 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Idea to Implementation: Evaluating the Influence of Large Language Models in Software Development -- An Opinion Paper
Mar 10, 2025The introduction of transformer architecture was a turning point in Natural Language Processing (NLP). Models based on the transformer architecture such as Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-Trained Transformer (GPT) have gained widespread popularity in various applications such as software development and education. The availability of Large Language Models (LLMs) such as ChatGPT and Bard to the general public has showcased the tremendous potential of these models and encouraged their integration into various domains such as software development for tasks such as code generation, debugging, and documentation generation. In this study, opinions from 11 experts regarding their experience with LLMs for software development have been gathered and analysed to draw insights that can guide successful and responsible integration. The overall opinion of the experts is positive, with the experts identifying advantages such as increase in productivity and reduced coding time. Potential concerns and challenges such as risk of over-dependence and ethical considerations have also been highlighted.
ATHAR: A High-Quality and Diverse Dataset for Classical Arabic to English Translation
Jul 29, 2024


Classical Arabic represents a significant era, encompassing the golden age of Arab culture, philosophy, and scientific literature. With a broad consensus on the importance of translating these literatures to enrich knowledge dissemination across communities, the advent of large language models (LLMs) and translation systems offers promising tools to facilitate this goal. However, we have identified a scarcity of translation datasets in Classical Arabic, which are often limited in scope and topics, hindering the development of high-quality translation systems. In response, we present the ATHAR dataset, comprising 66,000 high-quality Classical Arabic to English translation samples that cover a wide array of subjects including science, culture, and philosophy. Furthermore, we assess the performance of current state-of-the-art LLMs under various settings, concluding that there is a need for such datasets in current systems. Our findings highlight how models can benefit from fine-tuning or incorporating this dataset into their pretraining pipelines. The dataset is publicly available on the HuggingFace Data Hub at \url{https://huggingface.co/datasets/mohamed-khalil/ATHAR}.
Assessing the Portability of Parameter Matrices Trained by Parameter-Efficient Finetuning Methods
Jan 25, 2024As the cost of training ever larger language models has grown, so has the interest in reusing previously learnt knowledge. Transfer learning methods have shown how reusing non-task-specific knowledge can help in subsequent task-specific learning. In this paper, we investigate the inverse: porting whole functional modules that encode task-specific knowledge from one model to another. We designed a study comprising 1,440 training/testing runs to test the portability of modules trained by parameter-efficient finetuning (PEFT) techniques, using sentiment analysis as an example task. We test portability in a wide range of scenarios, involving different PEFT techniques and different pretrained host models, among other dimensions. We compare the performance of ported modules with that of equivalent modules trained (i) from scratch, and (ii) from parameters sampled from the same distribution as the ported module. We find that the ported modules far outperform the two alternatives tested, but that there are interesting performance differences between the four PEFT techniques. We conclude that task-specific knowledge in the form of structurally modular sets of parameters as produced by PEFT techniques is highly portable, but that degree of success depends on type of PEFT and on differences between originating and receiving pretrained models.
PEFT-Ref: A Modular Reference Architecture and Typology for Parameter-Efficient Finetuning Techniques
Apr 24, 2023



Recent parameter-efficient finetuning (PEFT) techniques aim to improve over the considerable cost of fully finetuning large pretrained language models (PLM). As different PEFT techniques proliferate, it is becoming difficult to compare them, in particular in terms of (i) the structure and functionality they add to the PLM, (ii) the different types and degrees of efficiency improvements achieved, (iii) performance at different downstream tasks, and (iv) how differences in structure and functionality relate to efficiency and task performance. To facilitate such comparisons, this paper presents a reference framework which standardises aspects shared by different PEFT techniques, while isolating differences to specific locations and interactions with the standard components. Through this process of standardising and isolating differences, a modular view of PEFT techniques emerges, supporting not only direct comparison of different techniques and their efficiency and task performance, but also systematic exploration of reusability and composability of the different types of finetuned modules. We demonstrate how the reference framework can be applied to understand properties and relative advantages of PEFT techniques, hence to inform selection of techniques for specific tasks, and design choices for new PEFT techniques.
AfriVEC: Word Embedding Models for African Languages. Case Study of Fon and Nobiin
Mar 18, 2021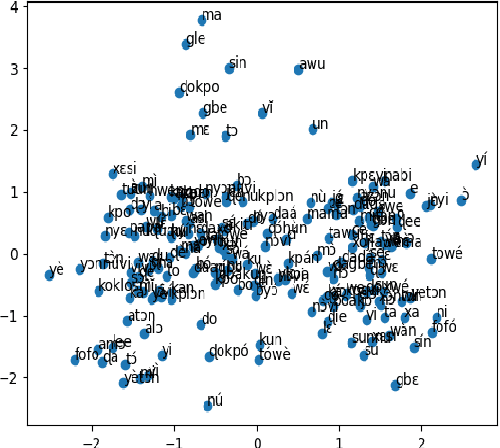
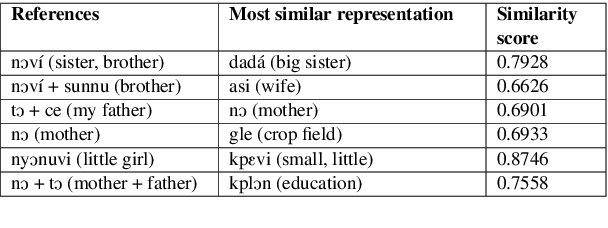
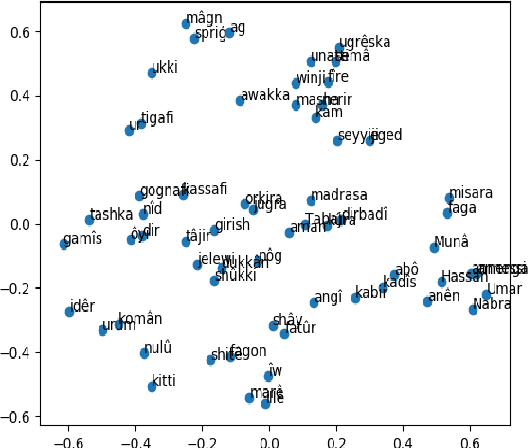

