 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Idea to Implementation: Evaluating the Influence of Large Language Models in Software Development -- An Opinion Paper
Mar 10, 2025The introduction of transformer architecture was a turning point in Natural Language Processing (NLP). Models based on the transformer architecture such as Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-Trained Transformer (GPT) have gained widespread popularity in various applications such as software development and education. The availability of Large Language Models (LLMs) such as ChatGPT and Bard to the general public has showcased the tremendous potential of these models and encouraged their integration into various domains such as software development for tasks such as code generation, debugging, and documentation generation. In this study, opinions from 11 experts regarding their experience with LLMs for software development have been gathered and analysed to draw insights that can guide successful and responsible integration. The overall opinion of the experts is positive, with the experts identifying advantages such as increase in productivity and reduced coding time. Potential concerns and challenges such as risk of over-dependence and ethical considerations have also been highlighted.
Cooking Is All About People: Comment Classification On Cookery Channels Using BERT and Classification Models (Malayalam-English Mix-Code)
Jul 17, 2020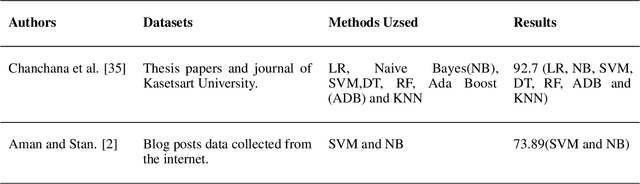



The scope of a lucrative career promoted by Google through its video distribution platform YouTube has attracted a large number of users to become content creators. An important aspect of this line of work is the feedback received in the form of comments which show how well the content is being received by the audience. However, volume of comments coupled with spam and limited tools for comment classification makes it virtually impossible for a creator to go through each and every comment and gather constructive feedback. Automatic classification of comments is a challenge even for established classification models, since comments are often of variable lengths riddled with slang, symbols and abbreviations. This is a greater challenge where comments are multilingual as the messages are often rife with the respective vernacular. In this work, we have evaluated top-performing classification models for classifying comments which are a mix of different combinations of English and Malayalam (only English, only Malayalam and Mix of English and Malayalam). The statistical analysis of results indicates that Multinomial Naive Bayes, K-Nearest Neighbors (KNN), Support Vector Machine (SVM), Random Forest and Decision Trees offer similar level of accuracy in comment classification. Further, we have also evaluated 3 multilingual transformer based language models (BERT, DISTILBERT and XLM) and compared their performance to the traditional machine learning classification techniques. XLM was the top-performing BERT model with an accuracy of 67.31. Random Forest with Term Frequency Vectorizer was the best the top-performing model out of all the traditional classification models with an accuracy of 63.59.