 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP: Staged Parameter-Efficient Pre-training for Large Language Models
Apr 05, 2025Pre-training large language models (LLMs) faces significant memory challenges due to the large size of model parameters. We introduce STaged parameter-Efficient Pre-training (STEP), which integrates parameter-efficient tuning techniques with model growth. We conduct experiments on pre-training LLMs of various sizes and demonstrate that STEP achieves up to a 53.9% reduction in maximum memory requirements compared to vanilla pre-training while maintaining equivalent performance. Furthermore, we show that the model by STEP performs comparably to vanilla pre-trained models on downstream tasks after instruction tuning.
Energy-Aware Task Allocation for Teams of Multi-mode Robots
Mar 17, 2025This work proposes a novel multi-robot task allocation framework for robots that can switch between multiple modes, e.g., flying, driving, or walking. We first provide a method to encode the multi-mode property of robots as a graph, where the mode of each robot is represented by a node. Next, we formulate a constrained optimization problem to decide both the task to be allocated to each robot as well as the mode in which the latter should execute the task. The robot modes are optimized based on the state of the robot and the environment, as well as the energy required to execute the allocated task. Moreover, the proposed framework is able to encompass kinematic and dynamic models of robots alike. Furthermore, we provide sufficient conditions for the convergence of task execution and allocation for both robot models.
Reference-free Evaluation Metrics for Text Generation: A Survey
Jan 21, 2025
A number of automatic evaluation metrics have been proposed for natural language generation systems. The most common approach to automatic evaluation is the use of a reference-based metric that compares the model's output with gold-standard references written by humans. However, it is expensive to create such references, and for some tasks, such as response generation in dialogue, creating references is not a simple matter. Therefore, various reference-free metrics have been developed in recent years. In this survey, which intends to cover the full breadth of all NLG tasks, we investigate the most commonly used approaches, their application, and their other uses beyond evaluating models. The survey concludes by highlighting some promising directions for future research.
