 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Based Feature Fusion Network for Monkeypox Skin Lesion Detection
Aug 13, 2024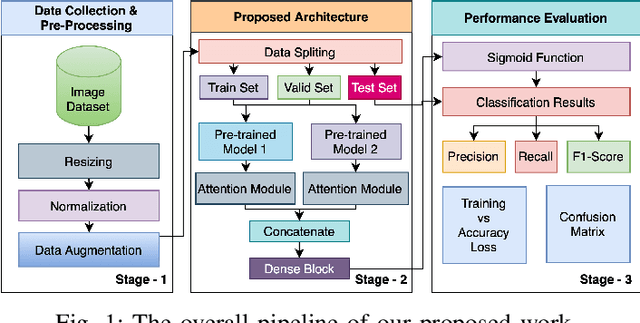
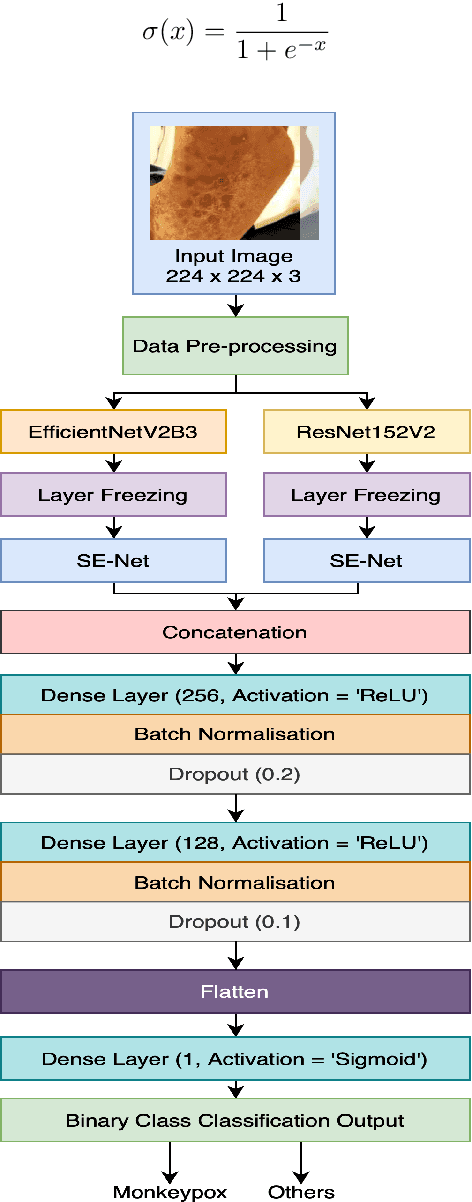
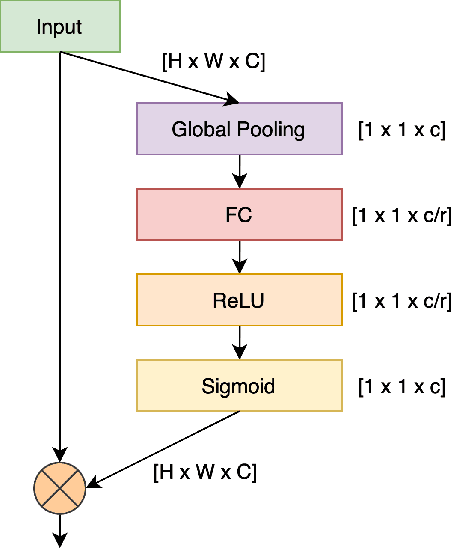
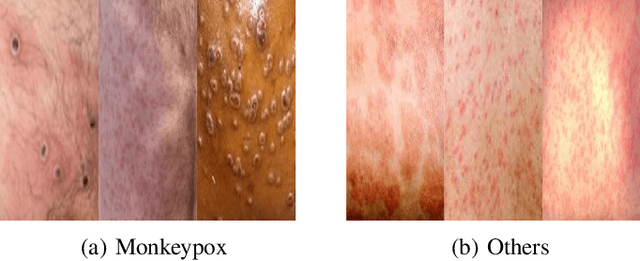
The recent monkeypox outbreak has raised significant public health concerns due to its rapid spread across multiple countries. Monkeypox can be difficult to distinguish from chickenpox and measles in the early stages because the symptoms of all three diseases are similar. Modern deep learning algorithms can be used to identify diseases, including COVID-19, by analyzing images of the affected areas. In this study, we introduce a lightweight model that merges two pre-trained architectures, EfficientNetV2B3 and ResNet151V2, to classify human monkeypox disease. We have also incorporated the squeeze-and-excitation attention network module to focus on the important parts of the feature maps for classifying the monkeypox images. This attention module provides channels and spatial attention to highlight significant areas within feature maps. We evaluated the effectiveness of our model by extensively testing it on a publicly available Monkeypox Skin Lesions Dataset using a four-fold cross-validation approach. The evaluation metrics of our model were compared with the existing others. Our model achieves a mean validation accuracy of 96.52%, with precision, recall, and F1-score values of 96.58%, 96.52%, and 96.51%, respectively.
Deep Fusion Model for Brain Tumor Classification Using Fine-Grained Gradient Preservation
