 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Adaptation for Swiss German
May 28, 2025This work investigates the performance of Voice Adaptation models for Swiss German dialects, i.e., translating Standard German text to Swiss German dialect speech. For this, we preprocess a large dataset of Swiss podcasts, which we automatically transcribe and annotate with dialect classes, yielding approximately 5000 hours of weakly labeled training material. We fine-tune the XTTSv2 model on this dataset and show that it achieves good scores in human and automated evaluations and can correctly render the desired dialect. Our work shows a step towards adapting Voice Cloning technology to underrepresented languages. The resulting model achieves CMOS scores of up to -0.28 and SMOS scores of 3.8.
ViClaim: A Multilingual Multilabel Dataset for Automatic Claim Detection in Videos
Apr 17, 2025The growing influence of video content as a medium for communication and misinformation underscores the urgent need for effective tools to analyze claims in multilingual and multi-topic settings. Existing efforts in misinformation detection largely focus on written text, leaving a significant gap in addressing the complexity of spoken text in video transcripts. We introduce ViClaim, a dataset of 1,798 annotated video transcripts across three languages (English, German, Spanish) and six topics. Each sentence in the transcripts is labeled with three claim-related categories: fact-check-worthy, fact-non-check-worthy, or opinion. We developed a custom annotation tool to facilitate the highly complex annotation process. Experiments with state-of-the-art multilingual language models demonstrate strong performance in cross-validation (macro F1 up to 0.896) but reveal challenges in generalization to unseen topics, particularly for distinct domains. Our findings highlight the complexity of claim detection in video transcripts. ViClaim offers a robust foundation for advancing misinformation detection in video-based communication, addressing a critical gap in multimodal analysis.
A Measure of the System Dependence of Automated Metrics
Dec 04, 2024



Automated metrics for Machine Translation have made significant progress, with the goal of replacing expensive and time-consuming human evaluations. These metrics are typically assessed by their correlation with human judgments, which captures the monotonic relationship between human and metric scores. However, we argue that it is equally important to ensure that metrics treat all systems fairly and consistently. In this paper, we introduce a method to evaluate this aspect.
Error-preserving Automatic Speech Recognition of Young English Learners' Language
Jun 05, 2024One of the central skills that language learners need to practice is speaking the language. Currently, students in school do not get enough speaking opportunities and lack conversational practice. Recent advances in speech technology and natural language processing allow for the creation of novel tools to practice their speaking skills. In this work, we tackle the first component of such a pipeline, namely, the automated speech recognition module (ASR), which faces a number of challenges: first, state-of-the-art ASR models are often trained on adult read-aloud data by native speakers and do not transfer well to young language learners' speech. Second, most ASR systems contain a powerful language model, which smooths out errors made by the speakers. To give corrective feedback, which is a crucial part of language learning, the ASR systems in our setting need to preserve the errors made by the language learners. In this work, we build an ASR system that satisfies these requirements: it works on spontaneous speech by young language learners and preserves their errors. For this, we collected a corpus containing around 85 hours of English audio spoken by learners in Switzerland from grades 4 to 6 on different language learning tasks, which we used to train an ASR model. Our experiments show that our model benefits from direct fine-tuning on children's voices and has a much higher error preservation rate than other models.
Favi-Score: A Measure for Favoritism in Automated Preference Ratings for Generative AI Evaluation
Jun 03, 2024



Generative AI systems have become ubiquitous for all kinds of modalities, which makes the issue of the evaluation of such models more pressing. One popular approach is preference ratings, where the generated outputs of different systems are shown to evaluators who choose their preferences. In recent years the field shifted towards the development of automated (trained) metrics to assess generated outputs, which can be used to create preference ratings automatically. In this work, we investigate the evaluation of the metrics themselves, which currently rely on measuring the correlation to human judgments or computing sign accuracy scores. These measures only assess how well the metric agrees with the human ratings. However, our research shows that this does not tell the whole story. Most metrics exhibit a disagreement with human system assessments which is often skewed in favor of particular text generation systems, exposing a degree of favoritism in automated metrics. This paper introduces a formal definition of favoritism in preference metrics, and derives the Favi-Score, which measures this phenomenon. In particular we show that favoritism is strongly related to errors in final system rankings. Thus, we propose that preference-based metrics ought to be evaluated on both sign accuracy scores and favoritism.
Dialect Transfer for Swiss German Speech Translation
Oct 13, 2023This paper investigates the challenges in building Swiss German speech translation systems, specifically focusing on the impact of dialect diversity and differences between Swiss German and Standard German. Swiss German is a spoken language with no formal writing system, it comprises many diverse dialects and is a low-resource language with only around 5 million speakers. The study is guided by two key research questions: how does the inclusion and exclusion of dialects during the training of speech translation models for Swiss German impact the performance on specific dialects, and how do the differences between Swiss German and Standard German impact the performance of the systems? We show that dialect diversity and linguistic differences pose significant challenges to Swiss German speech translation, which is in line with linguistic hypotheses derived from empirical investigations.
Correction of Errors in Preference Ratings from Automated Metrics for Text Generation
Jun 06, 2023



