 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Education and Research: An Empirical and User Survey-based Analysis
Dec 08, 2025Pretrained Large Language Models (LLMs) have achieved remarkable success across diverse domains, with education and research emerging as particularly impactful areas. Among current state-of-the-art LLMs, ChatGPT and DeepSeek exhibit strong capabilities in mathematics, science, medicine, literature, and programming. In this study, we present a comprehensive evaluation of these two LLMs through background technology analysis, empirical experiments, and a real-world user survey. The evaluation explores trade-offs among model accuracy, computational efficiency, and user experience in educational and research affairs. We benchmarked these LLMs performance in text generation, programming, and specialized problem-solving. Experimental results show that ChatGPT excels in general language understanding and text generation, while DeepSeek demonstrates superior performance in programming tasks due to its efficiency-focused design. Moreover, both models deliver medically accurate diagnostic outputs and effectively solve complex mathematical problems. Complementing these quantitative findings, a survey of students, educators, and researchers highlights the practical benefits and limitations of these models, offering deeper insights into their role in advancing education and research.
CAGN-GAT Fusion: A Hybrid Contrastive Attentive Graph Neural Network for Network Intrusion Detection
Mar 02, 2025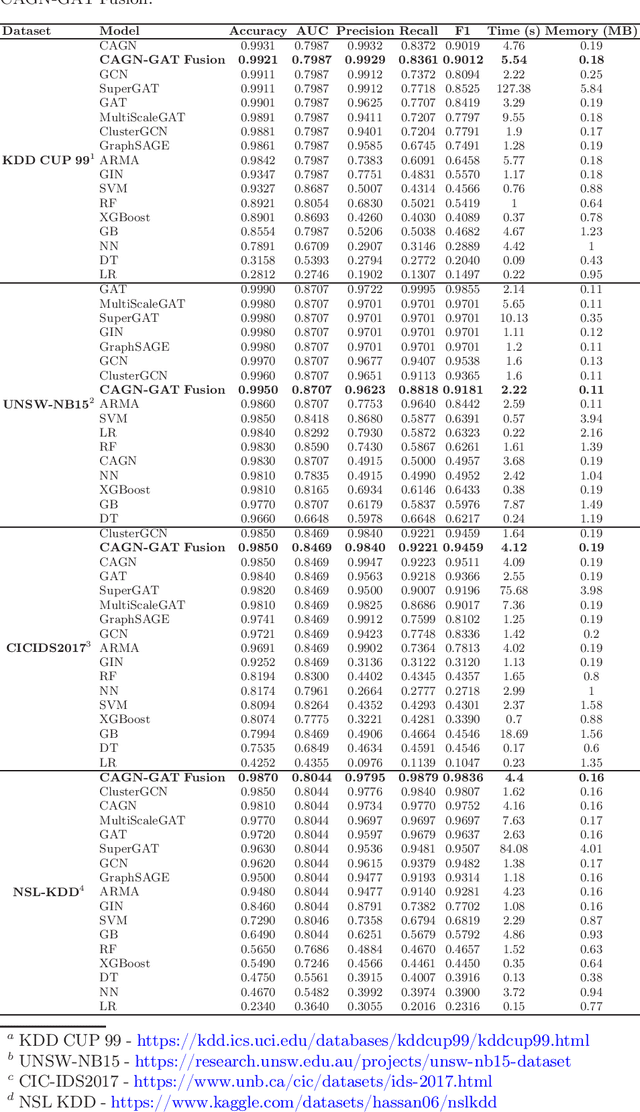
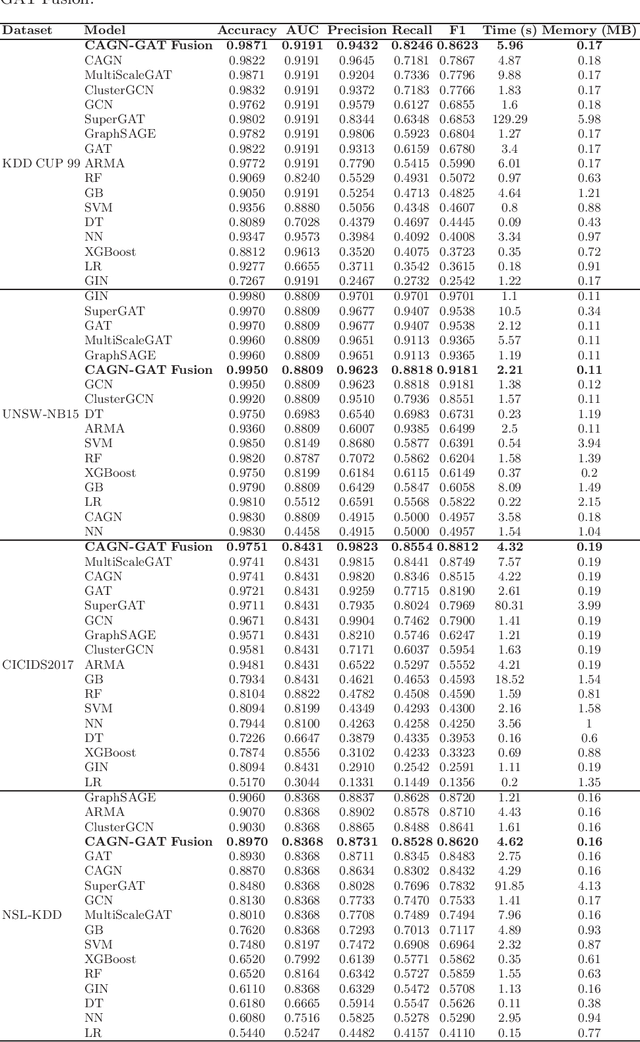
Cybersecurity threats are growing, making network intrusion detection essential. Traditional machine learning models remain effective in resource-limited environments due to their efficiency, requiring fewer parameters and less computational time. However, handling short and highly imbalanced datasets remains challenging. In this study, we propose the fusion of a Contrastive Attentive Graph Network and Graph Attention Network (CAGN-GAT Fusion) and benchmark it against 15 other models, including both Graph Neural Networks (GNNs) and traditional ML models. Our evaluation is conducted on four benchmark datasets (KDD-CUP-1999, NSL-KDD, UNSW-NB15, and CICIDS2017) using a short and proportionally imbalanced dataset with a constant size of 5000 samples to ensure fairness in comparison. Results show that CAGN-GAT Fusion demonstrates stable and