 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
COSINT-Agent: A Knowledge-Driven Multimodal Agent for Chinese Open Source Intelligence
Mar 05, 2025


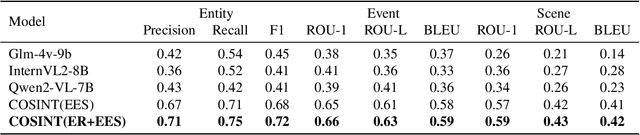
Open Source Intelligence (OSINT) requires the integration and reasoning of diverse multimodal data, presenting significant challenges in deriving actionable insights. Traditional approaches, including multimodal large language models (MLLMs), often struggle to infer complex contextual relationships or deliver comprehensive intelligence from unstructured data sources. In this paper, we introduce COSINT-Agent, a knowledge-driven multimodal agent tailored to address the challenges of OSINT in the Chinese domain. COSINT-Agent seamlessly integrates the perceptual capabilities of fine-tuned MLLMs with the structured reasoning power of the Entity-Event-Scene Knowledge Graph (EES-KG). Central to COSINT-Agent is the innovative EES-Match framework, which bridges COSINT-MLLM and EES-KG, enabling systematic extraction, reasoning, and contextualization of multimodal insights. This integration facilitates precise entity recognition, event interpretation, and context retrieval, effectively transforming raw multimodal data into actionable intelligence. Extensive experiments validate the superior performance of COSINT-Agent across core OSINT tasks, including entity recognition, EES generation, and context matching. These results underscore its potential as a robust and scalable solution for advancing automated multimodal reasoning and enhancing the effectiveness of OSINT methodologies.
Coping with low data availability for social media crisis message categorisation
May 26, 2023



During crisis situations, social media allows people to quickly share information, including messages requesting help. This can be valuable to emergency responders, who need to categorise and prioritise these messages based on the type of assistance being requested. However, the high volume of messages makes it difficult to filter and prioritise them without the use of computational techniques. Fully supervised filtering techniques for crisis message categorisation typically require a large amount of annotated training data, but this can be difficult to obtain during an ongoing crisis and is expensive in terms of time and labour to create. This thesis focuses on addressing the challenge of low data availability when categorising crisis messages for emergency response. It first presents domain adaptation as a solution for this problem, which involves learning a categorisation model from annotated data from past crisis events (source domain) and adapting it to categorise messages from an ongoing crisis event (target domain). In many-to-many adaptation, where the model is trained on multiple past events and adapted to multiple ongoing events, a multi-task learning approach is proposed using pre-trained language models. This approach outperforms baselines and an ensemble approach further improves performance...
STA: Self-controlled Text Augmentation for Improving Text Classifications
Feb 24, 2023

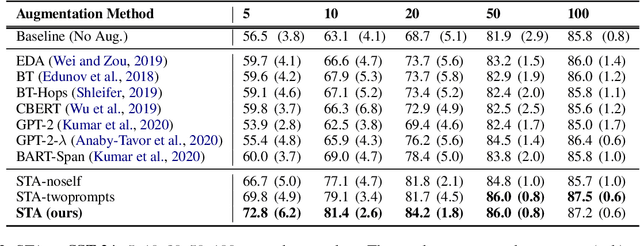
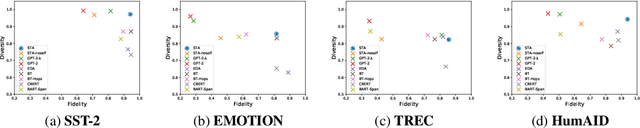
Despite recent advancements in Machine Learning, many tasks still involve working in low-data regimes which can make solving natural language problems difficult. Recently, a number of text augmentation techniques have emerged in the field of Natural Language Processing (NLP) which can enrich the training data with new examples, though they are not without their caveats. For instance, simple rule-based heuristic methods are effective, but lack variation in semantic content and syntactic structure with respect to the original text. On the other hand, more complex deep learning approaches can cause extreme shifts in the intrinsic meaning of the text and introduce unwanted noise into the training data. To more reliably control the quality of the augmented examples, we introduce a state-of-the-art approach for Self-Controlled Text Augmentation (STA). Our approach tightly controls the generation process by introducing a self-checking procedure to ensure that generated examples retain the semantic content of the original text. Experimental results on multiple benchmarking datasets demonstrate that STA substantially outperforms existing state-of-the-art techniques, whilst qualitative analysis reveals that the generated examples are both lexically diverse and semantically reliable.