Design and Control of a VTOL Aerial Vehicle Tilting its Rotors Only with Rotor Thrusts and a Passive Joint
Nov 09, 2023This paper presents a novel VTOL UAV that owns a link connecting four rotors and a fuselage by a passive joint, allowing the control of the rotor's tilting angle by adjusting the rotors' thrust. This unique structure contributes to eliminating additional actuators, such as servo motors, to control the tilting angles of rotors, resulting in the UAV's weight lighter and simpler structure. We first derive the dynamical model of the newly designed UAV and analyze its controllability. Then, we design the controller that leverages the tiltable link with four rotors to accelerate the UAV while suppressing a deviation of the UAV's angle of attack from the desired value to restrain the change of the aerodynamic force. Finally, the validity of the proposed control strategy is evaluated in simulation study.
Exploring the Robustness of Large Language Models for Solving Programming Problems
Jun 26, 2023
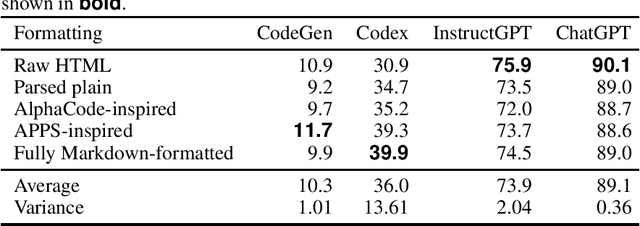

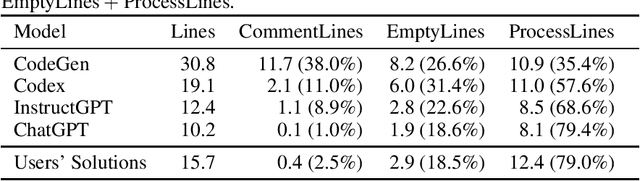
Using large language models (LLMs) for source code has recently gained attention. LLMs, such as Transformer-based models like Codex and ChatGPT, have been shown to be highly capable of solving a wide range of programming problems. However, the extent to which LLMs understand problem descriptions and generate programs accordingly or just retrieve source code from the most relevant problem in training data based on superficial cues has not been discovered yet. To explore this research question, we conduct experiments to understand the robustness of several popular LLMs, CodeGen and GPT-3.5 series models, capable of tackling code generation tasks in introductory programming problems. Our experimental results show that CodeGen and Codex are sensitive to the superficial modifications of problem descriptions and significantly impact code generation performance. Furthermore, we observe that Codex relies on variable names, as randomized variables decrease the solved rate significantly. However, the state-of-the-art (SOTA) models, such as InstructGPT and ChatGPT, show higher robustness to superficial modifications and have an outstanding capability for solving programming problems. This highlights the fact that slight modifications to the prompts given to the LLMs can greatly affect code generation performance, and careful formatting of prompts is essential for high-quality code generation, while the SOTA models are becoming more robust to perturbations.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023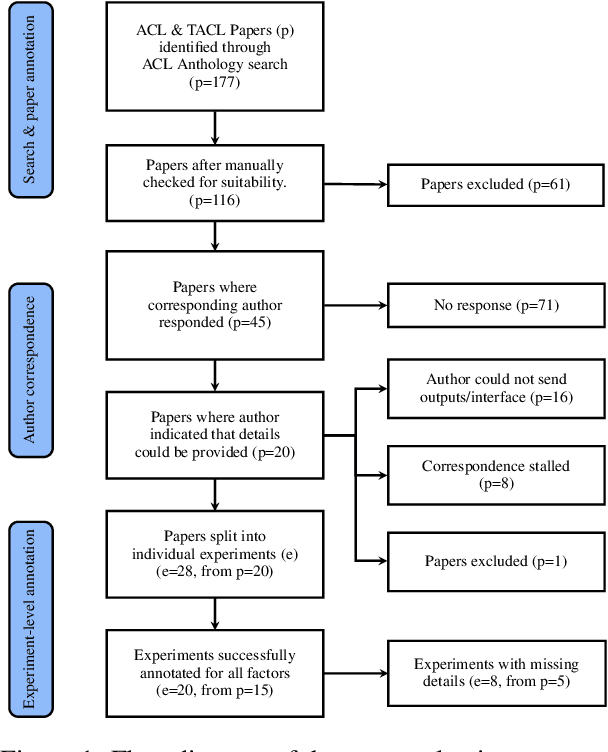
