 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Robust Dynamic Mode Decomposition from Mode Extraction to Dimensional Reduction
Jan 16, 2026We propose Comprehensive Robust Dynamic Mode Decomposition (CR-DMD), a novel framework that robustifies the entire DMD process - from mode extraction to dimensional reduction - against mixed noise. Although standard DMD widely used for uncovering spatio-temporal patterns and constructing low-dimensional models of dynamical systems, it suffers from significant performance degradation under noise due to its reliance on least-squares estimation for computing the linear time evolution operator. Existing robust variants typically modify the least-squares formulation, but they remain unstable and fail to ensure faithful low-dimensional representations. First, we introduce a convex optimization-based preprocessing method designed to effectively remove mixed noise, achieving accurate and stable mode extraction. Second, we propose a new convex formulation for dimensional reduction that explicitly links the robustly extracted modes to the original noisy observations, constructing a faithful representation of the original data via a sparse weighted sum of the modes. Both stages are efficiently solved by a preconditioned primal-dual splitting method. Experiments on fluid dynamics datasets demonstrate that CR-DMD consistently outperforms state-of-the-art robust DMD methods in terms of mode accuracy and fidelity of low-dimensional representations under noisy conditions.
Exploring the Robustness of Large Language Models for Solving Programming Problems
Jun 26, 2023
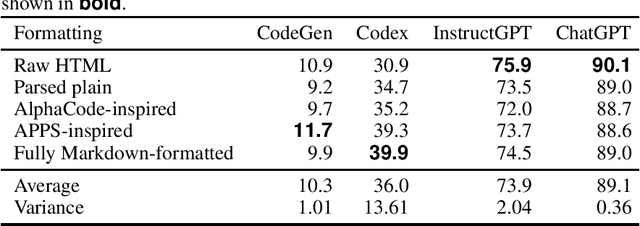

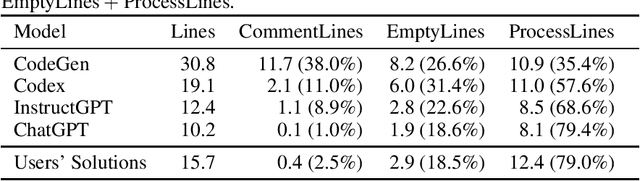
Using large language models (LLMs) for source code has recently gained attention. LLMs, such as Transformer-based models like Codex and ChatGPT, have been shown to be highly capable of solving a wide range of programming problems. However, the extent to which LLMs understand problem descriptions and generate programs accordingly or just retrieve source code from the most relevant problem in training data based on superficial cues has not been discovered yet. To explore this research question, we conduct experiments to understand the robustness of several popular LLMs, CodeGen and GPT-3.5 series models, capable of tackling code generation tasks in introductory programming problems. Our experimental results show that CodeGen and Codex are sensitive to the superficial modifications of problem descriptions and significantly impact code generation performance. Furthermore, we observe that Codex relies on variable names, as randomized variables decrease the solved rate significantly. However, the state-of-the-art (SOTA) models, such as InstructGPT and ChatGPT, show higher robustness to superficial modifications and have an outstanding capability for solving programming problems. This highlights the fact that slight modifications to the prompts given to the LLMs can greatly affect code generation performance, and careful formatting of prompts is essential for high-quality code generation, while the SOTA models are becoming more robust to perturbations.