 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConMatFormer: A Multi-attention and Transformer Integrated ConvNext based Deep Learning Model for Enhanced Diabetic Foot Ulcer Classification
Oct 26, 2025Diabetic foot ulcer (DFU) detection is a clinically significant yet challenging task due to the scarcity and variability of publicly available datasets. To solve these problems, we propose ConMatFormer, a new hybrid deep learning architecture that combines ConvNeXt blocks, multiple attention mechanisms convolutional block attention module (CBAM) and dual attention network (DANet), and transformer modules in a way that works together. This design facilitates the extraction of better local features and understanding of the global context, which allows us to model small skin patterns across different types of DFU very accurately. To address the class imbalance, we used data augmentation methods. A ConvNeXt block was used to obtain detailed local features in the initial stages. Subsequently, we compiled the model by adding a transformer module to enhance long-range dependency. This enabled us to pinpoint the DFU classes that were underrepresented or constituted minorities. Tests on the DS1 (DFUC2021) and DS2 (diabetic foot ulcer (DFU)) datasets showed that ConMatFormer outperformed state-of-the-art (SOTA) convolutional neural network (CNN) and Vision Transformer (ViT) models in terms of accuracy, reliability, and flexibility. The proposed method achieved an accuracy of 0.8961 and a precision of 0.9160 in a single experiment, which is a significant improvement over the current standards for classifying DFUs. In addition, by 4-fold cross-validation, the proposed model achieved an accuracy of 0.9755 with a standard deviation of only 0.0031. We further applied explainable artificial intelligence (XAI) methods, such as Grad-CAM, Grad-CAM++, and LIME, to consistently monitor the transparency and trustworthiness of the decision-making process.. Our findings set a new benchmark for DFU classification and provide a hybrid attention transformer framework for medical image analysis.
Reinforcement-Guided Hyper-Heuristic Hyperparameter Optimization for Fair and Explainable Spiking Neural Network-Based Financial Fraud Detection
Aug 23, 2025The growing adoption of home banking systems has heightened the risk of cyberfraud, necessitating fraud detection mechanisms that are not only accurate but also fair and explainable. While AI models have shown promise in this domain, they face key limitations, including computational inefficiency, the interpretability challenges of spiking neural networks (SNNs), and the complexity and convergence instability of hyper-heuristic reinforcement learning (RL)-based hyperparameter optimization. To address these issues, we propose a novel framework that integrates a Cortical Spiking Network with Population Coding (CSNPC) and a Reinforcement-Guided Hyper-Heuristic Optimizer for Spiking Systems (RHOSS). The CSNPC, a biologically inspired SNN, employs population coding for robust classification, while RHOSS uses Q-learning to dynamically select low-level heuristics for hyperparameter optimization under fairness and recall constraints. Embedded within the Modular Supervisory Framework for Spiking Network Training and Interpretation (MoSSTI), the system incorporates explainable AI (XAI) techniques, specifically, saliency-based attribution and spike activity profiling, to increase transparency. Evaluated on the Bank Account Fraud (BAF) dataset suite, our model achieves a $90.8\%$ recall at a strict $5\%$ false positive rate (FPR), outperforming state-of-the-art spiking and non-spiking models while maintaining over $98\%$ predictive equality across key demographic attributes. The explainability module further confirms that saliency attributions align with spiking dynamics, validating interpretability. These results demonstrate the potential of combining population-coded SNNs with reinforcement-guided hyper-heuristics for fair, transparent, and high-performance fraud detection in real-world financial applications.
