 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Under-Explored Application for Explainable Multimodal Misogyny Detection in code-mixed Hindi-English
Jan 13, 2026Digital platforms have an ever-expanding user base, and act as a hub for communication, business, and connectivity. However, this has also allowed for the spread of hate speech and misogyny. Artificial intelligence models have emerged as an effective solution for countering online hate speech but are under explored for low resource and code-mixed languages and suffer from a lack of interpretability. Explainable Artificial Intelligence (XAI) can enhance transparency in the decisions of deep learning models, which is crucial for a sensitive domain such as hate speech detection. In this paper, we present a multi-modal and explainable web application for detecting misogyny in text and memes in code-mixed Hindi and English. The system leverages state-of-the-art transformer-based models that support multilingual and multimodal settings. For text-based misogyny identification, the system utilizes XLM-RoBERTa (XLM-R) and multilingual Bidirectional Encoder Representations from Transformers (mBERT) on a dataset of approximately 4,193 comments. For multimodal misogyny identification from memes, the system utilizes mBERT + EfficientNet, and mBERT + ResNET trained on a dataset of approximately 4,218 memes. It also provides feature importance scores using explainability techniques including Shapley Additive Values (SHAP) and Local Interpretable Model Agnostic Explanations (LIME). The application aims to serve as a tool for both researchers and content moderators, to promote further research in the field, combat gender based digital violence, and ensure a safe digital space. The system has been evaluated using human evaluators who provided their responses on Chatbot Usability Questionnaire (CUQ) and User Experience Questionnaire (UEQ) to determine overall usability.
From Idea to Implementation: Evaluating the Influence of Large Language Models in Software Development -- An Opinion Paper
Mar 10, 2025The introduction of transformer architecture was a turning point in Natural Language Processing (NLP). Models based on the transformer architecture such as Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-Trained Transformer (GPT) have gained widespread popularity in various applications such as software development and education. The availability of Large Language Models (LLMs) such as ChatGPT and Bard to the general public has showcased the tremendous potential of these models and encouraged their integration into various domains such as software development for tasks such as code generation, debugging, and documentation generation. In this study, opinions from 11 experts regarding their experience with LLMs for software development have been gathered and analysed to draw insights that can guide successful and responsible integration. The overall opinion of the experts is positive, with the experts identifying advantages such as increase in productivity and reduced coding time. Potential concerns and challenges such as risk of over-dependence and ethical considerations have also been highlighted.
Exploring the Impact of Generative Artificial Intelligence in Education: A Thematic Analysis
Jan 17, 2025



The recent advancements in Generative Artificial intelligence (GenAI) technology have been transformative for the field of education. Large Language Models (LLMs) such as ChatGPT and Bard can be leveraged to automate boilerplate tasks, create content for personalised teaching, and handle repetitive tasks to allow more time for creative thinking. However, it is important to develop guidelines, policies, and assessment methods in the education sector to ensure the responsible integration of these tools. In this article, thematic analysis has been performed on seven essays obtained from professionals in the education sector to understand the advantages and pitfalls of using GenAI models such as ChatGPT and Bard in education. Exploratory Data Analysis (EDA) has been performed on the essays to extract further insights from the text. The study found several themes which highlight benefits and drawbacks of GenAI tools, as well as suggestions to overcome these limitations and ensure that students are using these tools in a responsible and ethical manner.
Exploratory Data Analysis on Code-mixed Misogynistic Comments
Mar 09, 2024The problems of online hate speech and cyberbullying have significantly worsened since the increase in popularity of social media platforms such as YouTube and Twitter (X). Natural Language Processing (NLP) techniques have proven to provide a great advantage in automatic filtering such toxic content. Women are disproportionately more likely to be victims of online abuse. However, there appears to be a lack of studies that tackle misogyny detection in under-resourced languages. In this short paper, we present a novel dataset of YouTube comments in mix-code Hinglish collected from YouTube videos which have been weak labelled as `Misogynistic' and `Non-misogynistic'. Pre-processing and Exploratory Data Analysis (EDA) techniques have been applied on the dataset to gain insights on its characteristics. The process has provided a better understanding of the dataset through sentiment scores, word clouds, etc.