Jun 28, 2024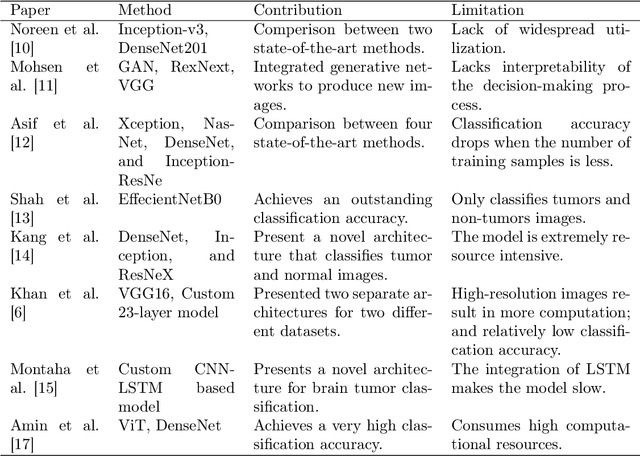
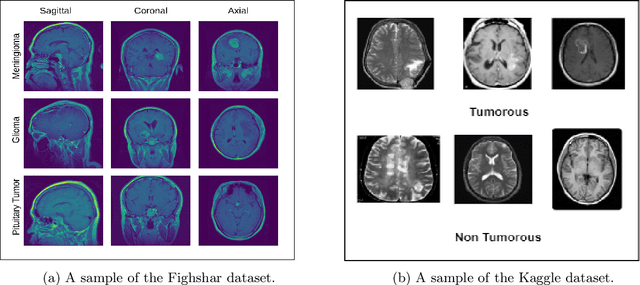
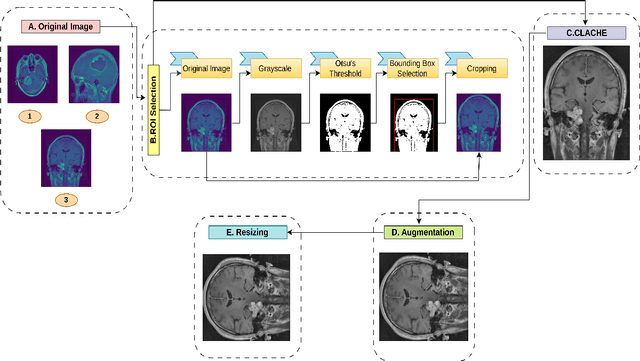
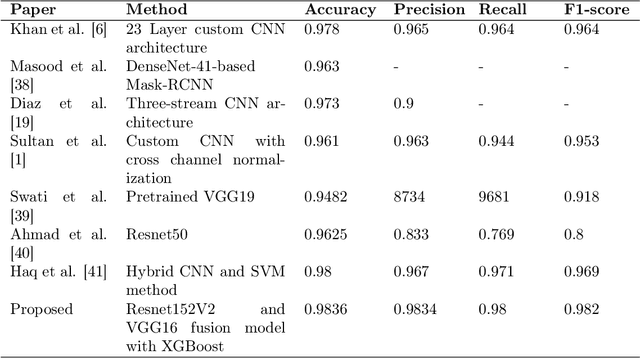
Brain tumors are one of the most common diseases that lead to early death if not diagnosed at an early stage. Traditional diagnostic approaches are extremely time-consuming and prone to errors. In this context, computer vision-based approaches have emerged as an effective tool for accurate brain tumor classification. While some of the existing solutions demonstrate noteworthy accuracy, the models become infeasible to deploy in areas where computational resources are limited. This research addresses the need for accurate and fast classification of brain tumors with a priority of deploying the model in technologically underdeveloped regions. The research presents a novel architecture for precise brain tumor classification fusing pretrained ResNet152V2 and modified VGG16 models. The proposed architecture undergoes a diligent fine-tuning process that ensures fine gradients are preserved in deep neural networks, which are essential for effective brain tumor classification. The proposed solution incorporates various image processing techniques to improve image quality and achieves an astounding accuracy of 98.36% and 98.04% in Figshare and Kaggle datasets respectively. This architecture stands out for having a streamlined profile, with only 2.8 million trainable parameters. We have leveraged 8-bit quantization to produce a model of size 73.881 MB, significantly reducing it from the previous size of 289.45 MB, ensuring smooth