 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy AI-Generated Text Detection Fails: Evidence from Explainable AI Beyond Benchmark Accuracy
Mar 24, 2026The widespread adoption of Large Language Models (LLMs) has made the detection of AI-Generated text a pressing and complex challenge. Although many detection systems report high benchmark accuracy, their reliability in real-world settings remains uncertain, and their interpretability is often unexplored. In this work, we investigate whether contemporary detectors genuinely identify machine authorship or merely exploit dataset-specific artefacts. We propose an interpretable detection framework that integrates linguistic feature engineering, machine learning, and explainable AI techniques. When evaluated on two prominent benchmark corpora, namely PAN CLEF 2025 and COLING 2025, our model trained on 30 linguistic features achieves leaderboard-competitive performance, attaining an F1 score of 0.9734. However, systematic cross-domain and cross-generator evaluation reveals substantial generalisation failure: classifiers that excel in-domain degrade significantly under distribution shift. Using SHAP- based explanations, we show that the most influential features differ markedly between datasets, indicating that detectors often rely on dataset-specific stylistic cues rather than stable signals of machine authorship. Further investigation with in-depth error analysis exposes a fundamental tension in linguistic-feature-based AI text detection: the features that are most discriminative on in-domain data are also the features most susceptible to domain shift, formatting variation, and text-length effects. We believe that this knowledge helps build AI detectors that are robust across different settings. To support replication and practical use, we release an open-source Python package that returns both predictions and instance-level explanations for individual texts.
From Idea to Implementation: Evaluating the Influence of Large Language Models in Software Development -- An Opinion Paper
Mar 10, 2025The introduction of transformer architecture was a turning point in Natural Language Processing (NLP). Models based on the transformer architecture such as Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-Trained Transformer (GPT) have gained widespread popularity in various applications such as software development and education. The availability of Large Language Models (LLMs) such as ChatGPT and Bard to the general public has showcased the tremendous potential of these models and encouraged their integration into various domains such as software development for tasks such as code generation, debugging, and documentation generation. In this study, opinions from 11 experts regarding their experience with LLMs for software development have been gathered and analysed to draw insights that can guide successful and responsible integration. The overall opinion of the experts is positive, with the experts identifying advantages such as increase in productivity and reduced coding time. Potential concerns and challenges such as risk of over-dependence and ethical considerations have also been highlighted.
Exploring the Impact of Generative Artificial Intelligence in Education: A Thematic Analysis
Jan 17, 2025



The recent advancements in Generative Artificial intelligence (GenAI) technology have been transformative for the field of education. Large Language Models (LLMs) such as ChatGPT and Bard can be leveraged to automate boilerplate tasks, create content for personalised teaching, and handle repetitive tasks to allow more time for creative thinking. However, it is important to develop guidelines, policies, and assessment methods in the education sector to ensure the responsible integration of these tools. In this article, thematic analysis has been performed on seven essays obtained from professionals in the education sector to understand the advantages and pitfalls of using GenAI models such as ChatGPT and Bard in education. Exploratory Data Analysis (EDA) has been performed on the essays to extract further insights from the text. The study found several themes which highlight benefits and drawbacks of GenAI tools, as well as suggestions to overcome these limitations and ensure that students are using these tools in a responsible and ethical manner.
A Deep Learning Model for Heterogeneous Dataset Analysis -- Application to Winter Wheat Crop Yield Prediction
Jun 20, 2023Western countries rely heavily on wheat, and yield prediction is crucial. Time-series deep learning models, such as Long Short Term Memory (LSTM), have already been explored and applied to yield prediction. Existing literature reported that they perform better than traditional Machine Learning (ML) models. However, the existing LSTM cannot handle heterogeneous datasets (a combination of data which varies and remains static with time). In this paper, we propose an efficient deep learning model that can deal with heterogeneous datasets. We developed the system architecture and applied it to the real-world dataset in the digital agriculture area. We showed that it outperforms the existing ML models.