AdeptHEQ-FL: Adaptive Homomorphic Encryption for Federated Learning of Hybrid Classical-Quantum Models with Dynamic Layer Sparing
Jul 09, 2025Federated Learning (FL) faces inherent challenges in balancing model performance, privacy preservation, and communication efficiency, especially in non-IID decentralized environments. Recent approaches either sacrifice formal privacy guarantees, incur high overheads, or overlook quantum-enhanced expressivity. We introduce AdeptHEQ-FL, a unified hybrid classical-quantum FL framework that integrates (i) a hybrid CNN-PQC architecture for expressive decentralized learning, (ii) an adaptive accuracy-weighted aggregation scheme leveraging differentially private validation accuracies, (iii) selective homomorphic encryption (HE) for secure aggregation of sensitive model layers, and (iv) dynamic layer-wise adaptive freezing to minimize communication overhead while preserving quantum adaptability. We establish formal privacy guarantees, provide convergence analysis, and conduct extensive experiments on the CIFAR-10, SVHN, and Fashion-MNIST datasets. AdeptHEQ-FL achieves a $\approx 25.43\%$ and $\approx 14.17\%$ accuracy improvement over Standard-FedQNN and FHE-FedQNN, respectively, on the CIFAR-10 dataset. Additionally, it reduces communication overhead by freezing less important layers, demonstrating the efficiency and practicality of our privacy-preserving, resource-aware design for FL.
* Accepted in 1st International Workshop on ICCV'25 BISCUIT (Biomedical Image and Signal Computing for Unbiasedness, Interpretability, and Trustworthiness)
Vision Transformers for End-to-End Quark-Gluon Jet Classification from Calorimeter Images
Jun 17, 2025Distinguishing between quark- and gluon-initiated jets is a critical and challenging task in high-energy physics, pivotal for improving new physics searches and precision measurements at the Large Hadron Collider. While deep learning, particularly Convolutional Neural Networks (CNNs), has advanced jet tagging using image-based representations, the potential of Vision Transformer (ViT) architectures, renowned for modeling global contextual information, remains largely underexplored for direct calorimeter image analysis, especially under realistic detector and pileup conditions. This paper presents a systematic evaluation of ViTs and ViT-CNN hybrid models for quark-gluon jet classification using simulated 2012 CMS Open Data. We construct multi-channel jet-view images from detector-level energy deposits (ECAL, HCAL) and reconstructed tracks, enabling an end-to-end learning approach. Our comprehensive benchmarking demonstrates that ViT-based models, notably ViT+MaxViT and ViT+ConvNeXt hybrids, consistently outperform established CNN baselines in F1-score, ROC-AUC, and accuracy, highlighting the advantage of capturing long-range spatial correlations within jet substructure. This work establishes the first systematic framework and robust performance baselines for applying ViT architectures to calorimeter image-based jet classification using public collider data, alongside a structured dataset suitable for further deep learning research in this domain.
Co-AttenDWG: Co-Attentive Dimension-Wise Gating and Expert Fusion for Multi-Modal Offensive Content Detection
May 25, 2025Multi-modal learning has become a critical research area because integrating text and image data can significantly improve performance in tasks such as classification, retrieval, and scene understanding. However, despite progress with pre-trained models, current approaches are limited by inadequate cross-modal interactions and static fusion strategies that do not fully exploit the complementary nature of different modalities. To address these shortcomings, we introduce a novel multi-modal Co-AttenDWG architecture that leverages dual-path encoding, co-attention with dimension-wise gating, and advanced expert fusion. Our approach begins by projecting text and image features into a common embedding space, where a dedicated co-attention mechanism enables simultaneous, fine-grained interactions between modalities. This mechanism is further enhanced by a dimension-wise gating network that adaptively regulates the feature contributions at the channel level, ensuring that only the most relevant information is emphasized. In parallel, dual-path encoders refine the representations by processing cross-modal information separately before an additional cross-attention layer further aligns modalities. The refined features are then aggregated via an expert fusion module that combines learned gating and self-attention to produce a robust, unified representation. We validate our approach on the MIMIC and SemEval Memotion 1.0, where experimental results demonstrate significant improvements in cross-modal alignment and state-of-the-art performance, underscoring the potential of our model for a wide range of multi-modal applications.
