 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Outcome Verification: Verifiable Process Reward Models for Structured Reasoning
Jan 23, 2026Recent work on reinforcement learning with verifiable rewards (RLVR) has shown that large language models (LLMs) can be substantially improved using outcome-level verification signals, such as unit tests for code or exact-match checks for mathematics. In parallel, process supervision has long been explored as a way to shape the intermediate reasoning behaviour of LLMs, but existing approaches rely on neural judges to score chain-of-thought steps, leaving them vulnerable to opacity, bias, and reward hacking. To address this gap, we introduce Verifiable Process Reward Models (VPRMs), a reinforcement-learning framework in which intermediate reasoning steps are checked by deterministic, rule-based verifiers. We apply VPRMs to risk-of-bias assessment for medical evidence synthesis, a domain where guideline-defined criteria and rule-based decision paths enable programmatic verification of reasoning traces. Across multiple datasets, we find that VPRMs generate reasoning that adheres closely to domain rules and achieve substantially higher coherence between step-level decisions and final labels. Results show that VPRMs achieve up to 20% higher F1 than state-of-the-art models and 6.5% higher than verifiable outcome rewards, with substantial gains in evidence grounding and logical coherence.
The QCET Taxonomy of Standard Quality Criterion Names and Definitions for the Evaluation of NLP Systems
Sep 26, 2025Prior work has shown that two NLP evaluation experiments that report results for the same quality criterion name (e.g. Fluency) do not necessarily evaluate the same aspect of quality, and the comparability implied by the name can be misleading. Not knowing when two evaluations are comparable in this sense means we currently lack the ability to draw reliable conclusions about system quality on the basis of multiple, independently conducted evaluations. This in turn hampers the ability of the field to progress scientifically as a whole, a pervasive issue in NLP since its beginning (Sparck Jones, 1981). It is hard to see how the issue of unclear comparability can be fully addressed other than by the creation of a standard set of quality criterion names and definitions that the several hundred quality criterion names actually in use in the field can be mapped to, and grounded in. Taking a strictly descriptive approach, the QCET Quality Criteria for Evaluation Taxonomy derives a standard set of quality criterion names and definitions from three surveys of evaluations reported in NLP, and structures them into a hierarchy where each parent node captures common aspects of its child nodes. We present QCET and the resources it consists of, and discuss its three main uses in (i) establishing comparability of existing evaluations, (ii) guiding the design of new evaluations, and (iii) assessing regulatory compliance.
Enhancing Study-Level Inference from Clinical Trial Papers via RL-based Numeric Reasoning
May 28, 2025Systematic reviews in medicine play a critical role in evidence-based decision-making by aggregating findings from multiple studies. A central bottleneck in automating this process is extracting numeric evidence and determining study-level conclusions for specific outcomes and comparisons. Prior work has framed this problem as a textual inference task by retrieving relevant content fragments and inferring conclusions from them. However, such approaches often rely on shallow textual cues and fail to capture the underlying numeric reasoning behind expert assessments. In this work, we conceptualise the problem as one of quantitative reasoning. Rather than inferring conclusions from surface text, we extract structured numerical evidence (e.g., event counts or standard deviations) and apply domain knowledge informed logic to derive outcome-specific conclusions. We develop a numeric reasoning system composed of a numeric data extraction model and an effect estimate component, enabling more accurate and interpretable inference aligned with the domain expert principles. We train the numeric data extraction model using different strategies, including supervised fine-tuning (SFT) and reinforcement learning (RL) with a new value reward model. When evaluated on the CochraneForest benchmark, our best-performing approach -- using RL to train a small-scale number extraction model -- yields up to a 21% absolute improvement in F1 score over retrieval-based systems and outperforms general-purpose LLMs of over 400B parameters by up to 9%. Our results demonstrate the promise of reasoning-driven approaches for automating systematic evidence synthesis.