competitive accuracy, recall, and F1-score, even though it does not achieve the highest performance in every dataset. Our analysis also highlights the impact of adaptive graph construction techniques, including small changes in connections (edge perturbation) and selective hiding of features (feature masking), improving detection performance. The findings confirm that GNNs, particularly CAGN-GAT Fusion, are robust and computationally efficient, making them well-suited for resource-constrained environments. Future work will explore GraphSAGE layers and multiview graph construction techniques to further enhance adaptability and detection accuracy.
RoBERTa-BiLSTM: A Context-Aware Hybrid Model for Sentiment Analysis
Jun 01, 2024Effectively analyzing the comments to uncover latent intentions holds immense value in making strategic decisions across various domains. However, several challenges hinder the process of sentiment analysis including the lexical diversity exhibited in comments, the presence of long dependencies within the text, encountering unknown symbols and words, and dealing with imbalanced datasets. Moreover, existing sentiment analysis tasks mostly leveraged sequential models to encode the long dependent texts and it requires longer execution time as it processes the text sequentially. In contrast, the Transformer requires less execution time due to its parallel processing nature. In this work, we introduce a novel hybrid deep learning model, RoBERTa-BiLSTM, which combines the Robustly Optimized BERT Pretraining Approach (RoBERTa) with Bidirectional Long Short-Term Memory (BiLSTM) networks. RoBERTa is utilized to generate meaningful word embedding vectors, while BiLSTM effectively captures the contextual semantics of long-dependent texts. The RoBERTa-BiLSTM hybrid model leverages the strengths of both sequential and Transformer models to enhance performance in sentiment analysis. We conducted experiments using datasets from IMDb, Twitter US Airline, and Sentiment140 to evaluate the proposed model against existing state-of-the-art methods. Our experimental findings demonstrate that the RoBERTa-BiLSTM model surpasses baseline models (e.g., BERT, RoBERTa-base, RoBERTa-GRU, and RoBERTa-LSTM), achieving accuracies of 80.74%, 92.36%, and 82.25% on the Twitter US Airline, IMDb, and Sentiment140 datasets, respectively. Additionally, the model achieves F1-scores of 80.73%, 92.35%, and 82.25% on the same datasets, respectively.