UCD-CS at TREC 2021 Incident Streams Track
Dec 07, 2021
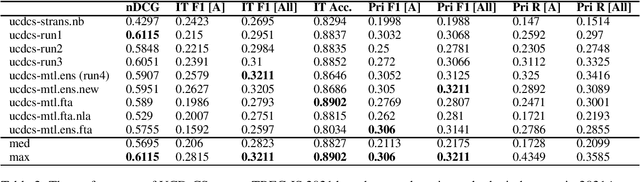
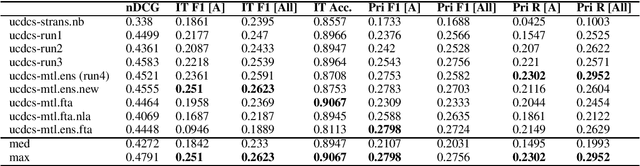
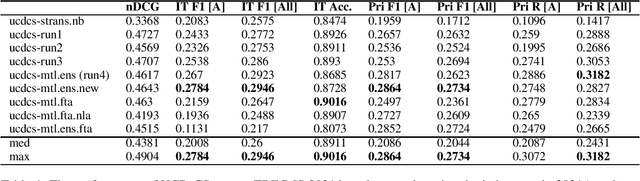
In recent years, the task of mining important information from social media posts during crises has become a focus of research for the purposes of assisting emergency response (ES). The TREC Incident Streams (IS) track is a research challenge organised for this purpose. The track asks participating systems to both classify a stream of crisis-related tweets into humanitarian aid related information types and estimate their importance regarding criticality. The former refers to a multi-label information type classification task and the latter refers to a priority estimation task. In this paper, we report on the participation of the University College Dublin School of Computer Science (UCD-CS) in TREC-IS 2021. We explored a variety of approaches, including simple machine learning algorithms, multi-task learning techniques, text augmentation, and ensemble approaches. The official evaluation results indicate that our runs achieve the highest scores in many metrics. To aid reproducibility, our code is publicly available at https://github.com/wangcongcong123/crisis-mtl.
Crisis Domain Adaptation Using Sequence-to-sequence Transformers
Oct 15, 2021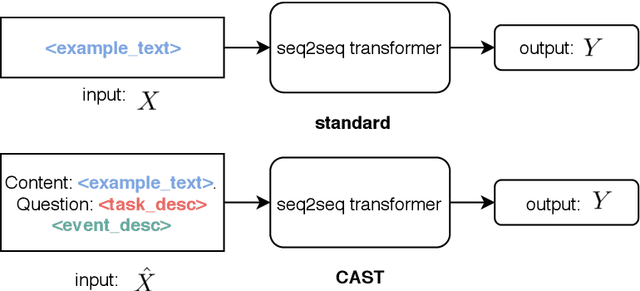
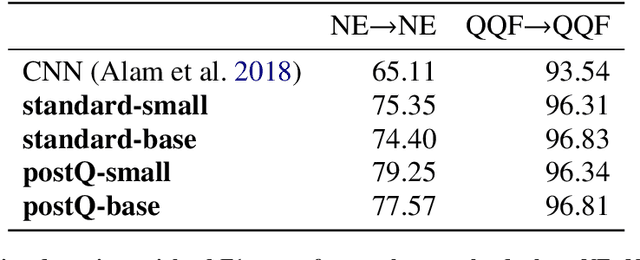

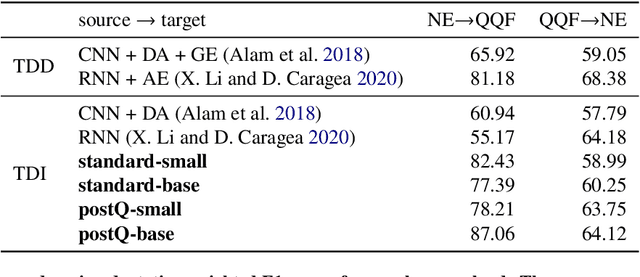
User-generated content (UGC) on social media can act as a key source of information for emergency responders in crisis situations. However, due to the volume concerned, computational techniques are needed to effectively filter and prioritise this content as it arises during emerging events. In the literature, these techniques are trained using annotated content from previous crises. In this paper, we investigate how this prior knowledge can be best leveraged for new crises by examining the extent to which crisis events of a similar type are more suitable for adaptation to new events (cross-domain adaptation). Given the recent successes of transformers in various language processing tasks, we propose CAST: an approach for Crisis domain Adaptation leveraging Sequence-to-sequence Transformers. We evaluate CAST using two major crisis-related message classification datasets. Our experiments show that our CAST-based best run without using any target data achieves the state of the art performance in both in-domain and cross-domain contexts. Moreover, CAST is particularly effective in one-to-one cross-domain adaptation when trained with a larger language model. In many-to-one adaptation where multiple crises are jointly used as the source domain, CAST further improves its performance. In addition, we find that more similar events are more likely to bring better adaptation performance whereas fine-tuning using dissimilar events does not help for adaptation. To aid reproducibility, we open source our code to the community.