From Word2Vec to GloVe, word embedding models have played key roles in the current state-of-the-art results achieved in Natural Language Processing. Designed to give significant and unique vectorized representations of words and entities, those models have proven to efficiently extract similarities and establish relationships reflecting semantic and contextual meaning among words and entities. African Languages, representing more than 31% of the worldwide spoken languages, have recently been subject to lots of research. However, to the best of our knowledge, there are currently very few to none word embedding models for those languages words and entities, and none for the languages under study in this paper. After describing Glove, Word2Vec, and Poincar\'e embeddings functionalities, we build Word2Vec and Poincar\'e word embedding models for Fon and Nobiin, which show promising results. We test the applicability of transfer learning between these models as a landmark for African Languages to jointly involve in mitigating the scarcity of their resources, and attempt to provide linguistic and social interpretations of our results. Our main contribution is to arouse more interest in creating word embedding models proper to African Languages, ready for use, and that can significantly improve the performances of Natural Language Processing downstream tasks on them. The official repository and implementation is at https://github.com/bonaventuredossou/afrivec
On the Reduction of Variance and Overestimation of Deep Q-Learning
Oct 14, 2019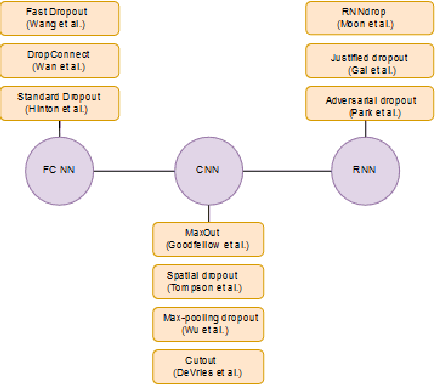

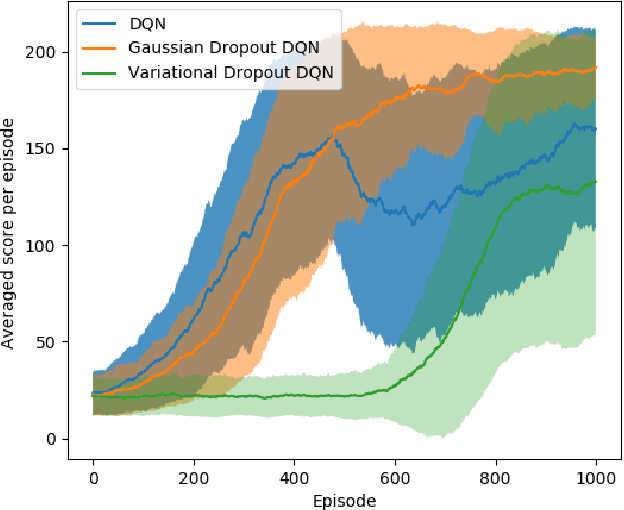

The breakthrough of deep Q-Learning on different types of environments revolutionized the algorithmic design of Reinforcement Learning to introduce more stable and robust algorithms, to that end many extensions to deep Q-Learning algorithm have been proposed to reduce the variance of the target values and the overestimation phenomena. In this paper, we examine new methodology to solve these issues, we propose using Dropout techniques on deep Q-Learning algorithm as a way to reduce variance and overestimation. We further present experiments on some of the benchmark environments that demonstrate significant improvement of the stability of the performance and a reduction in variance and overestimation.