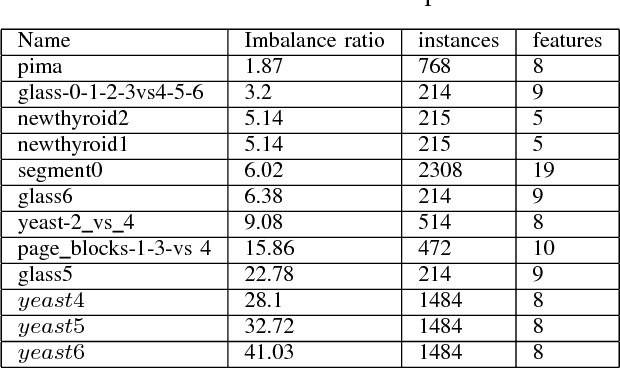
Class imbalance problem has been a challenging research problem in the fields of machine learning and data mining as most real life datasets are imbalanced. Several existing machine learning algorithms try to maximize the accuracy classification by correctly identifying majority class samples while ignoring the minority class. However, the concept of the minority class instances usually represents a higher interest than the majority class. Recently, several cost sensitive methods, ensemble models and sampling techniques have been used in literature in order to classify imbalance datasets. In this paper, we propose MEBoost, a new boosting algorithm for imbalanced datasets. MEBoost mixes two different weak learners with boosting to improve the performance on imbalanced datasets. MEBoost is an alternative to the existing techniques such as SMOTEBoost, RUSBoost, Adaboost, etc. The performance of MEBoost has been evaluated on 12 benchmark imbalanced datasets with state of the art ensemble methods like SMOTEBoost, RUSBoost, Easy Ensemble, EUSBoost, DataBoost. Experimental results show significant improvement over the other methods and it can be concluded that MEBoost is an effective and promising algorithm to deal with imbalance datasets. The python version of the code is available here: https://github.com/farshidrayhanuiu/
CUSBoost: Cluster-based Under-sampling with Boosting for Imbalanced Classification
Dec 12, 2017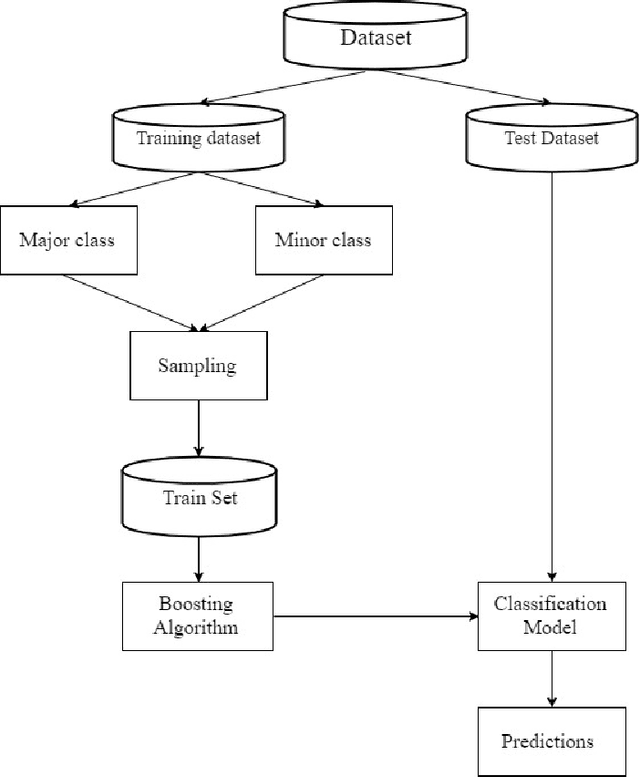


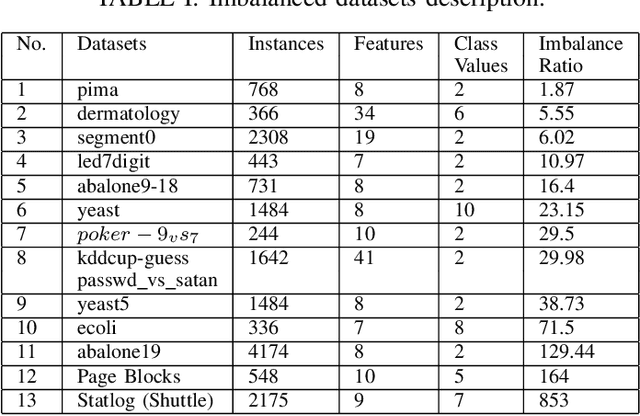
Class imbalance classification is a challenging research problem in data mining and machine learning, as most of the real-life datasets are often imbalanced in nature. Existing learning algorithms maximise the classification accuracy by correctly classifying the majority class, but misclassify the minority class. However, the minority class instances are representing the concept with greater interest than the majority class instances in real-life applications. Recently, several techniques based on sampling methods (under-sampling of the majority class and over-sampling the minority class), cost-sensitive learning