Enhancing Legal Argument Mining with Domain Pre-training and Neural Networks
Apr 06, 2022
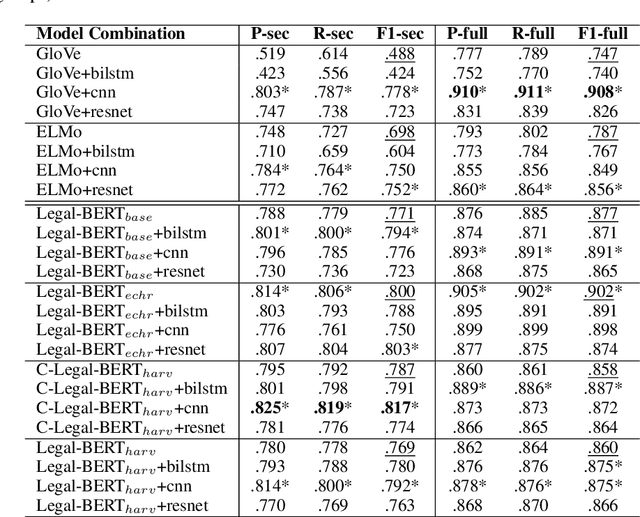
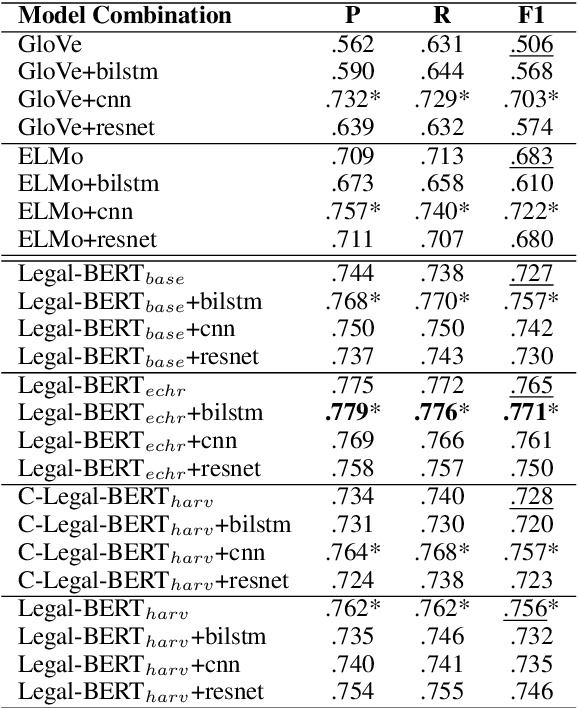
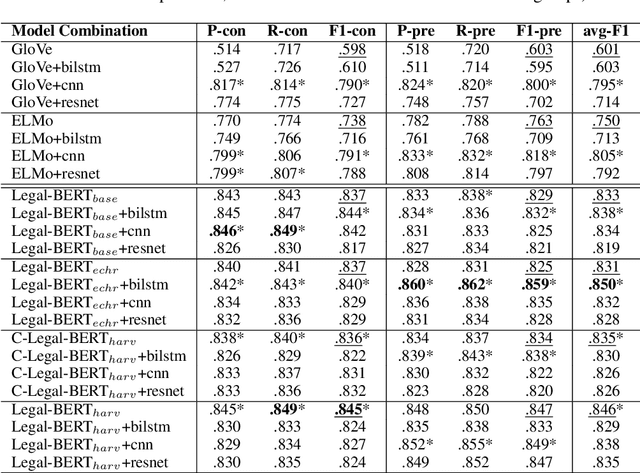
The contextual word embedding model, BERT, has proved its ability on downstream tasks with limited quantities of annotated data. BERT and its variants help to reduce the burden of complex annotation work in many interdisciplinary research areas, for example, legal argument mining in digital humanities. Argument mining aims to develop text analysis tools that can automatically retrieve arguments and identify relationships between argumentation clauses. Since argumentation is one of the key aspects of case law, argument mining tools for legal texts are applicable to both academic and non-academic legal research. Domain-specific BERT variants (pre-trained with corpora from a particular background) have also achieved strong performance in many tasks. To our knowledge, previous machine learning studies of argument mining on judicial case law still heavily rely on statistical models. In this paper, we provide a broad study of both classic and contextual embedding models and their performance on practical case law from the European Court of Human Rights (ECHR). During our study, we also explore a number of neural networks when being combined with different embeddings. Our experiments provide a comprehensive overview of a variety of approaches to the legal argument mining task. We conclude that domain pre-trained transformer models have great potential in this area, although traditional embeddings can also achieve strong performance when combined with additional neural network layers.