Enhanced Robot Motion Block of A-star Algorithm for Robotic Path Planning
Dec 25, 2023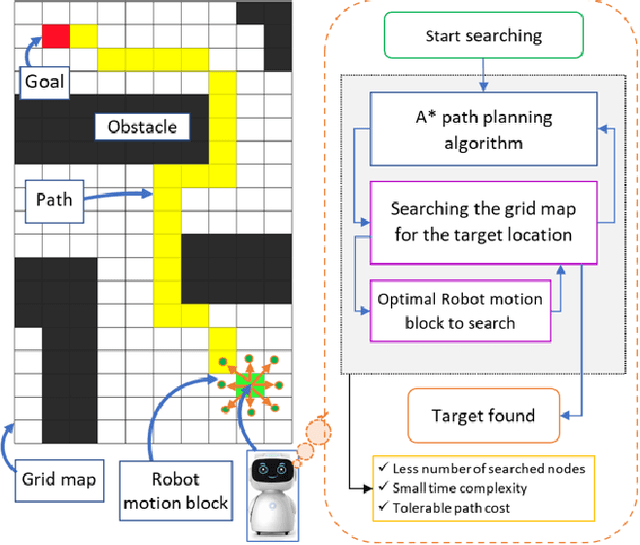
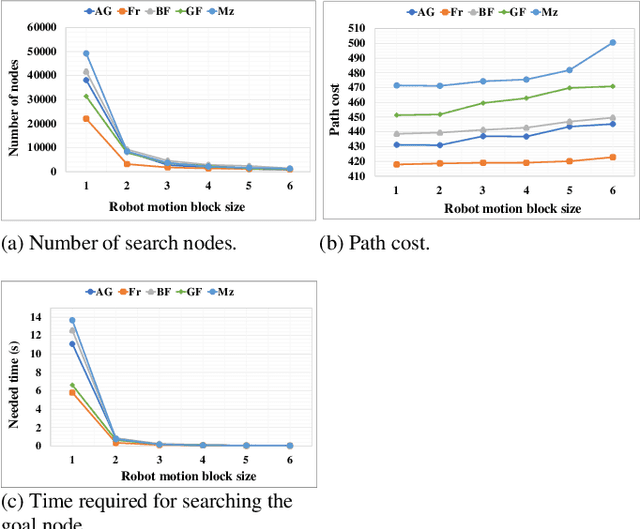

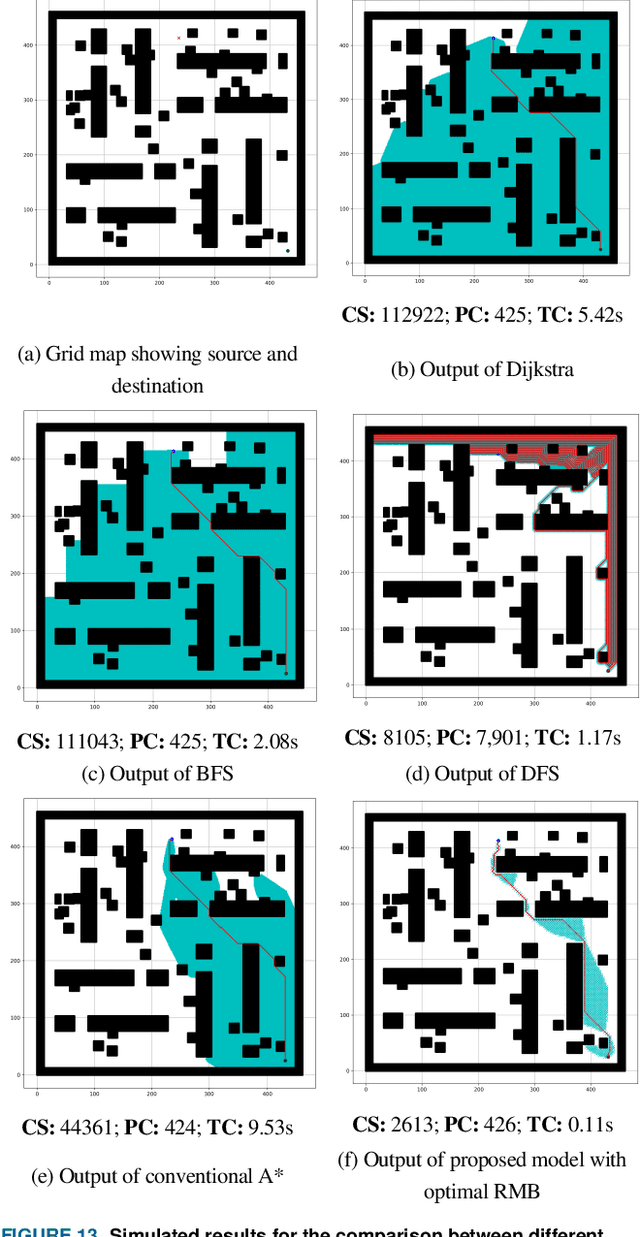
An efficient robot path-planning model is vulnerable to the number of search nodes, path cost, and time complexity. The conventional A-star (A*) algorithm outperforms other grid-based algorithms for its heuristic search. However it shows suboptimal performance for the time, space, and number of search nodes, depending on the robot motion block (RMB). To address this challenge, this study proposes an optimal RMB for the A* path-planning algorithm to enhance the performance, where the robot movement costs are calculated by the proposed adaptive cost function. Also, a selection process is proposed to select the optimal RMB size. In this proposed model, grid-based maps are used, where the robot's next move is determined based on the adaptive cost function by searching among surrounding octet neighborhood grid cells. The cumulative value from the output data arrays is used to determine the optimal motion block size, which is formulated based on parameters. The proposed RMB significantly affects the searching time complexity and number of search nodes of the A* algorithm while maintaining almost the same path cost to find the goal position by avoiding obstacles. For the experiment, a benchmarked online dataset is used and prepared three different dimensional maps. The proposed approach is validated using approximately 7000 different grid maps with various dimensions and obstacle environments. The proposed model with an optimal RMB demonstrated a remarkable improvement of 93.98% in the number of search cells and 98.94% in time complexity compared to the conventional A* algorithm. Path cost for the proposed model remained largely comparable to other state-of-the-art algorithms. Also, the proposed model outperforms other state-of-the-art algorithms.