MobilePlantViT: A Mobile-friendly Hybrid ViT for Generalized Plant Disease Image Classification
Mar 20, 2025Plant diseases significantly threaten global food security by reducing crop yields and undermining agricultural sustainability. AI-driven automated classification has emerged as a promising solution, with deep learning models demonstrating impressive performance in plant disease identification. However, deploying these models on mobile and edge devices remains challenging due to high computational demands and resource constraints, highlighting the need for lightweight, accurate solutions for accessible smart agriculture systems. To address this, we propose MobilePlantViT, a novel hybrid Vision Transformer (ViT) architecture designed for generalized plant disease classification, which optimizes resource efficiency while maintaining high performance. Extensive experiments across diverse plant disease datasets of varying scales show our model's effectiveness and strong generalizability, achieving test accuracies ranging from 80% to over 99%. Notably, with only 0.69 million parameters, our architecture outperforms the smallest versions of MobileViTv1 and MobileViTv2, despite their higher parameter counts. These results underscore the potential of our approach for real-world, AI-powered automated plant disease classification in sustainable and resource-efficient smart agriculture systems. All codes will be available in the GitHub repository: https://github.com/moshiurtonmoy/MobilePlantViT
Multimodal Programming in Computer Science with Interactive Assistance Powered by Large Language Model
Mar 09, 2025


LLM chatbot interfaces allow students to get instant, interactive assistance with homework, but doing so carelessly may not advance educational objectives. In this study, an interactive homework help system based on DeepSeek R1 is developed and first implemented for students enrolled in a large computer science beginning programming course. In addition to an assist button in a well-known code editor, our assistant also has a feedback option in our command-line automatic evaluator. It wraps student work in a personalized prompt that advances our educational objectives without offering answers straight away. We have discovered that our assistant can recognize students' conceptual difficulties and provide ideas, plans, and template code in