A major challenge in the field of Text Generation is evaluation: Human evaluations are cost-intensive, and automated metrics often display considerable disagreement with human judgments. In this paper, we propose a statistical model of Text Generation evaluation that accounts for the error-proneness of automated metrics when used to generate preference rankings between system outputs. We show that existing automated metrics are generally over-confident in assigning significant differences between systems in this setting. However, our model enables an efficient combination of human and automated ratings to remedy the error-proneness of the automated metrics. We show that using this combination, we only require about 50% of the human annotations typically used in evaluations to arrive at robust and statistically significant results while yielding the same evaluation outcome as the pure human evaluation in 95% of cases. We showcase the benefits of approach for three text generation tasks: dialogue systems, machine translation, and text summarization.
STT4SG-350: A Speech Corpus for All Swiss German Dialect Regions
May 30, 2023



We present STT4SG-350 (Speech-to-Text for Swiss German), a corpus of Swiss German speech, annotated with Standard German text at the sentence level. The data is collected using a web app in which the speakers are shown Standard German sentences, which they translate to Swiss German and record. We make the corpus publicly available. It contains 343 hours of speech from all dialect regions and is the largest public speech corpus for Swiss German to date. Application areas include automatic speech recognition (ASR), text-to-speech, dialect identification, and speaker recognition. Dialect information, age group, and gender of the 316 speakers are provided. Genders are equally represented and the corpus includes speakers of all ages. Roughly the same amount of speech is provided per dialect region, which makes the corpus ideally suited for experiments with speech technology for different dialects. We provide training, validation, and test splits of the data. The test set consists of the same spoken sentences for each dialect region and allows a fair evaluation of the quality of speech technologies in different dialects. We train an ASR model on the training set and achieve an average BLEU score of 74.7 on the test set. The model beats the best published BLEU scores on 2 other Swiss German ASR test sets, demonstrating the quality of the corpus.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023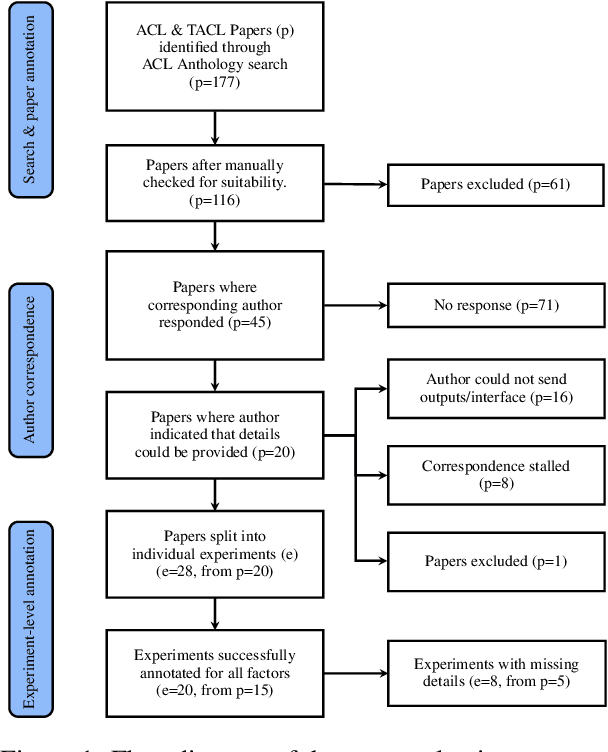
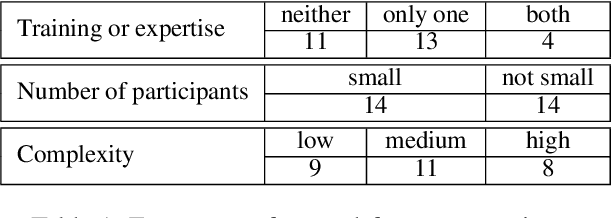


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
On the Effectiveness of Automated Metrics for Text Generation Systems
Oct 24, 2022



A major challenge in the field of Text Generation is evaluation because we lack a sound theory that can be leveraged to extract guidelines for evaluation campaigns. In this work, we propose a first step towards such a theory that incorporates different sources of uncertainty, such as imperfect automated metrics and insufficiently sized test sets. The theory has practical applications, such as determining the number of samples needed to reliably distinguish the performance of a set of Text Generation systems in a given setting. We showcase the application of the theory on the WMT 21 and Spot-The-Bot evaluation data and outline how it can be leveraged to improve the evaluation protocol regarding the reliability, robustness, and significance of the evaluation outcome.