Refactoring Programs Using Large Language Models with Few-Shot Examples
Nov 20, 2023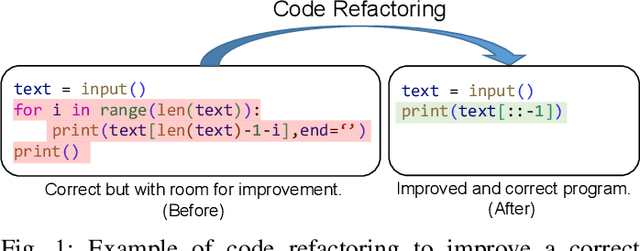
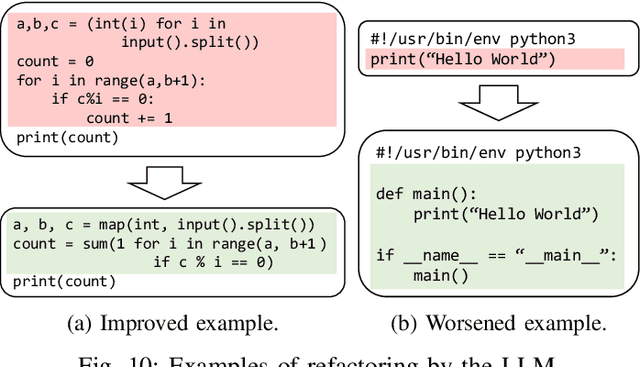

A less complex and more straightforward program is a crucial factor that enhances its maintainability and makes writing secure and bug-free programs easier. However, due to its heavy workload and the risks of breaking the working programs, programmers are reluctant to do code refactoring, and thus, it also causes the loss of potential learning experiences. To mitigate this, we demonstrate the application of using a large language model (LLM), GPT-3.5, to suggest less complex versions of the user-written Python program, aiming to encourage users to learn how to write better programs. We propose a method to leverage the prompting with few-shot examples of the LLM by selecting the best-suited code refactoring examples for each target programming problem based on the prior evaluation of prompting with the one-shot example. The quantitative evaluation shows that 95.68% of programs can be refactored by generating 10 candidates each, resulting in a 17.35% reduction in the average cyclomatic complexity and a 25.84% decrease in the average number of lines after filtering only generated programs that are semantically correct. Furthermore, the qualitative evaluation shows outstanding capability in code formatting, while unnecessary behaviors such as deleting or translating comments are also observed.