UCD-CS at TREC 2021 Incident Streams Track
Dec 07, 2021
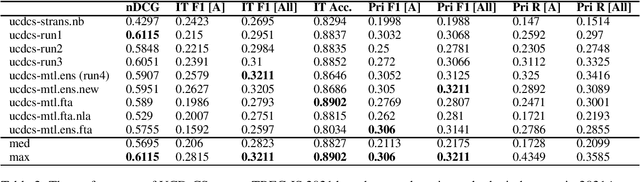
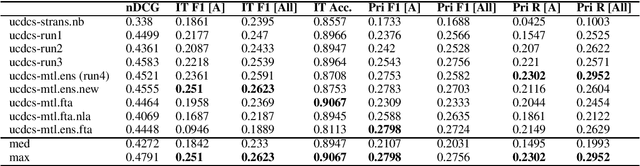
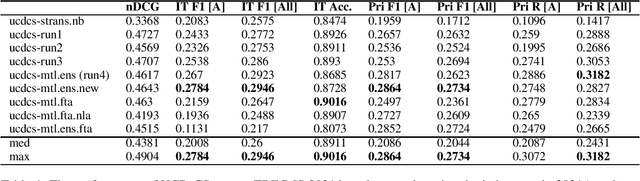
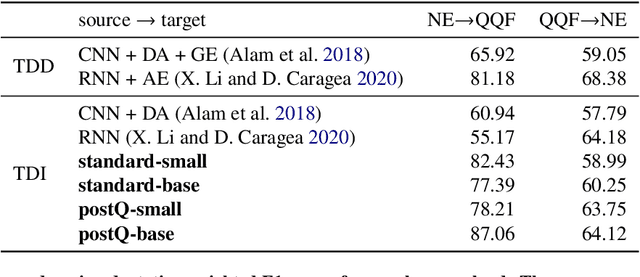
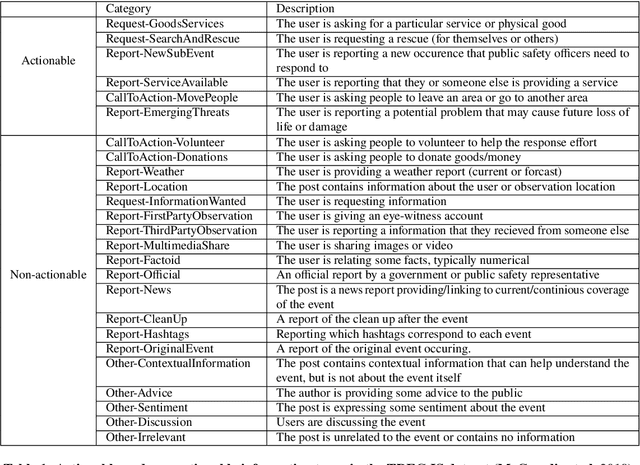
In recent years, the task of mining important information from social media posts during crises has become a focus of research for the purposes of assisting emergency response (ES). The TREC Incident Streams (IS) track is a research challenge organised for this purpose. The track asks participating systems to both classify a stream of crisis-related tweets into humanitarian aid related information types and estimate their importance regarding criticality. The former refers to a multi-label information type classification task and the latter refers to a priority estimation task. In this paper, we report on the participation of the University College Dublin School of Computer Science (UCD-CS) in TREC-IS 2021. We explored a variety of approaches, including simple machine learning algorithms, multi-task learning techniques, text augmentation, and ensemble approaches. The official evaluation results indicate that our runs achieve the highest scores in many metrics. To aid reproducibility, our code is publicly available at https://github.com/wangcongcong123/crisis-mtl.