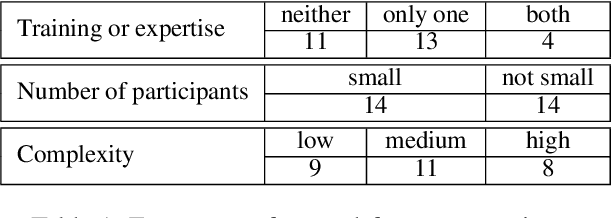


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
Lower Perplexity is Not Always Human-Like
Jun 02, 2021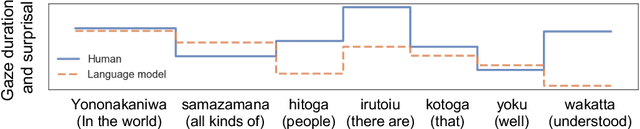

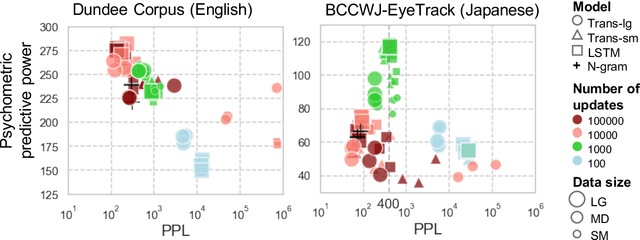
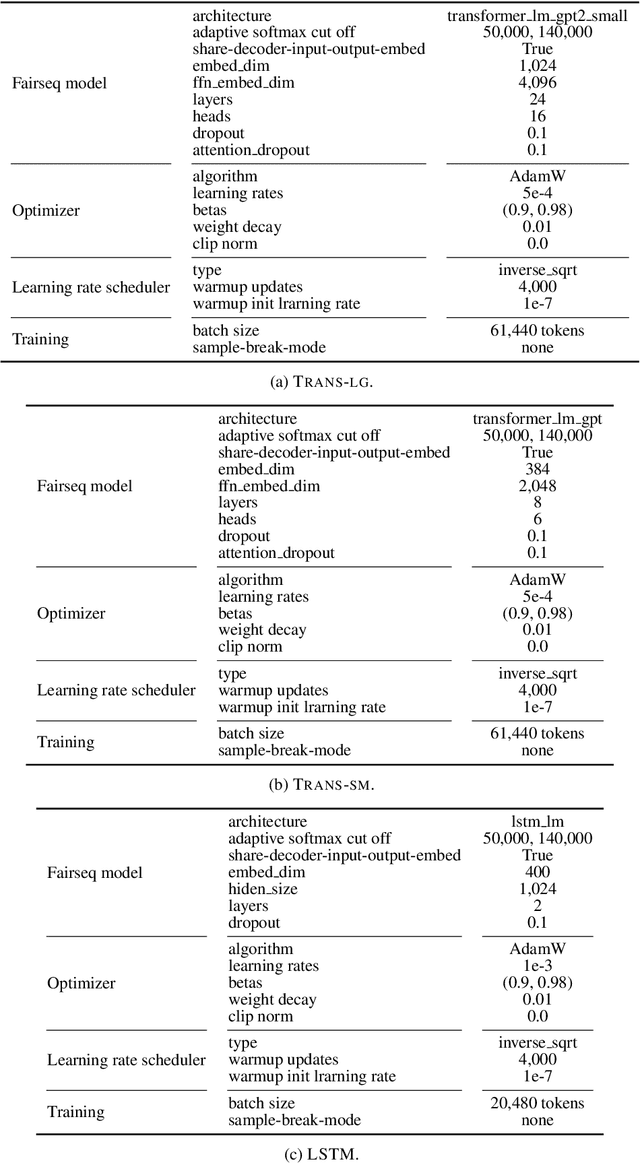
In computational psycholinguistics, various language models have been evaluated against human reading behavior (e.g., eye movement) to build human-like computational models. However, most previous efforts have focused almost exclusively on English, despite the recent trend towards linguistic universal within the general community. In order to fill the gap, this paper investigates whether the established results in computational psycholinguistics can be generalized across languages. Specifically, we re-examine an established generalization -- the lower perplexity a language model has, the more human-like the language model is -- in Japanese with typologically different structures from English. Our experiments demonstrate that this established generalization exhibits a surprising lack of universality; namely, lower perplexity is not always human-like. Moreover, this discrepancy between English and Japanese is further explored from the perspective of (non-)uniform information density. Overall, our results suggest that a cross-lingual evaluation will be necessary to construct human-like computational models.
Langsmith: An Interactive Academic Text Revision System
Oct 09, 2020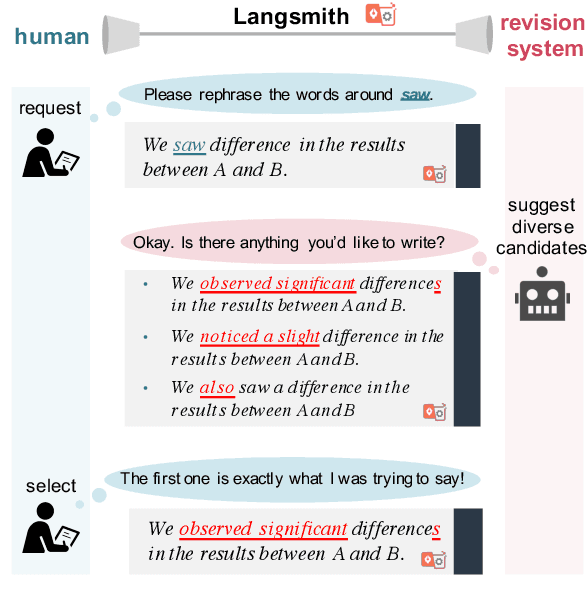
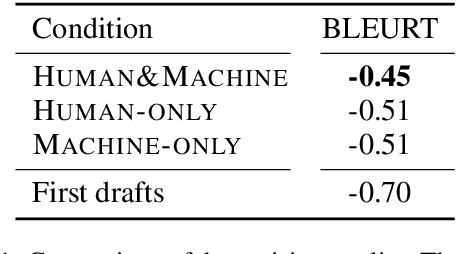
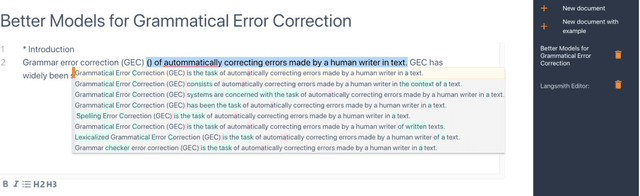
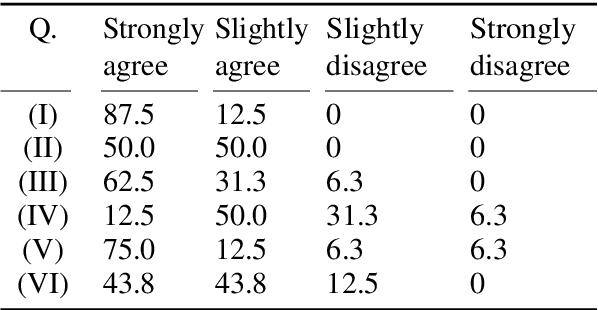
Despite the current diversity and inclusion initiatives in the academic community, researchers with a non-native command of English still face significant obstacles when writing papers in English. This paper presents the Langsmith editor, which assists inexperienced, non-native researchers to write English papers, especially in the natural language processing (NLP) field. Our system can suggest fluent, academic-style sentences to writers based on their rough, incomplete phrases or sentences. The system also encourages interaction between human writers and the computerized revision system. The experimental results demonstrated that Langsmith helps non-native English-speaker students write papers in English. The system is available at https://emnlp-demo.editor. langsmith.co.jp/.
