 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Robot Motion Block of A-star Algorithm for Robotic Path Planning
Dec 25, 2023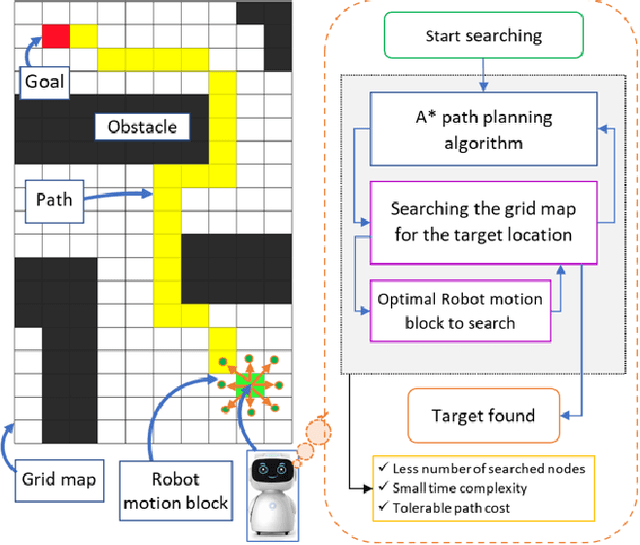
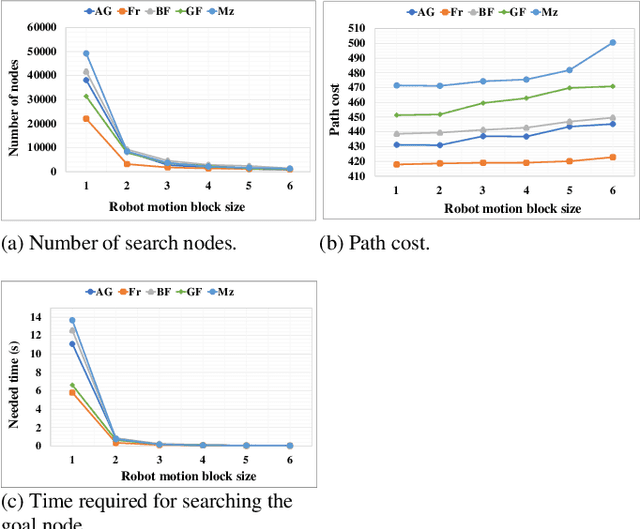

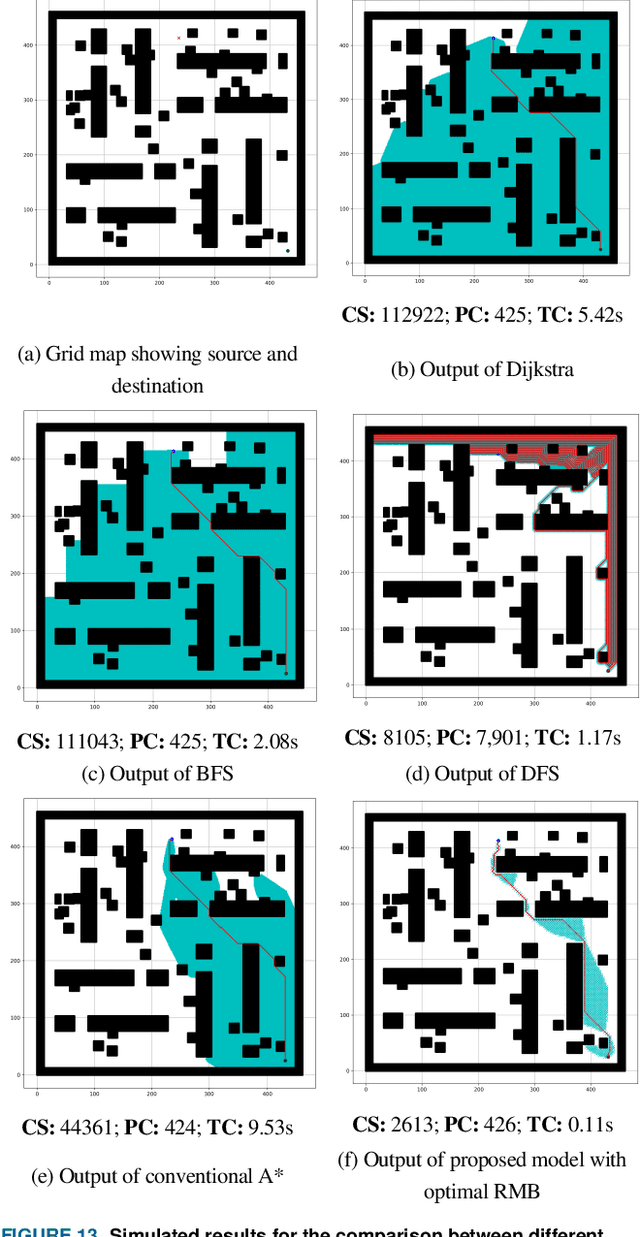
An efficient robot path-planning model is vulnerable to the number of search nodes, path cost, and time complexity. The conventional A-star (A*) algorithm outperforms other grid-based algorithms for its heuristic search. However it shows suboptimal performance for the time, space, and number of search nodes, depending on the robot motion block (RMB). To address this challenge, this study proposes an optimal RMB for the A* path-planning algorithm to enhance the performance, where the robot movement costs are calculated by the proposed adaptive cost function. Also, a selection process is proposed to select the optimal RMB size. In this proposed model, grid-based maps are used, where the robot's next move is determined based on the adaptive cost function by searching among surrounding octet neighborhood grid cells. The cumulative value from the output data arrays is used to determine the optimal motion block size, which is formulated based on parameters. The proposed RMB significantly affects the searching time complexity and number of search nodes of the A* algorithm while maintaining almost the same path cost to find the goal position by avoiding obstacles. For the experiment, a benchmarked online dataset is used and prepared three different dimensional maps. The proposed approach is validated using approximately 7000 different grid maps with various dimensions and obstacle environments. The proposed model with an optimal RMB demonstrated a remarkable improvement of 93.98% in the number of search cells and 98.94% in time complexity compared to the conventional A* algorithm. Path cost for the proposed model remained largely comparable to other state-of-the-art algorithms. Also, the proposed model outperforms other state-of-the-art algorithms.