Rule-Based Error Classification for Analyzing Differences in Frequent Errors
Nov 01, 2023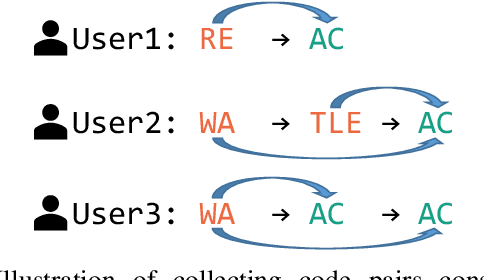
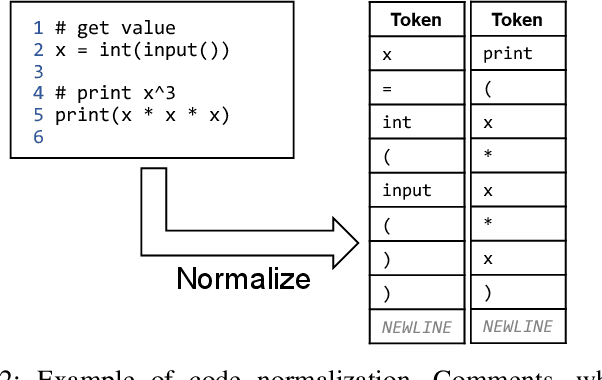
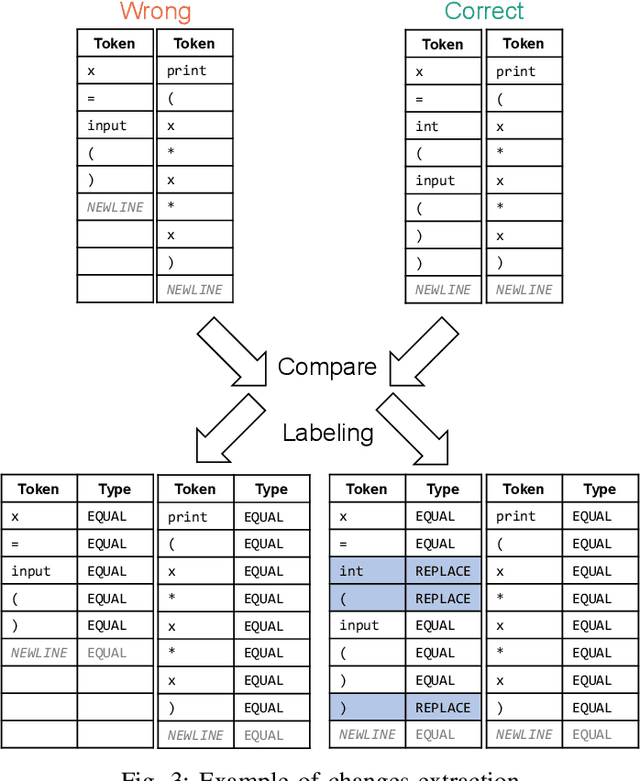

Finding and fixing errors is a time-consuming task not only for novice programmers but also for expert programmers. Prior work has identified frequent error patterns among various levels of programmers. However, the differences in the tendencies between novices and experts have yet to be revealed. From the knowledge of the frequent errors in each level of programmers, instructors will be able to provide helpful advice for each level of learners. In this paper, we propose a rule-based error classification tool to classify errors in code pairs consisting of wrong and correct programs. We classify errors for 95,631 code pairs and identify 3.47 errors on average, which are submitted by various levels of programmers on an online judge system. The classified errors are used to analyze the differences in frequent errors between novice and expert programmers. The analyzed results show that, as for the same introductory problems, errors made by novices are due to the lack of knowledge in programming, and the mistakes are considered an essential part of the learning process. On the other hand, errors made by experts are due to misunderstandings caused by the carelessness of reading problems or the challenges of solving problems differently than usual. The proposed tool can be used to create error-labeled datasets and for further code-related educational research.