Crisis Domain Adaptation Using Sequence-to-sequence Transformers
Oct 15, 2021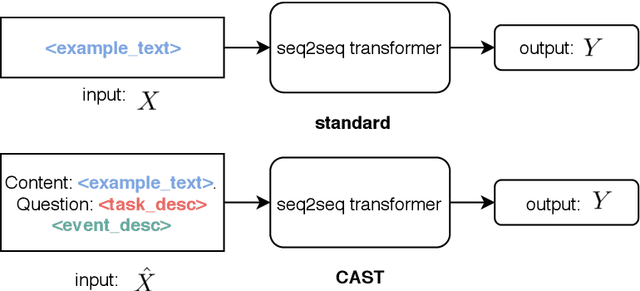
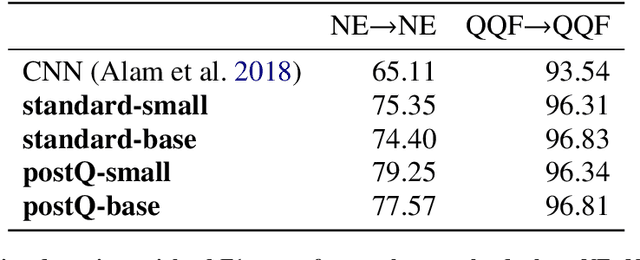

User-generated content (UGC) on social media can act as a key source of information for emergency responders in crisis situations. However, due to the volume concerned, computational techniques are needed to effectively filter and prioritise this content as it arises during emerging events. In the literature, these techniques are trained using annotated content from previous crises. In this paper, we investigate how this prior knowledge can be best leveraged for new crises by examining the extent to which crisis events of a similar type are more suitable for adaptation to new events (cross-domain adaptation). Given the recent successes of transformers in various language processing tasks, we propose CAST: an approach for Crisis domain Adaptation leveraging Sequence-to-sequence Transformers. We evaluate CAST using two major crisis-related message classification datasets. Our experiments show that our CAST-based best run without using any target data achieves the state of the art performance in both in-domain and cross-domain contexts. Moreover, CAST is particularly effective in one-to-one cross-domain adaptation when trained with a larger language model. In many-to-one adaptation where multiple crises are jointly used as the source domain, CAST further improves its performance. In addition, we find that more similar events are more likely to bring better adaptation performance whereas fine-tuning using dissimilar events does not help for adaptation. To aid reproducibility, we open source our code to the community.