pedagogically appropriate ways. However, among other mistakes, it occasionally incorrectly labels the correct student code as incorrect or encourages students to use correct-but-lesson-inappropriate approaches, which can lead to long and frustrating journeys for the students. After discussing many development and deployment issues, we provide our conclusions and future actions.
Soybean Disease Detection via Interpretable Hybrid CNN-GNN: Integrating MobileNetV2 and GraphSAGE with Cross-Modal Attention
Mar 03, 2025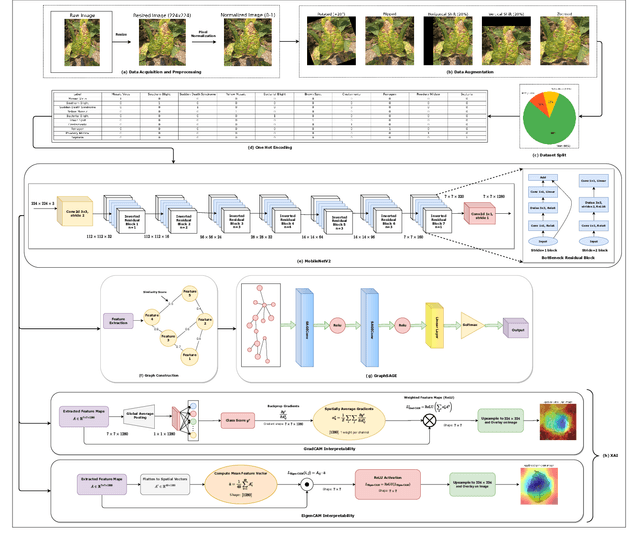
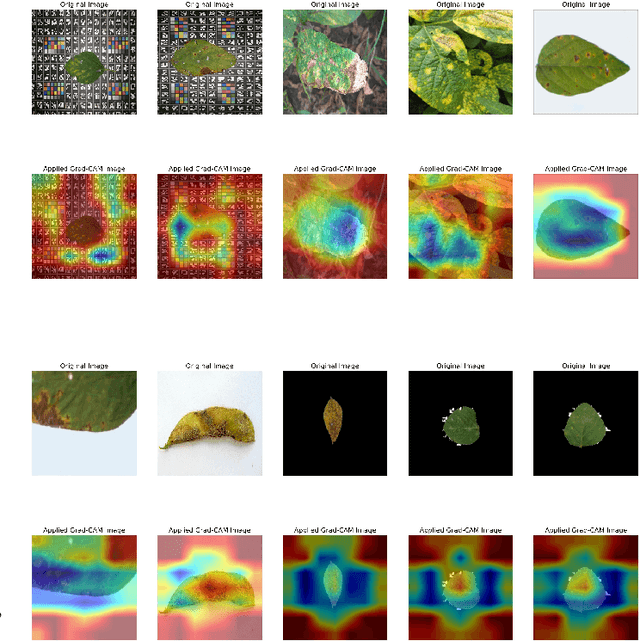
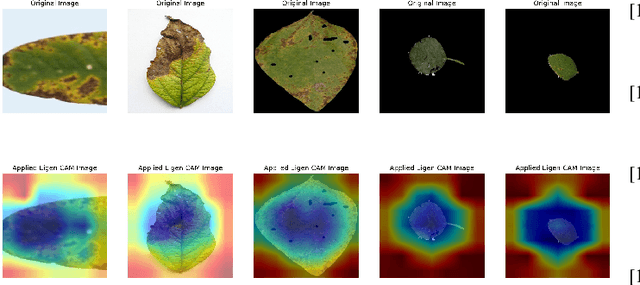
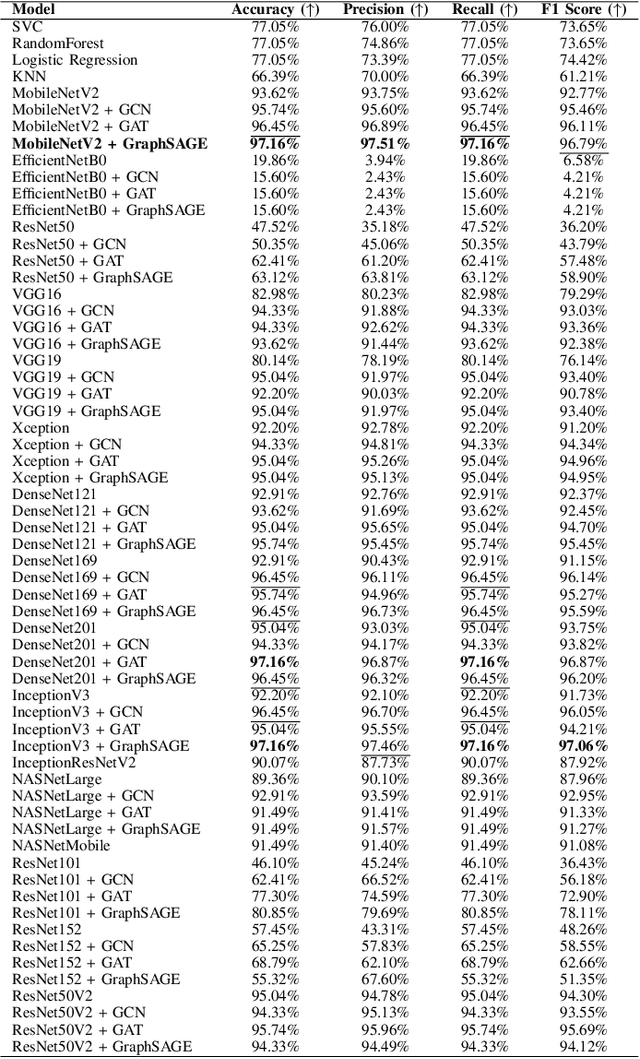
Soybean leaf disease detection is critical for agricultural productivity but faces challenges due to visually similar symptoms and limited interpretability in conventional methods. While Convolutional Neural Networks (CNNs) excel in spatial feature extraction, they often neglect inter-image relational dependencies, leading to misclassifications. This paper proposes an interpretable hybrid Sequential CNN-Graph Neural Network (GNN) framework that synergizes MobileNetV2 for localized feature extraction and GraphSAGE for relational modeling. The framework constructs a graph where nodes represent leaf images, with edges defined by cosine similarity-based adjacency matrices and adaptive neighborhood sampling. This design captures fine-grained lesion features and global symptom patterns, addressing inter-class similarity challenges. Cross-modal interpretability is achieved via Grad-CAM and Eigen-CAM visualizations, generating heatmaps to highlight disease-influential regions. Evaluated on a dataset of ten soybean leaf diseases, the model achieves $97.16\%$ accuracy, surpassing standalone CNNs ($\le95.04\%$) and traditional machine learning models ($\le77.05\%$). Ablation studies validate the sequential architecture's superiority over parallel or single-model configurations. With only 2.3 million parameters, the lightweight MobileNetV2-GraphSAGE combination ensures computational efficiency, enabling real-time deployment in resource-constrained environments. The proposed approach bridges the gap between accurate classification and practical applicability, offering a robust, interpretable tool for agricultural diagnostics while advancing CNN-GNN integration in plant pathology research.