Program Repair with Minimal Edits Using CodeT5
Sep 26, 2023Programmers often struggle to identify and fix bugs in their programs. In recent years, many language models (LMs) have been proposed to fix erroneous programs and support error recovery. However, the LMs tend to generate solutions that differ from the original input programs. This leads to potential comprehension difficulties for users. In this paper, we propose an approach to suggest a correct program with minimal repair edits using CodeT5. We fine-tune a pre-trained CodeT5 on code pairs of wrong and correct programs and evaluate its performance with several baseline models. The experimental results show that the fine-tuned CodeT5 achieves a pass@100 of 91.95% and an average edit distance of the most similar correct program of 6.84, which indicates that at least one correct program can be suggested by generating 100 candidate programs. We demonstrate the effectiveness of LMs in suggesting program repair with minimal edits for solving introductory programming problems.
Deduplicating and Ranking Solution Programs for Suggesting Reference Solutions
Jul 16, 2023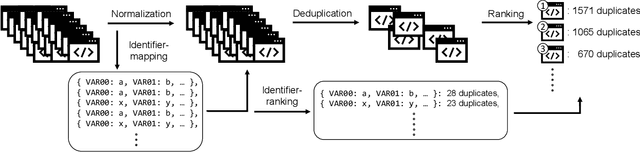
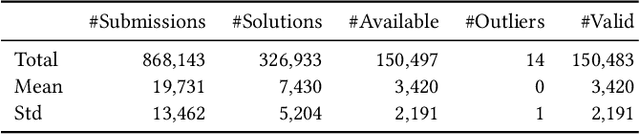
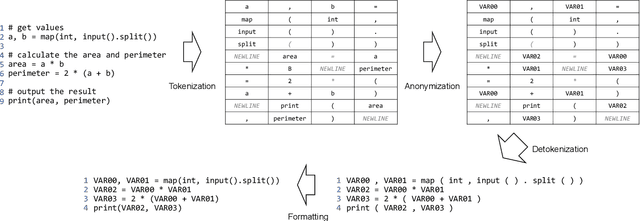
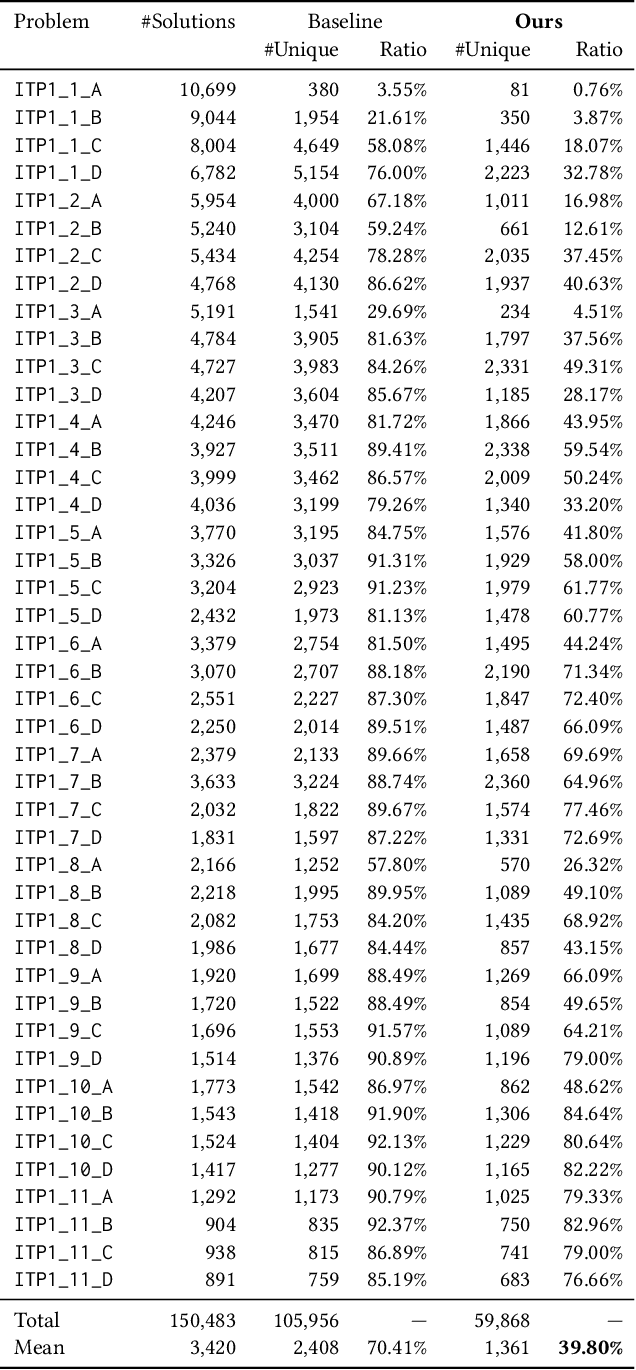
Referring to the solution programs written by the other users is helpful for learners in programming education. However, current online judge systems just list all solution programs submitted by users for references, and the programs are sorted based on the submission date and time, execution time, or user rating, ignoring to what extent the program can be a reference. In addition, users struggle to refer to a variety of solution approaches since there are too many duplicated and near-duplicated programs. To motivate the learners to refer to various solutions to learn the better solution approaches, in this paper, we propose an approach to deduplicate and rank common solution programs in each programming problem. Based on the hypothesis that the more duplicated programs adopt a more common approach and can be a reference, we remove the near-duplicated solution programs and rank the unique programs based on the duplicate count. The experiments on the solution