Transformer-based Multi-task Learning for Disaster Tweet Categorisation
Oct 15, 2021
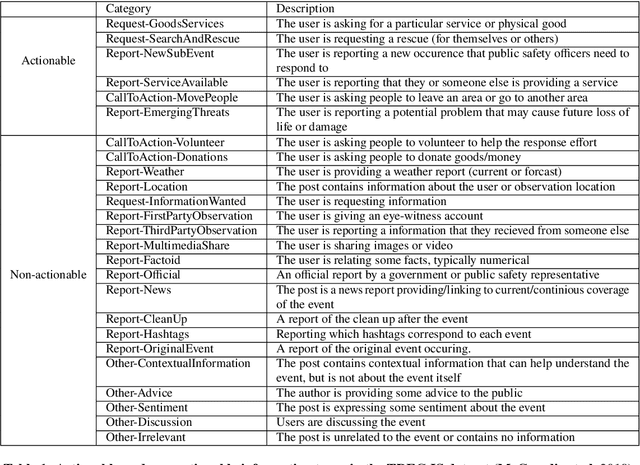
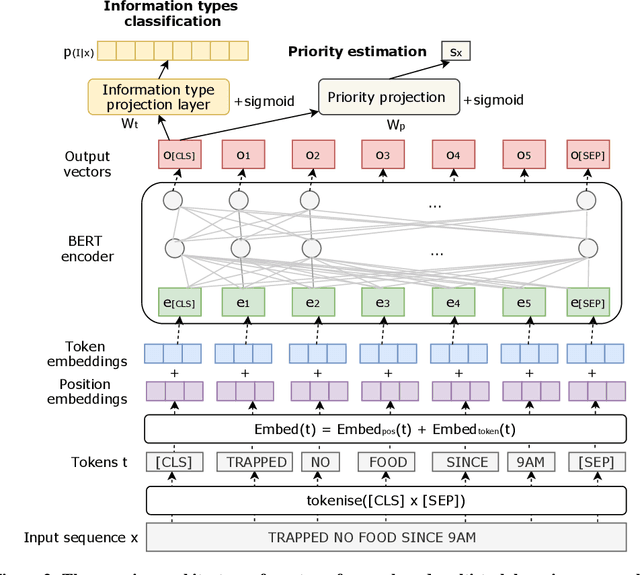
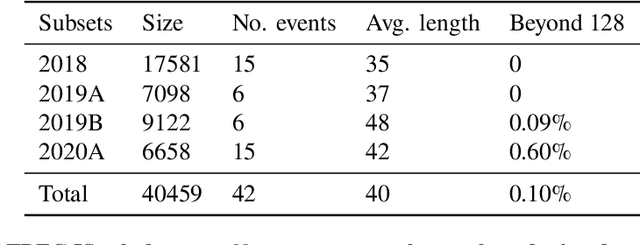
Social media has enabled people to circulate information in a timely fashion, thus motivating people to post messages seeking help during crisis situations. These messages can contribute to the situational awareness of emergency responders, who have a need for them to be categorised according to information types (i.e. the type of aid services the messages are requesting). We introduce a transformer-based multi-task learning (MTL) technique for classifying information types and estimating the priority of these messages. We evaluate the effectiveness of our approach with a variety of metrics by submitting runs to the TREC Incident Streams (IS) track: a research initiative specifically designed for disaster tweet classification and prioritisation. The results demonstrate that our approach achieves competitive performance in most metrics as compared to other participating runs. Subsequently, we find that an ensemble approach combining disparate transformer encoders within our approach helps to improve the overall effectiveness to a significant extent, achieving state-of-the-art performance in almost every metric. We make the code publicly available so that our work can be reproduced and used as a baseline for the community for future work in this domain.