Reduction of Overfitting in Diabetes Prediction Using Deep Learning Neural Network
Jul 26, 2017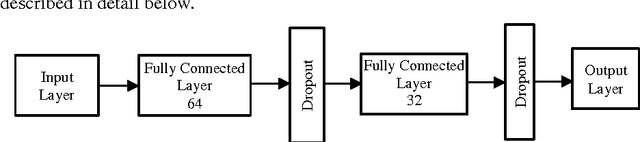
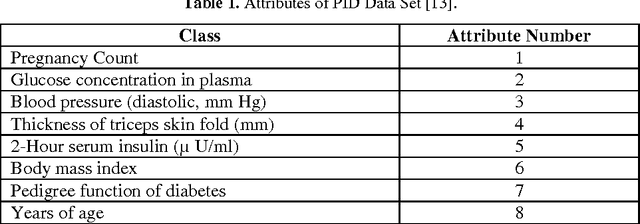
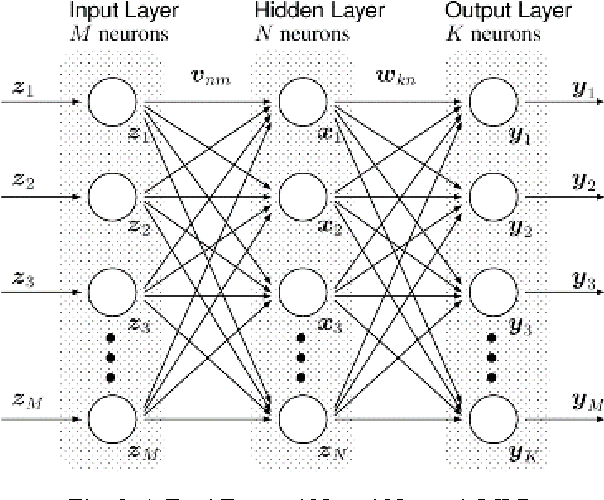
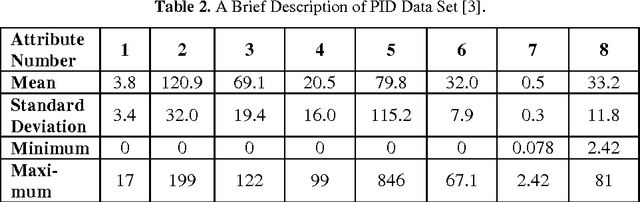
Augmented accuracy in prediction of diabetes will open up new frontiers in health prognostics. Data overfitting is a performance-degrading issue in diabetes prognosis. In this study, a prediction system for the disease of diabetes is pre-sented where the issue of overfitting is minimized by using the dropout method. Deep learning neural network is used where both fully connected layers are fol-lowed by dropout layers. The output performance of the proposed neural network is shown to have outperformed other state-of-art methods and it is recorded as by far the best performance for the Pima Indians Diabetes Data Set.
A Novel Transfer Learning Approach upon Hindi, Arabic, and Bangla Numerals using Convolutional Neural Networks
Jul 26, 2017
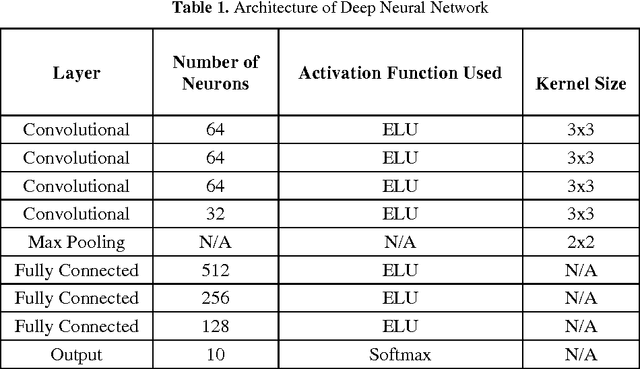

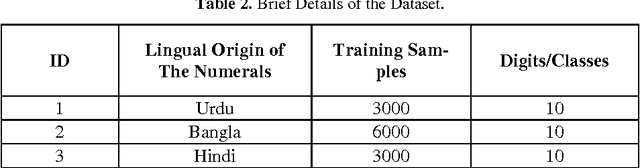
Increased accuracy in predictive models for handwritten character recognition will open up new frontiers for optical character recognition. Major drawbacks of predictive machine learning models are headed by the elongated training time taken by some models, and the requirement that training and test data be in the same feature space and consist of the same distribution. In this study, these obstacles are minimized by presenting a model for transferring knowledge from one task to another. This model is presented for the recognition of handwritten numerals in Indic languages. The model utilizes convolutional neural networks with backpropagation for error reduction and dropout for data overfitting. The output performance of the proposed neural network is shown to have closely matched other state-of-the-art methods using only a fraction of time used by the state-of-the-arts.