programs submitted to a real-world online judge system demonstrate that the number of programs is reduced by 60.20%, whereas the baseline only reduces by 29.59% after the deduplication, meaning that the users only need to refer to 39.80% of programs on average. Furthermore, our analysis shows that top-10 ranked programs cover 29.95% of programs on average, indicating that the users can grasp 29.95% of solution approaches by referring to only 10 programs. The proposed approach shows the potential of reducing the learners' burden of referring to too many solutions and motivating them to learn a variety of better approaches.
Exploring the Robustness of Large Language Models for Solving Programming Problems
Jun 26, 2023
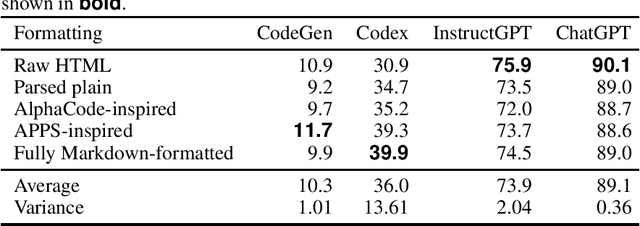

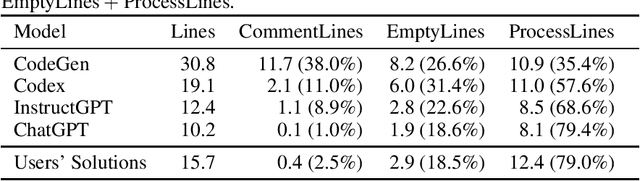
Using large language models (LLMs) for source code has recently gained attention. LLMs, such as Transformer-based models like Codex and ChatGPT, have been shown to be highly capable of solving a wide range of programming problems. However, the extent to which LLMs understand problem descriptions and generate programs accordingly or just retrieve source code from the most relevant problem in training data based on superficial cues has not been discovered yet. To explore this research question, we conduct experiments to understand the robustness of several popular LLMs, CodeGen and GPT-3.5 series models, capable of tackling code generation tasks in introductory programming problems. Our experimental results show that CodeGen and Codex are sensitive to the superficial modifications of problem descriptions and significantly impact code generation performance. Furthermore, we observe that Codex relies on variable names, as randomized variables decrease the solved rate significantly. However, the state-of-the-art (SOTA) models, such as InstructGPT and ChatGPT, show higher robustness to superficial modifications and have an outstanding capability for solving programming problems. This highlights the fact that slight modifications to the prompts given to the LLMs can greatly affect code generation performance, and careful formatting of prompts is essential for high-quality code generation, while the SOTA models are becoming more robust to perturbations.