 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Forecast After the Forecast: A Post-Processing Shift in Time Series
Jan 28, 2026Time series forecasting has long been dominated by advances in model architecture, with recent progress driven by deep learning and hybrid statistical techniques. However, as forecasting models approach diminishing returns in accuracy, a critical yet underexplored opportunity emerges: the strategic use of post-processing. In this paper, we address the last-mile gap in time-series forecasting, which is to improve accuracy and uncertainty without retraining or modifying a deployed backbone. We propose $δ$-Adapter, a lightweight, architecture-agnostic way to boost deployed time series forecasters without retraining. $δ$-Adapter learns tiny, bounded modules at two interfaces: input nudging (soft edits to covariates) and output residual correction. We provide local descent guarantees, $O(δ)$ drift bounds, and compositional stability for combined adapters. Meanwhile, it can act as a feature selector by learning a sparse, horizon-aware mask over inputs to select important features, thereby improving interpretability. In addition, it can also be used as a distribution calibrator to measure uncertainty. Thus, we introduce a Quantile Calibrator and a Conformal Corrector that together deliver calibrated, personalized intervals with finite-sample coverage. Our experiments across diverse backbones and datasets show that $δ$-Adapter improves accuracy and calibration with negligible compute and no interface changes.
* 30 Pages
Information Bottleneck-based Causal Attention for Multi-label Medical Image Recognition
Aug 11, 2025Multi-label classification (MLC) of medical images aims to identify multiple diseases and holds significant clinical potential. A critical step is to learn class-specific features for accurate diagnosis and improved interpretability effectively. However, current works focus primarily on causal attention to learn class-specific features, yet they struggle to interpret the true cause due to the inadvertent attention to class-irrelevant features. To address this challenge, we propose a new structural causal model (SCM) that treats class-specific attention as a mixture of causal, spurious, and noisy factors, and a novel Information Bottleneck-based Causal Attention (IBCA) that is capable of learning the discriminative class-specific attention for MLC of medical images. Specifically, we propose learning Gaussian mixture multi-label spatial attention to filter out class-irrelevant information and capture each class-specific attention pattern. Then a contrastive enhancement-based causal intervention is proposed to gradually mitigate the spurious attention and reduce noise information by aligning multi-head attention with the Gaussian mixture multi-label spatial. Quantitative and ablation results on Endo and MuReD show that IBCA outperforms all methods. Compared to the second-best results for each metric, IBCA achieves improvements of 6.35\% in CR, 7.72\% in OR, and 5.02\% in mAP for MuReD, 1.47\% in CR, and 1.65\% in CF1, and 1.42\% in mAP for Endo.
COSINT-Agent: A Knowledge-Driven Multimodal Agent for Chinese Open Source Intelligence
Mar 05, 2025


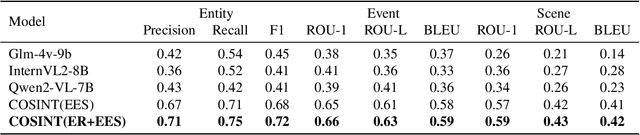
Open Source Intelligence (OSINT) requires the integration and reasoning of diverse multimodal data, presenting significant challenges in deriving actionable insights. Traditional approaches, including multimodal large language models (MLLMs), often struggle to infer complex contextual relationships or deliver comprehensive intelligence from unstructured data sources. In this paper, we introduce COSINT-Agent, a knowledge-driven multimodal agent tailored to address the challenges of OSINT in the Chinese domain. COSINT-Agent seamlessly integrates the perceptual capabilities of fine-tuned MLLMs with the structured reasoning power of the Entity-Event-Scene Knowledge Graph (EES-KG). Central to COSINT-Agent is the innovative EES-Match framework, which bridges COSINT-MLLM and EES-KG, enabling systematic extraction, reasoning, and contextualization of multimodal insights. This integration facilitates precise entity recognition, event interpretation, and context retrieval, effectively transforming raw multimodal data into actionable intelligence. Extensive experiments validate the superior performance of COSINT-Agent across core OSINT tasks, including entity recognition, EES generation, and context matching. These results underscore its potential as a robust and scalable solution for advancing automated multimodal reasoning and enhancing the effectiveness of OSINT methodologies.