CAGN-GAT Fusion: A Hybrid Contrastive Attentive Graph Neural Network for Network Intrusion Detection
Mar 02, 2025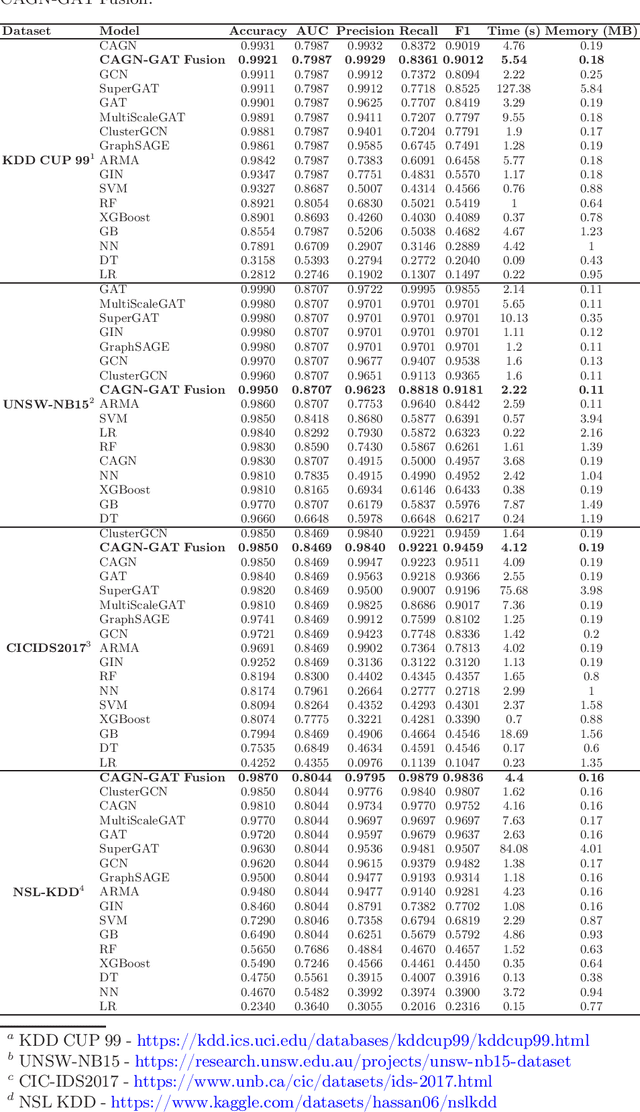
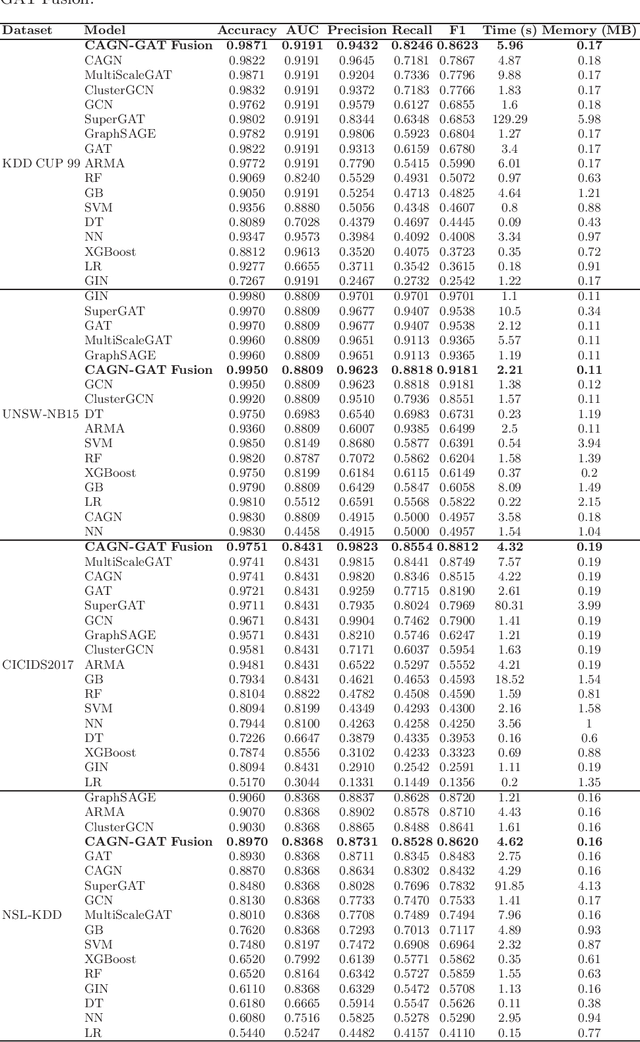
Cybersecurity threats are growing, making network intrusion detection essential. Traditional machine learning models remain effective in resource-limited environments due to their efficiency, requiring fewer parameters and less computational time. However, handling short and highly imbalanced datasets remains challenging. In this study, we propose the fusion of a Contrastive Attentive Graph Network and Graph Attention Network (CAGN-GAT Fusion) and benchmark it against 15 other models, including both Graph Neural Networks (GNNs) and traditional ML models. Our evaluation is conducted on four benchmark datasets (KDD-CUP-1999, NSL-KDD, UNSW-NB15, and CICIDS2017) using a short and proportionally imbalanced dataset with a constant size of 5000 samples to ensure fairness in comparison. Results show that CAGN-GAT Fusion demonstrates stable and competitive accuracy, recall, and F1-score, even though it does not achieve the highest performance in every dataset. Our analysis also highlights the impact of adaptive graph construction techniques, including small changes in connections (edge perturbation) and selective hiding of features (feature masking), improving detection performance. The findings confirm that GNNs, particularly CAGN-GAT Fusion, are robust and computationally efficient, making them well-suited for resource-constrained environments. Future work will explore GraphSAGE layers and multiview graph construction techniques to further enhance adaptability and detection accuracy.