Language Models as an Alternative Evaluator of Word Order Hypotheses: A Case Study in Japanese
May 02, 2020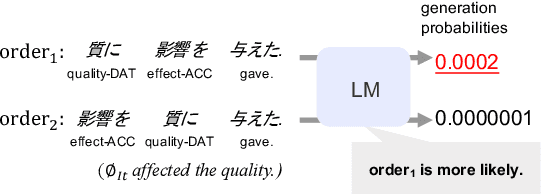

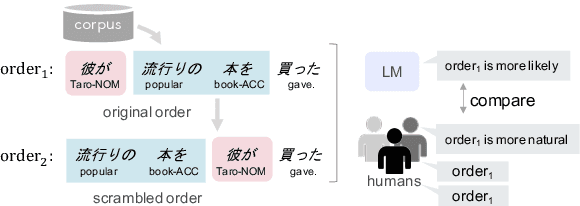

We examine a methodology using neural language models (LMs) for analyzing the word order of language. This LM-based method has the potential to overcome the difficulties existing methods face, such as the propagation of preprocessor errors in count-based methods. In this study, we explore whether the LM-based method is valid for analyzing the word order. As a case study, this study focuses on Japanese due to its complex and flexible word order. To validate the LM-based method, we test (i) parallels between LMs and human word order preference, and (ii) consistency of the results obtained using the LM-based method with previous linguistic studies. Through our experiments, we tentatively conclude that LMs display sufficient word order knowledge for usage as an analysis tool. Finally, using the LM-based method, we demonstrate the relationship between the canonical word order and topicalization, which had yet to be analyzed by large-scale experiments.
Diamonds in the Rough: Generating Fluent Sentences from Early-Stage Drafts for Academic Writing Assistance
Oct 21, 2019
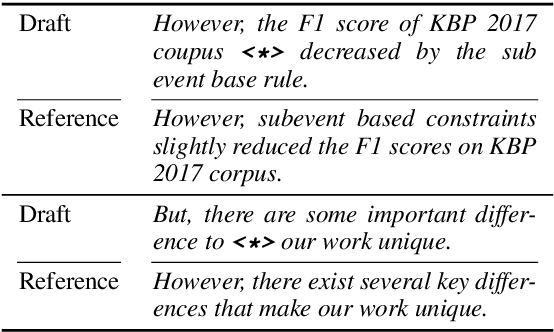


The writing process consists of several stages such as drafting, revising, editing, and proofreading. Studies on writing assistance, such as grammatical error correction (GEC), have mainly focused on sentence editing and proofreading, where surface-level issues such as typographical, spelling, or grammatical errors should be corrected. We broaden this focus to include the earlier revising stage, where sentences require adjustment to the information included or major rewriting and propose Sentence-level Revision (SentRev) as a new writing assistance task. Well-performing systems in this task can help inexperienced authors by producing fluent, complete sentences given their rough, incomplete drafts. We build a new freely available crowdsourced evaluation dataset consisting of incomplete sentences authored by non-native writers paired with their final versions extracted from published academic papers for developing and evaluating SentRev models. We also establish baseline performance on SentRev using our newly built evaluation dataset.