methods, and ensemble learning have been used in the literature for classifying imbalanced datasets. In this paper, we introduce a new clustering-based under-sampling approach with boosting (AdaBoost) algorithm, called CUSBoost, for effective imbalanced classification. The proposed algorithm provides an alternative to RUSBoost (random under-sampling with AdaBoost) and SMOTEBoost (synthetic minority over-sampling with AdaBoost) algorithms. We evaluated the performance of CUSBoost algorithm with the state-of-the-art methods based on ensemble learning like AdaBoost, RUSBoost, SMOTEBoost on 13 imbalance binary and multi-class datasets with various imbalance ratios. The experimental results show that the CUSBoost is a promising and effective approach for dealing with highly imbalanced datasets.
LIUBoost : Locality Informed Underboosting for Imbalanced Data Classification
Nov 15, 2017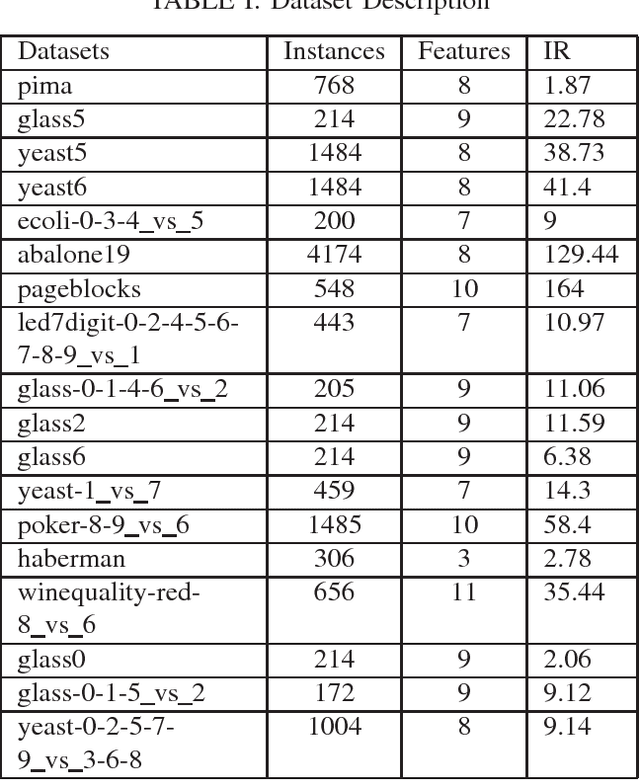



The problem of class imbalance along with class-overlapping has become a major issue in the domain of supervised learning. Most supervised learning algorithms assume equal cardinality of the classes under consideration while optimizing the cost function and this assumption does not hold true for imbalanced datasets which results in sub-optimal classification. Therefore, various approaches, such as undersampling, oversampling, cost-sensitive learning and ensemble based methods have been proposed for dealing with imbalanced datasets. However, undersampling suffers from information loss, oversampling suffers from increased runtime and potential overfitting while cost-sensitive methods suffer due to inadequately defined cost assignment schemes. In this paper, we propose a novel boosting based method called LIUBoost. LIUBoost uses under sampling for balancing the datasets in every boosting iteration like RUSBoost while incorporating a cost term for every instance based on their hardness into the weight update formula minimizing the information loss introduced by undersampling. LIUBoost has been extensively evaluated on 18 imbalanced datasets and the results indicate significant improvement over existing best performing method RUSBoost.