Multi-task transfer learning for finding actionable information from crisis-related messages on social media
Feb 26, 2021
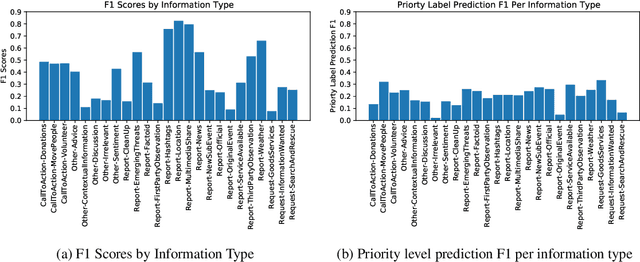
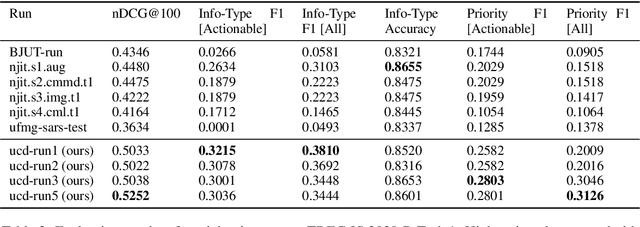
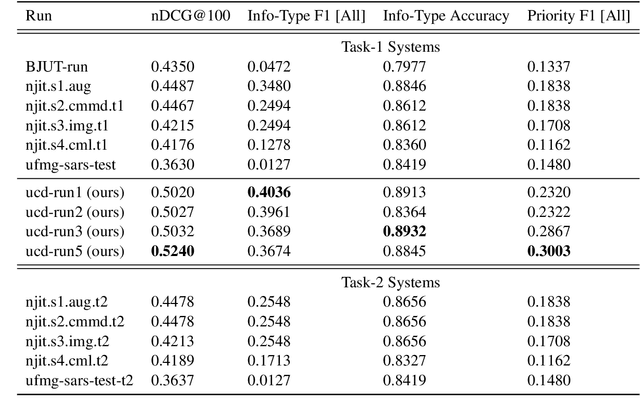
The Incident streams (IS) track is a research challenge aimed at finding important information from social media during crises for emergency response purposes. More specifically, given a stream of crisis-related tweets, the IS challenge asks a participating system to 1) classify what the types of users' concerns or needs are expressed in each tweet, known as the information type (IT) classification task and 2) estimate how critical each tweet is with regard to emergency response, known as the priority level prediction task. In this paper, we describe our multi-task transfer learning approach for this challenge. Our approach leverages state-of-the-art transformer models including both encoder-based models such as BERT and a sequence-to-sequence based T5 for joint transfer learning on the two tasks. Based on this approach, we submitted several runs to the track. The returned evaluation results show that our runs substantially outperform other participating runs in both IT classification and priority level prediction.
Stereo Correspondence and Reconstruction of Endoscopic Data Challenge
Jan 28, 2021

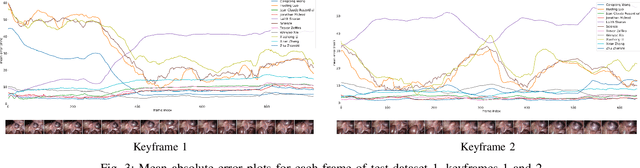
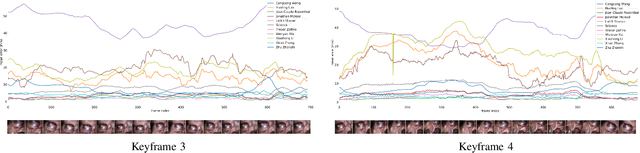
The stereo correspondence and reconstruction of endoscopic data sub-challenge was organized during the Endovis challenge at MICCAI 2019 in Shenzhen, China. The task was to perform dense depth estimation using 7 training datasets and 2 test sets of structured light data captured using porcine cadavers. These were provided by a team at Intuitive Surgical. 10 teams participated in the challenge day. This paper contains 3 additional methods which were submitted after the challenge finished as well as a supplemental section from these teams on issues they found with the dataset.