Query-driven Document-level Scientific Evidence Extraction from Biomedical Studies
May 09, 2025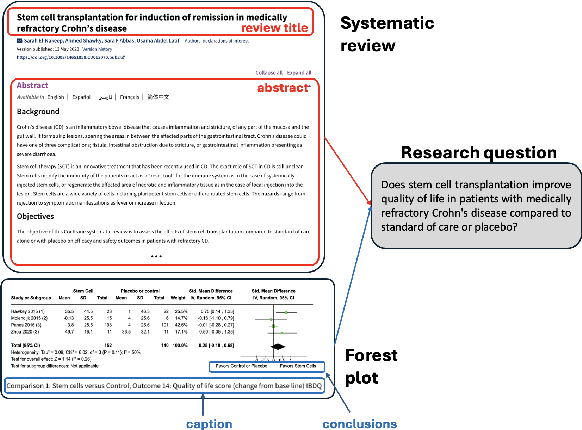
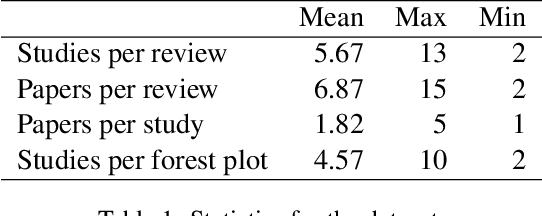
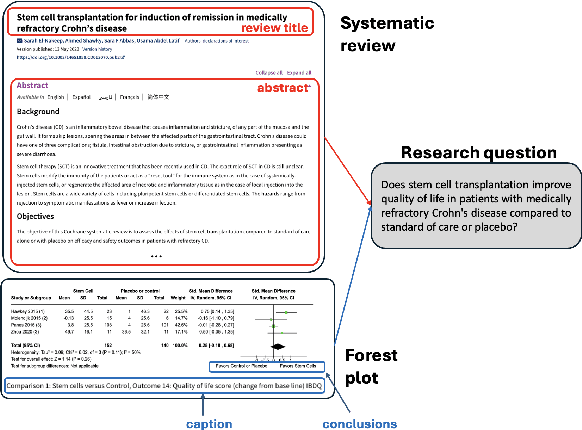
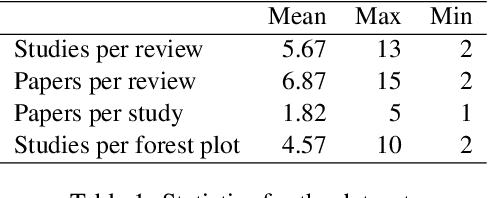
Extracting scientific evidence from biomedical studies for clinical research questions (e.g., Does stem cell transplantation improve quality of life in patients with medically refractory Crohn's disease compared to placebo?) is a crucial step in synthesising biomedical evidence. In this paper, we focus on the task of document-level scientific evidence extraction for clinical questions with conflicting evidence. To support this task, we create a dataset called CochraneForest, leveraging forest plots from Cochrane systematic reviews. It comprises 202 annotated forest plots, associated clinical research questions, full texts of studies, and study-specific conclusions. Building on CochraneForest, we propose URCA (Uniform Retrieval Clustered Augmentation), a retrieval-augmented generation framework designed to tackle the unique challenges of evidence extraction. Our experiments show that URCA outperforms the best existing methods by up to 10.3% in F1 score on this task. However, the results also underscore the complexity of CochraneForest, establishing it as a challenging testbed for advancing automated evidence synthesis systems.
HEDS 3.0: The Human Evaluation Data Sheet Version 3.0
Dec 10, 2024This paper presents version 3.0 of the Human Evaluation Datasheet (HEDS). This update is the result of our experience using HEDS in the context of numerous recent human evaluation experiments, including reproduction studies, and of feedback received. Our main overall goal was to improve clarity, and to enable users to complete the datasheet more consistently and comparably. The HEDS 3.0 package consists of the digital data sheet, documentation, and code for exporting completed data sheets as latex files, all available from the HEDS GitHub.
Reproducing the Metric-Based Evaluation of a Set of Controllable Text Generation Techniques
May 13, 2024



Rerunning a metric-based evaluation should be more straightforward, and results should be closer, than in a human-based evaluation, especially where code and model checkpoints are made available by the original authors. As this report of our efforts to rerun a metric-based evaluation of a set of single-attribute and multiple-attribute controllable text generation (CTG) techniques shows however, such reruns of evaluations do not always produce results that are the same as the original results, and can reveal errors in the reporting of the original work.
High-quality Data-to-Text Generation for Severely Under-Resourced Languages with Out-of-the-box Large Language Models
Feb 19, 2024



The performance of NLP methods for severely under-resourced languages cannot currently hope to match the state of the art in NLP methods for well resourced languages. We explore the extent to which pretrained large language models (LLMs) can bridge this gap, via the example of data-to-text generation for Irish, Welsh, Breton and Maltese. We test LLMs on these under-resourced languages and English, in a range of scenarios. We find that LLMs easily set the state of the art for the under-resourced languages by substantial margins, as measured by both automatic and human evaluations. For all our languages, human evaluation shows on-a-par performance with humans for our best systems, but BLEU scores collapse compared to English, casting doubt on the metric's suitability for evaluating non-task-specific systems. Overall, our results demonstrate the great potential of LLMs to bridge the performance gap for under-resourced languages.
