 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAGN-GAT Fusion: A Hybrid Contrastive Attentive Graph Neural Network for Network Intrusion Detection
Mar 02, 2025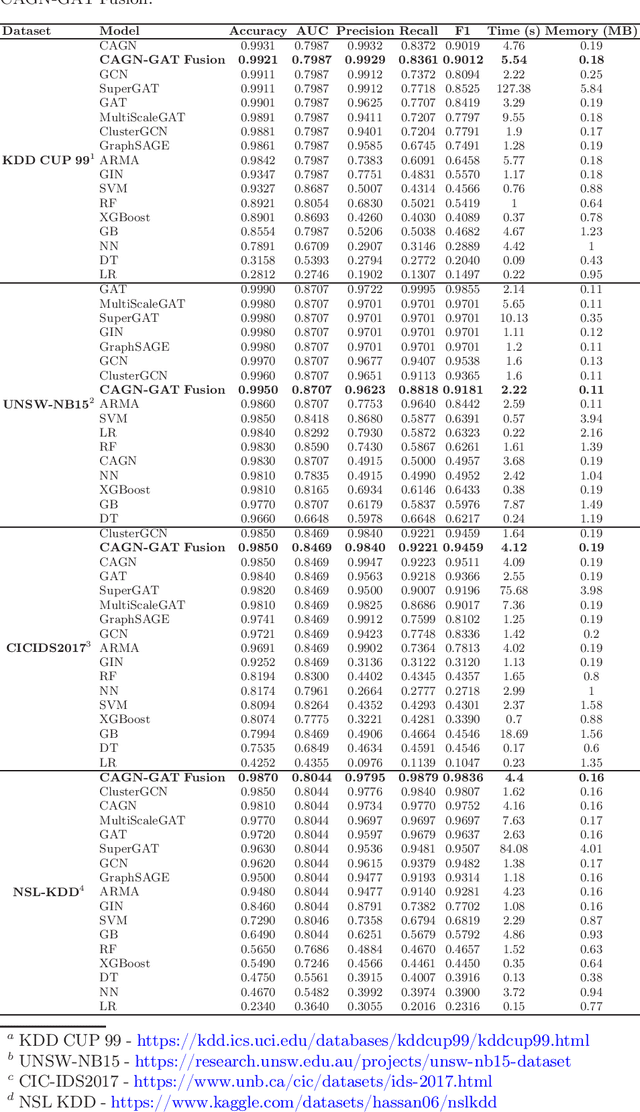
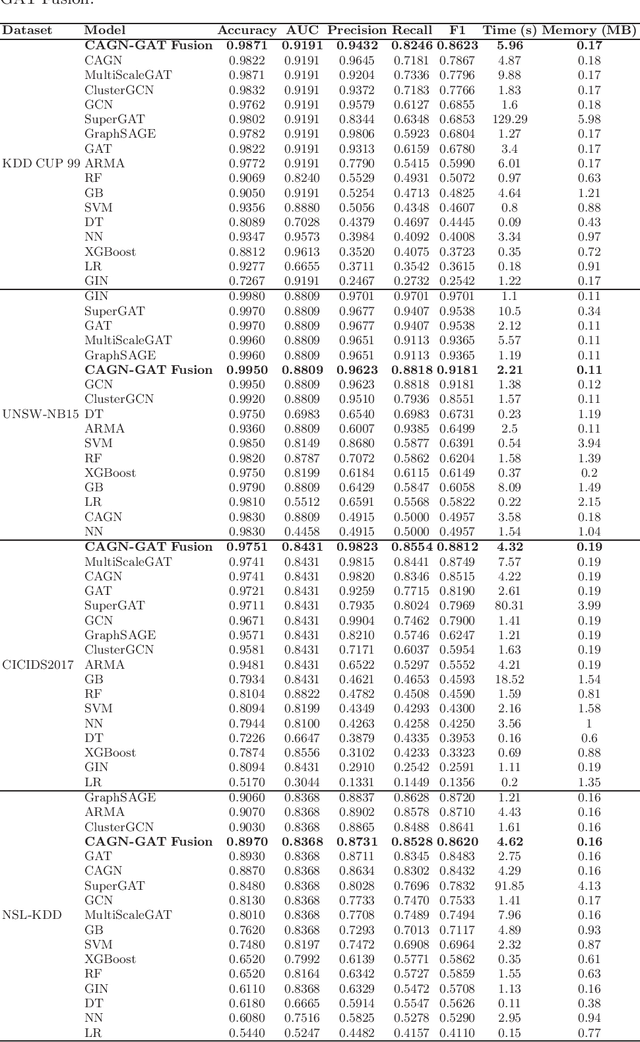
Cybersecurity threats are growing, making network intrusion detection essential. Traditional machine learning models remain effective in resource-limited environments due to their efficiency, requiring fewer parameters and less computational time. However, handling short and highly imbalanced datasets remains challenging. In this study, we propose the fusion of a Contrastive Attentive Graph Network and Graph Attention Network (CAGN-GAT Fusion) and benchmark it against 15 other models, including both Graph Neural Networks (GNNs) and traditional ML models. Our evaluation is conducted on four benchmark datasets (KDD-CUP-1999, NSL-KDD, UNSW-NB15, and CICIDS2017) using a short and proportionally imbalanced dataset with a constant size of 5000 samples to ensure fairness in comparison. Results show that CAGN-GAT Fusion demonstrates stable and competitive accuracy, recall, and F1-score, even though it does not achieve the highest performance in every dataset. Our analysis also highlights the impact of adaptive graph construction techniques, including small changes in connections (edge perturbation) and selective hiding of features (feature masking), improving detection performance. The findings confirm that GNNs, particularly CAGN-GAT Fusion, are robust and computationally efficient, making them well-suited for resource-constrained environments. Future work will explore GraphSAGE layers and multiview graph construction techniques to further enhance adaptability and detection accuracy.