Leveraging Weakly Annotated Data for Hate Speech Detection in Code-Mixed Hinglish: A Feasibility-Driven Transfer Learning Approach with Large Language Models
Mar 04, 2024The advent of Large Language Models (LLMs) has advanced the benchmark in various Natural Language Processing (NLP) tasks. However, large amounts of labelled training data are required to train LLMs. Furthermore, data annotation and training are computationally expensive and time-consuming. Zero and few-shot learning have recently emerged as viable options for labelling data using large pre-trained models. Hate speech detection in mix-code low-resource languages is an active problem area where the use of LLMs has proven beneficial. In this study, we have compiled a dataset of 100 YouTube comments, and weakly labelled them for coarse and fine-grained misogyny classification in mix-code Hinglish. Weak annotation was applied due to the labor-intensive annotation process. Zero-shot learning, one-shot learning, and few-shot learning and prompting approaches have then been applied to assign labels to the comments and compare them to human-assigned labels. Out of all the approaches, zero-shot classification using the Bidirectional Auto-Regressive Transformers (BART) large model and few-shot prompting using Generative Pre-trained Transformer- 3 (ChatGPT-3) achieve the best results
Communication is the universal solvent: atreya bot -- an interactive bot for chemical scientists
Jun 14, 2021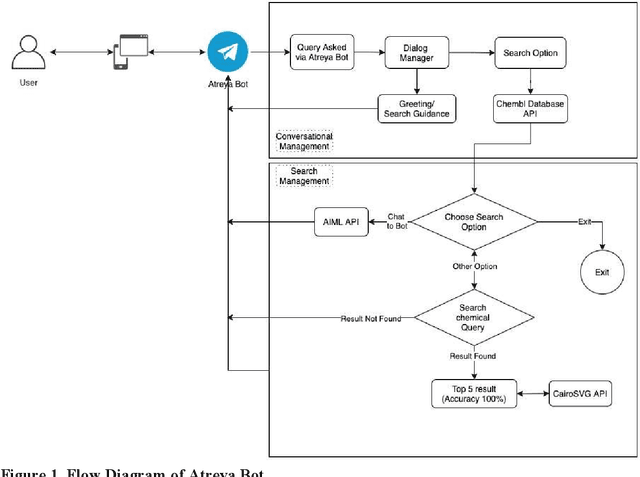
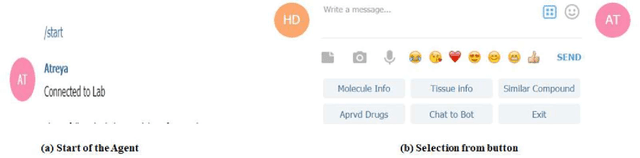
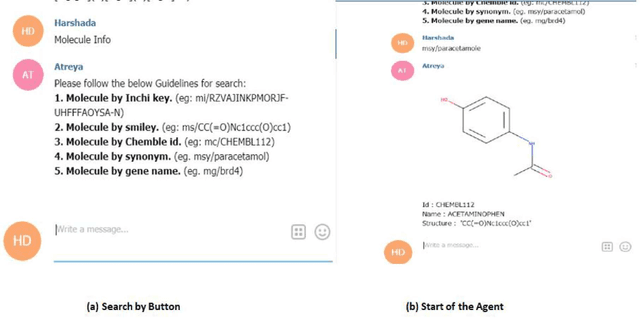

Conversational agents are a recent trend in human-computer interaction, deployed in multidisciplinary applications to assist the users. In this paper, we introduce "Atreya", an interactive bot for chemistry enthusiasts, researchers, and students to study the ChEMBL database. Atreya is hosted by Telegram, a popular cloud-based instant messaging application. This user-friendly bot queries the ChEMBL database, retrieves the drug details for a particular disease, targets associated with that drug, etc. This paper explores the potential of using a conversational agent to assist chemistry students and chemical scientist in complex information seeking process.