Assessing the Portability of Parameter Matrices Trained by Parameter-Efficient Finetuning Methods
Jan 25, 2024As the cost of training ever larger language models has grown, so has the interest in reusing previously learnt knowledge. Transfer learning methods have shown how reusing non-task-specific knowledge can help in subsequent task-specific learning. In this paper, we investigate the inverse: porting whole functional modules that encode task-specific knowledge from one model to another. We designed a study comprising 1,440 training/testing runs to test the portability of modules trained by parameter-efficient finetuning (PEFT) techniques, using sentiment analysis as an example task. We test portability in a wide range of scenarios, involving different PEFT techniques and different pretrained host models, among other dimensions. We compare the performance of ported modules with that of equivalent modules trained (i) from scratch, and (ii) from parameters sampled from the same distribution as the ported module. We find that the ported modules far outperform the two alternatives tested, but that there are interesting performance differences between the four PEFT techniques. We conclude that task-specific knowledge in the form of structurally modular sets of parameters as produced by PEFT techniques is highly portable, but that degree of success depends on type of PEFT and on differences between originating and receiving pretrained models.
Data-to-text Generation for Severely Under-Resourced Languages with GPT-3.5: A Bit of Help Needed from Google Translate
Aug 19, 2023LLMs like GPT are great at tasks involving English which dominates in their training data. In this paper, we look at how they cope with tasks involving languages that are severely under-represented in their training data, in the context of data-to-text generation for Irish, Maltese, Welsh and Breton. During the prompt-engineering phase we tested a range of prompt types and formats on GPT-3.5 and~4 with a small sample of example input/output pairs. We then fully evaluated the two most promising prompts in two scenarios: (i) direct generation into the under-resourced language, and (ii) generation into English followed by translation into the under-resourced language. We find that few-shot prompting works better for direct generation into under-resourced languages, but that the difference disappears when pivoting via English. The few-shot + translation system variants were submitted to the WebNLG 2023 shared task where they outperformed competitor systems by substantial margins in all languages on all metrics. We conclude that good performance on under-resourced languages can be achieved out-of-the box with state-of-the-art LLMs. However, our best results (for Welsh) remain well below the lowest ranked English system at WebNLG'20.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023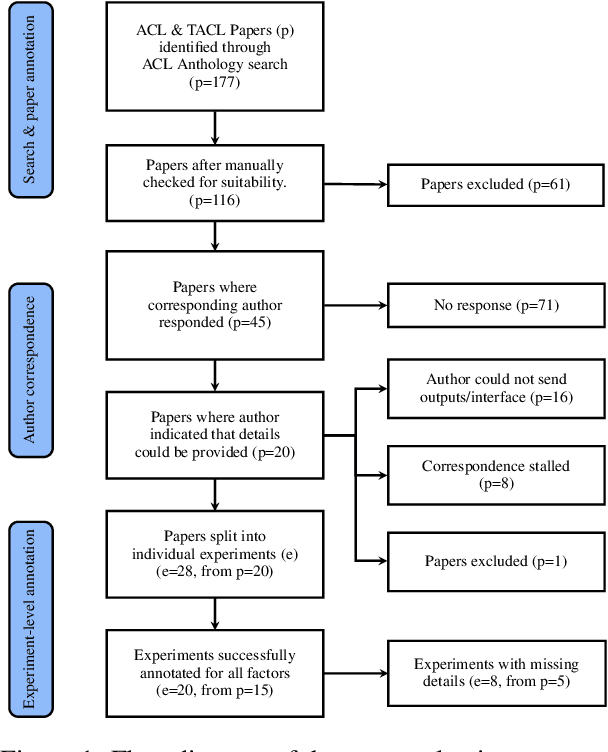
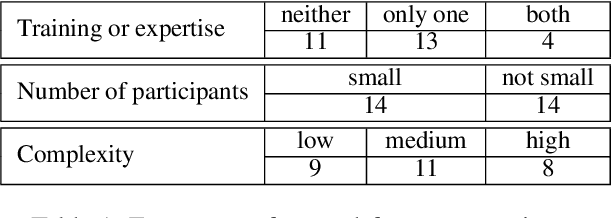


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.