deployment in edge devices even in resource-constrained areas. Additionally, the use of Grad-CAM improves the interpretability of the model, offering insightful information regarding its decision-making process. Owing to its high discriminative ability, this model can be a reliable option for accurate brain tumor classification.
MEBoost: Mixing Estimators with Boosting for Imbalanced Data Classification
Jan 13, 2018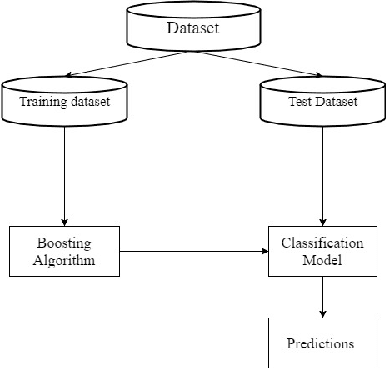
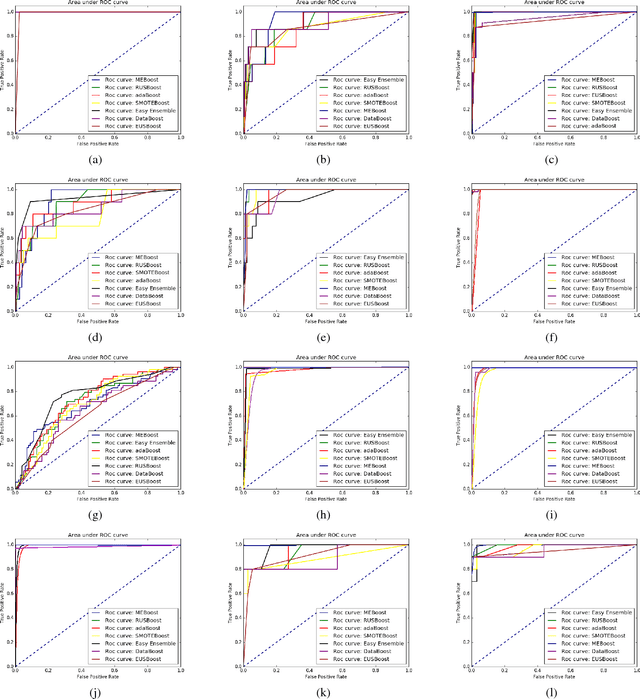
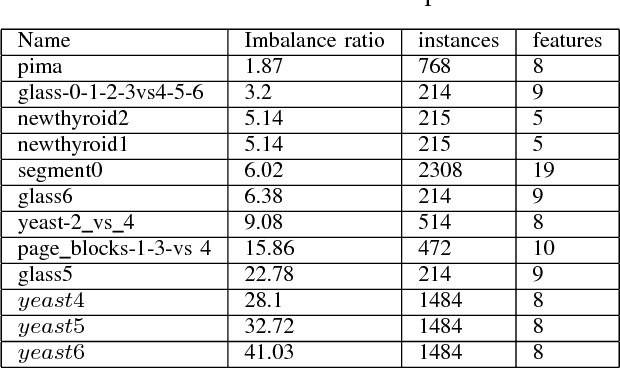
Class imbalance problem has been a challenging research problem in the fields of machine learning and data mining as most real life datasets are imbalanced. Several existing machine learning algorithms try to maximize the accuracy classification by correctly identifying majority class samples while ignoring the minority class. However, the concept of the minority class instances usually represents a higher interest than the majority class. Recently, several cost sensitive methods, ensemble models and sampling techniques have been used in literature in order to classify imbalance datasets. In this paper, we propose MEBoost, a new boosting algorithm for imbalanced datasets. MEBoost mixes two different weak learners with boosting to improve the performance on imbalanced datasets. MEBoost is an alternative to the existing techniques such as SMOTEBoost, RUSBoost, Adaboost, etc. The performance of MEBoost has been evaluated on 12 benchmark imbalanced datasets with state of the art ensemble methods like SMOTEBoost, RUSBoost, Easy Ensemble, EUSBoost, DataBoost. Experimental