A Comprehensive Survey on Visual Question Answering Datasets and Algorithms
Nov 17, 2024



Visual question answering (VQA) refers to the problem where, given an image and a natural language question about the image, a correct natural language answer has to be generated. A VQA model has to demonstrate both the visual understanding of the image and the semantic understanding of the question, demonstrating reasoning capability. Since the inception of this field, a plethora of VQA datasets and models have been published. In this article, we meticulously analyze the current state of VQA datasets and models, while cleanly dividing them into distinct categories and then summarizing the methodologies and characteristics of each category. We divide VQA datasets into four categories: (1) available datasets that contain a rich collection of authentic images, (2) synthetic datasets that contain only synthetic images produced through artificial means, (3) diagnostic datasets that are specially designed to test model performance in a particular area, e.g., understanding the scene text, and (4) KB (Knowledge-Based) datasets that are designed to measure a model's ability to utilize outside knowledge. Concurrently, we explore six main paradigms of VQA models: fusion, where we discuss different methods of fusing information between visual and textual modalities; attention, the technique of using information from one modality to filter information from another; external knowledge base, where we discuss different models utilizing outside information; composition or reasoning, where we analyze techniques to answer advanced questions that require complex reasoning steps; explanation, which is the process of generating visual and textual descriptions to verify sound reasoning; and graph models, which encode and manipulate relationships through nodes in a graph. We also discuss some miscellaneous topics, such as scene text understanding, counting, and bias reduction.