From Images to Insights: Transforming Brain Cancer Diagnosis with Explainable AI
Jan 09, 2025
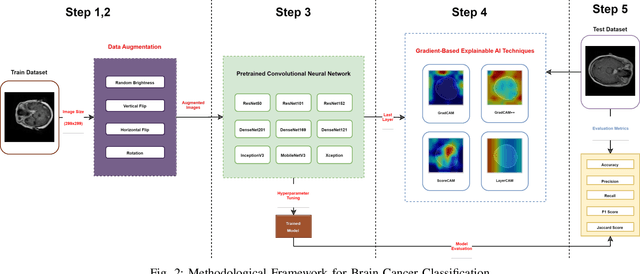


Brain cancer represents a major challenge in medical diagnostics, requisite precise and timely detection for effective treatment. Diagnosis initially relies on the proficiency of radiologists, which can cause difficulties and threats when the expertise is sparse. Despite the use of imaging resources, brain cancer remains often difficult, time-consuming, and vulnerable to intraclass variability. This study conveys the Bangladesh Brain Cancer MRI Dataset, containing 6,056 MRI images organized into three categories: Brain Tumor, Brain Glioma, and Brain Menin. The dataset was collected from several hospitals in Bangladesh, providing a diverse and realistic sample for research. We implemented advanced deep learning models, and DenseNet169 achieved exceptional results, with accuracy, precision, recall, and F1-Score all reaching 0.9983. In addition, Explainable AI (XAI) methods including GradCAM, GradCAM++, ScoreCAM, and LayerCAM were employed to provide visual representations of the decision-making processes of the models. In the context of brain cancer, these techniques highlight DenseNet169's potential to enhance diagnostic accuracy while simultaneously offering transparency, facilitating early diagnosis and better patient outcomes.