results show significant improvement over the other methods and it can be concluded that MEBoost is an effective and promising algorithm to deal with imbalance datasets. The python version of the code is available here: https://github.com/farshidrayhanuiu/
CUSBoost: Cluster-based Under-sampling with Boosting for Imbalanced Classification
Dec 12, 2017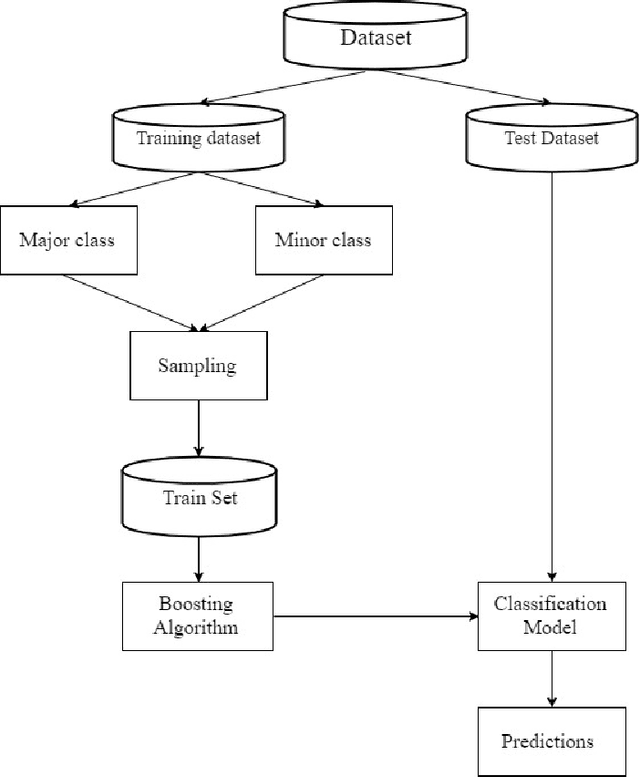


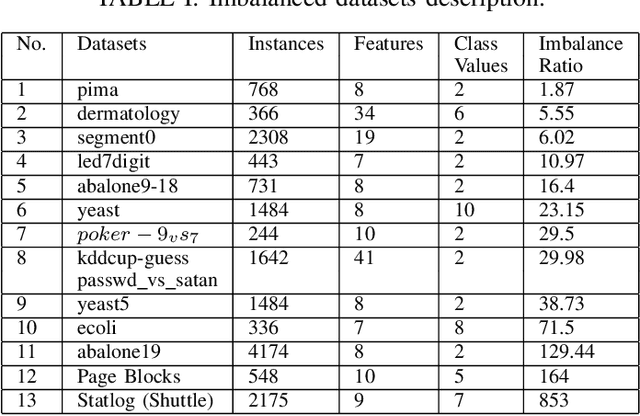
Class imbalance classification is a challenging research problem in data mining and machine learning, as most of the real-life datasets are often imbalanced in nature. Existing learning algorithms maximise the classification accuracy by correctly classifying the majority class, but misclassify the minority class. However, the minority class instances are representing the concept with greater interest than the majority class instances in real-life applications. Recently, several techniques based on sampling methods (under-sampling of the majority class and over-sampling the minority class), cost-sensitive learning methods, and ensemble learning have been used in the literature for classifying imbalanced datasets. In this paper, we introduce a new clustering-based under-sampling approach with boosting (AdaBoost) algorithm, called CUSBoost, for effective imbalanced classification. The proposed algorithm provides an alternative to RUSBoost (random under-sampling with AdaBoost) and SMOTEBoost (synthetic minority over-sampling with AdaBoost) algorithms. We evaluated the performance of CUSBoost algorithm with the state-of-the-art methods based on ensemble learning like AdaBoost, RUSBoost, SMOTEBoost on 13 imbalance binary and multi-class datasets with various imbalance ratios. The experimental results show that the CUSBoost is a promising and effective approach for dealing with highly imbalanced datasets.