Enhanced Robot Motion Block of A-star Algorithm for Robotic Path Planning
Dec 25, 2023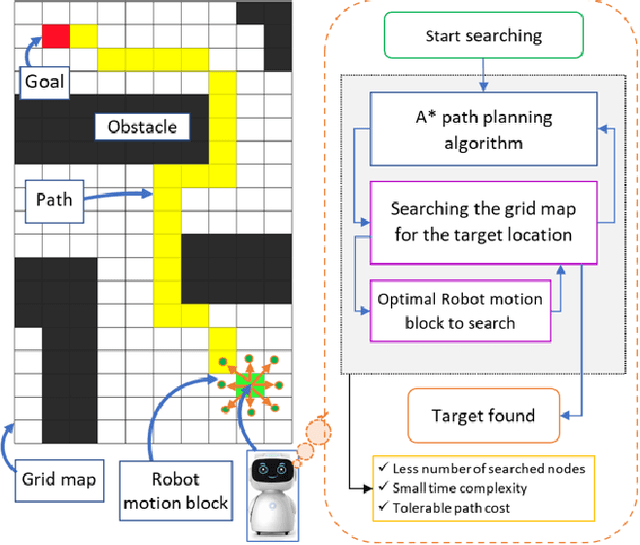
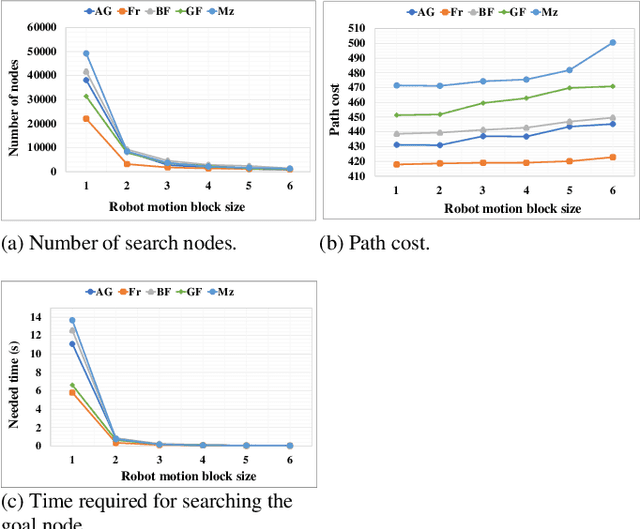

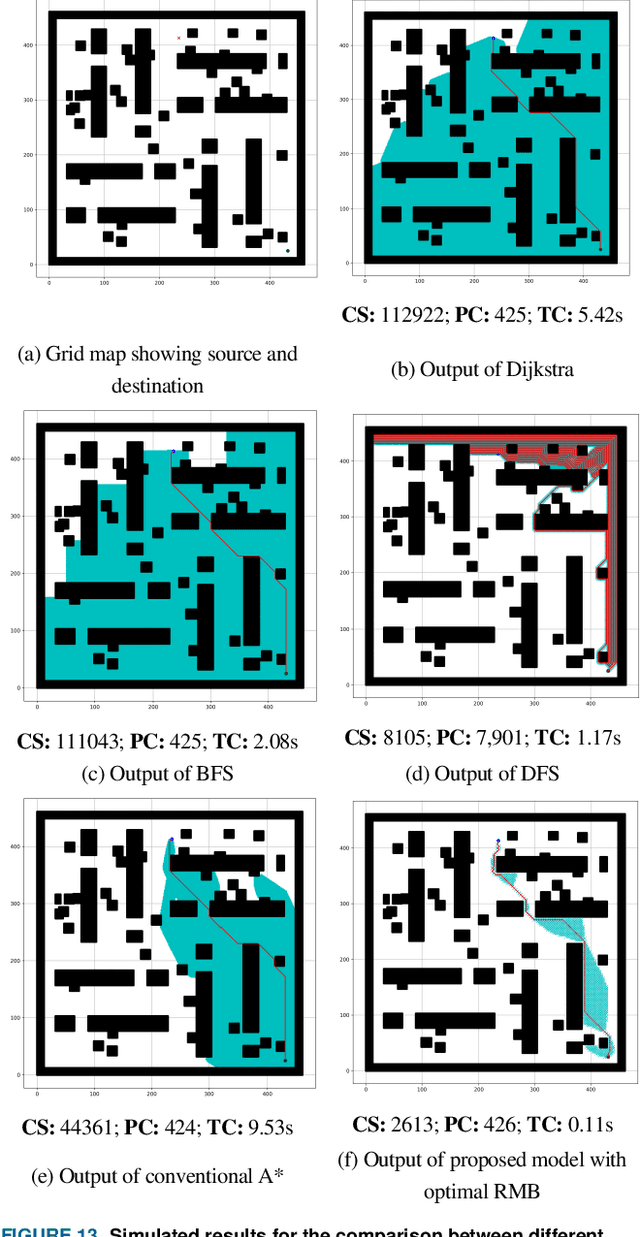
An efficient robot path-planning model is vulnerable to the number of search nodes, path cost, and time complexity. The conventional A-star (A*) algorithm outperforms other grid-based algorithms for its heuristic search. However it shows suboptimal performance for the time, space, and number of search nodes, depending on the robot motion block (RMB). To address this challenge, this study proposes an optimal RMB for the A* path-planning algorithm to enhance the performance, where the robot movement costs are calculated by the proposed adaptive cost function. Also, a selection process is proposed to select the optimal RMB size. In this proposed model, grid-based maps are used, where the robot's next move is determined based on the adaptive cost function by searching among surrounding octet neighborhood grid cells. The cumulative value from the output data arrays is used to determine the optimal motion block size, which is formulated based on parameters. The proposed RMB significantly affects the searching time complexity and number of search nodes of the A* algorithm while maintaining almost the same path cost to find the goal position by avoiding obstacles. For the experiment, a benchmarked online dataset is used and prepared three different dimensional maps. The proposed approach is validated using approximately 7000 different grid maps with various dimensions and obstacle environments. The proposed model with an optimal RMB demonstrated a remarkable improvement of 93.98% in the number of search cells and 98.94% in time complexity compared to the conventional A* algorithm. Path cost for the proposed model remained largely comparable to other state-of-the-art algorithms. Also, the proposed model outperforms other state-of-the-art algorithms.