Transformer-based Multi-task Learning for Disaster Tweet Categorisation
Oct 15, 2021
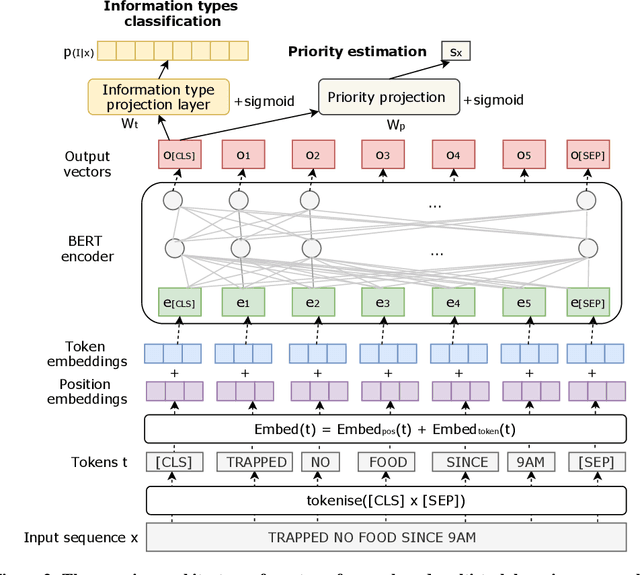
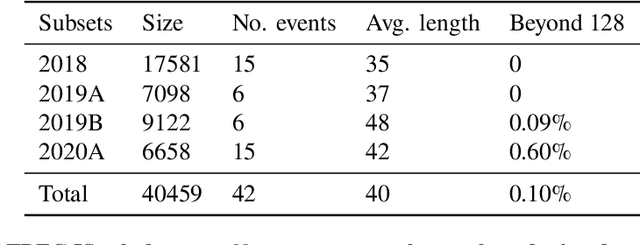
Social media has enabled people to circulate information in a timely fashion, thus motivating people to post messages seeking help during crisis situations. These messages can contribute to the situational awareness of emergency responders, who have a need for them to be categorised according to information types (i.e. the type of aid services the messages are requesting). We introduce a transformer-based multi-task learning (MTL) technique for classifying information types and estimating the priority of these messages. We evaluate the effectiveness of our approach with a variety of metrics by submitting runs to the TREC Incident Streams (IS) track: a research initiative specifically designed for disaster tweet classification and prioritisation. The results demonstrate that our approach achieves competitive performance in most metrics as compared to other participating runs. Subsequently, we find that an ensemble approach combining disparate transformer encoders within our approach helps to improve the overall effectiveness to a significant extent, achieving state-of-the-art performance in almost every metric. We make the code publicly available so that our work can be reproduced and used as a baseline for the community for future work in this domain.
Multi-task transfer learning for finding actionable information from crisis-related messages on social media
Feb 26, 2021
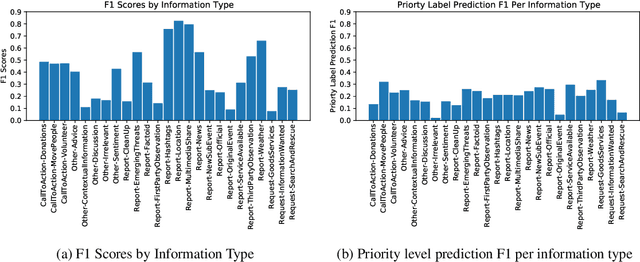
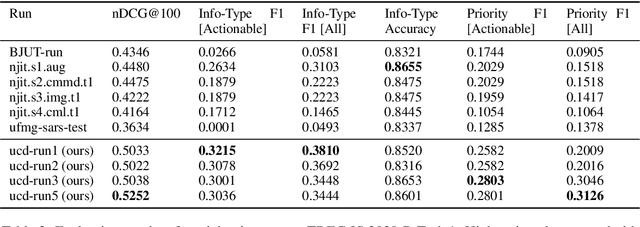
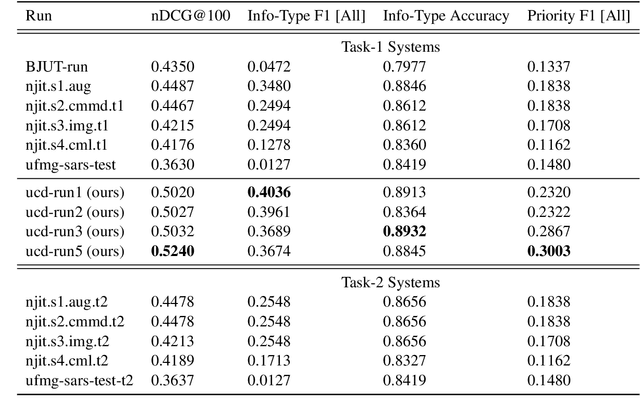
The Incident streams (IS) track is a research challenge aimed at finding important information from social media during crises for emergency response purposes. More specifically, given a stream of crisis-related tweets, the IS challenge asks a participating system to 1) classify what the types of users' concerns or needs are expressed in each tweet, known as the information type (IT) classification task and 2) estimate how critical each tweet is with regard to emergency response, known as the priority level prediction task. In this paper, we describe our multi-task transfer learning approach for this challenge. Our approach leverages state-of-the-art transformer models including both encoder-based models such as BERT and a sequence-to-sequence based T5 for joint transfer learning on the two tasks. Based on this approach, we submitted several runs to the track. The returned evaluation results show that our runs substantially outperform other participating runs in both IT classification and priority level prediction.