LIUBoost : Locality Informed Underboosting for Imbalanced Data Classification
Nov 15, 2017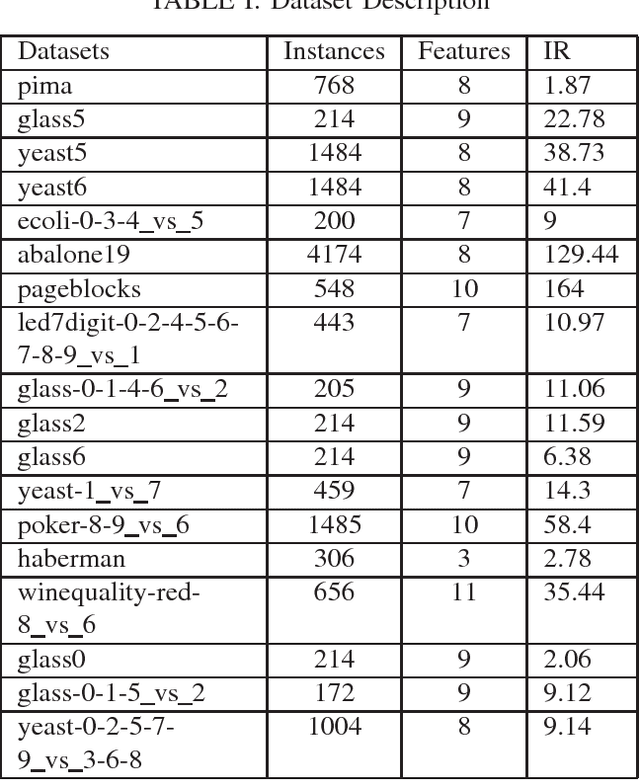



The problem of class imbalance along with class-overlapping has become a major issue in the domain of supervised learning. Most supervised learning algorithms assume equal cardinality of the classes under consideration while optimizing the cost function and this assumption does not hold true for imbalanced datasets which results in sub-optimal classification. Therefore, various approaches, such as undersampling, oversampling, cost-sensitive learning and ensemble based methods have been proposed for dealing with imbalanced datasets. However, undersampling suffers from information loss, oversampling suffers from increased runtime and potential overfitting while cost-sensitive methods suffer due to inadequately defined cost assignment schemes. In this paper, we propose a novel boosting based method called LIUBoost. LIUBoost uses under sampling for balancing the datasets in every boosting iteration like RUSBoost while incorporating a cost term for every instance based on their hardness into the weight update formula minimizing the information loss introduced by undersampling. LIUBoost has been extensively evaluated on 18 imbalanced datasets and the results indicate significant improvement over existing best performing method RUSBoost.
Combining Naive Bayes and Decision Tree for Adaptive Intrusion Detection
May 25, 2010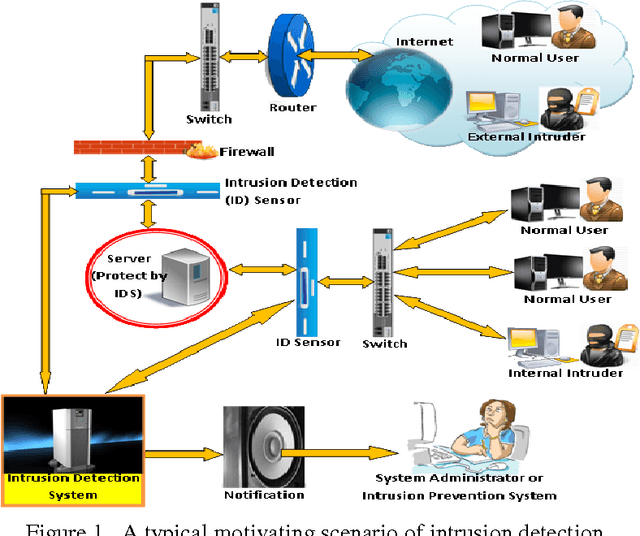


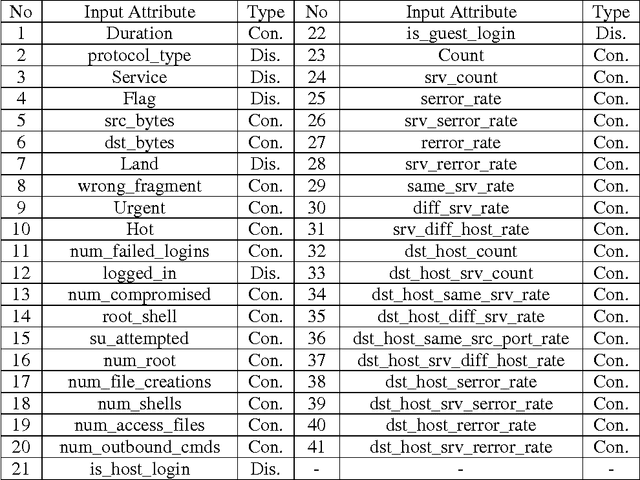
In this paper, a new learning algorithm for adaptive network intrusion detection using naive Bayesian classifier and decision tree is presented, which performs balance detections and keeps false positives at acceptable level for different types of network attacks, and eliminates redundant attributes as well as contradictory examples from training data that make the detection model complex. The proposed algorithm also addresses some difficulties of data mining such as handling continuous attribute, dealing with missing attribute values, and reducing noise in training data. Due to the large volumes of security audit data as well as the complex and dynamic properties of intrusion behaviours, several data miningbased intrusion detection techniques have been applied to network-based traffic data and host-based data in the last decades. However, there remain various issues needed to be examined towards current intrusion detection systems (IDS). We tested the performance of our proposed algorithm with existing learning algorithms by employing on the KDD99 benchmark intrusion detection dataset. The experimental results prove that the proposed algorithm achieved high detection rates (DR) and significant reduce false positives (FP) for different types of network intrusions using limited computational resources.
* 14 Pages, IJNSA