Assessing the Influencing Factors on the Accuracy of Underage Facial Age Estimation
Dec 02, 2020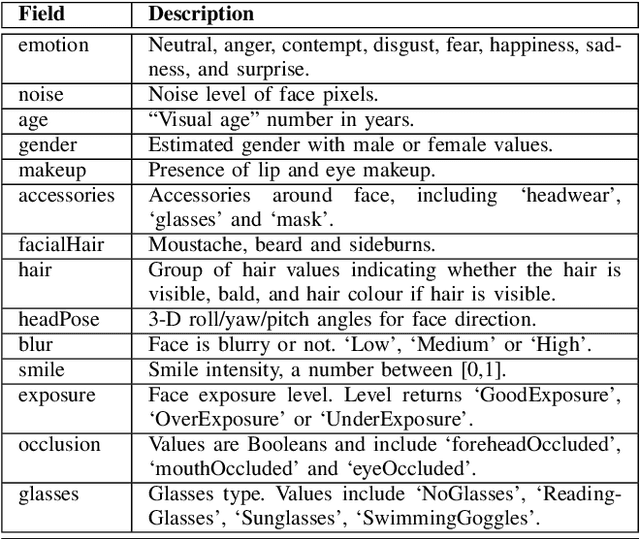
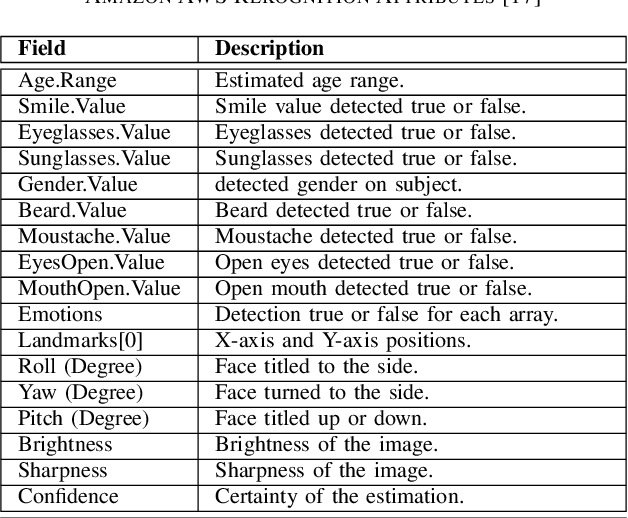
Swift response to the detection of endangered minors is an ongoing concern for law enforcement. Many child-focused investigations hinge on digital evidence discovery and analysis. Automated age estimation techniques are needed to aid in these investigations to expedite this evidence discovery process, and decrease investigator exposure to traumatic material. Automated techniques also show promise in decreasing the overflowing backlog of evidence obtained from increasing numbers of devices and online services. A lack of sufficient training data combined with natural human variance has been long hindering accurate automated age estimation -- especially for underage subjects. This paper presented a comprehensive evaluation of the performance of two cloud age estimation services (Amazon Web Service's Rekognition service and Microsoft Azure's Face API) against a dataset of over 21,800 underage subjects. The objective of this work is to evaluate the influence that certain human biometric factors, facial expressions, and image quality (i.e. blur, noise, exposure and resolution) have on the outcome of automated age estimation services. A thorough evaluation allows us to identify the most influential factors to be overcome in future age estimation systems.