 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Large-Scale Cross-Domain Sequential Recommendation with Dynamic State Representations
Aug 28, 2025Recently, autoregressive recommendation models (ARMs), such as Meta's HSTU model, have emerged as a major breakthrough over traditional Deep Learning Recommendation Models (DLRMs), exhibiting the highly sought-after scaling law behaviour. However, when applied to multi-domain scenarios, the transformer architecture's attention maps become a computational bottleneck, as they attend to all items across every domain. To tackle this challenge, systems must efficiently balance inter and intra-domain knowledge transfer. In this work, we introduce a novel approach for scalable multi-domain recommendation systems by replacing full inter-domain attention with two innovative mechanisms: 1) Transition-Aware Positional Embeddings (TAPE): We propose novel positional embeddings that account for domain-transition specific information. This allows attention to be focused solely on intra-domain items, effectively reducing the unnecessary computational cost associated with attending to irrelevant domains. 2) Dynamic Domain State Representation (DDSR): We introduce a dynamic state representation for each domain, which is stored and accessed during subsequent token predictions. This enables the efficient transfer of relevant domain information without relying on full attention maps. Our method offers a scalable solution to the challenges posed by large-scale, multi-domain recommendation systems and demonstrates significant improvements in retrieval tasks by separately modelling and combining inter- and intra-domain representations.
STA: Self-controlled Text Augmentation for Improving Text Classifications
Feb 24, 2023

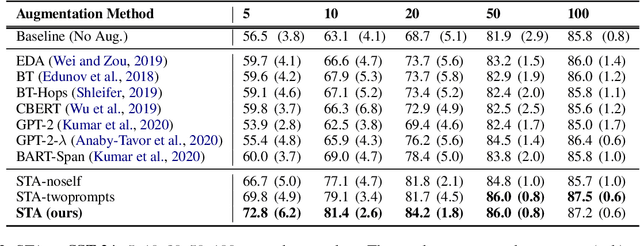
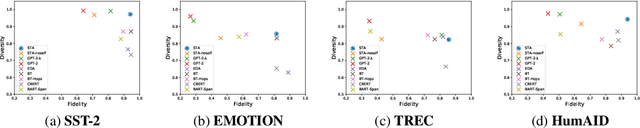
Despite recent advancements in Machine Learning, many tasks still involve working in low-data regimes which can make solving natural language problems difficult. Recently, a number of text augmentation techniques have emerged in the field of Natural Language Processing (NLP) which can enrich the training data with new examples, though they are not without their caveats. For instance, simple rule-based heuristic methods are effective, but lack variation in semantic content and syntactic structure with respect to the original text. On the other hand, more complex deep learning approaches can cause extreme shifts in the intrinsic meaning of the text and introduce unwanted noise into the training data. To more reliably control the quality of the augmented examples, we introduce a state-of-the-art approach for Self-Controlled Text Augmentation (STA). Our approach tightly controls the generation process by introducing a self-checking procedure to ensure that generated examples retain the semantic content of the original text. Experimental results on multiple benchmarking datasets demonstrate that STA substantially outperforms existing state-of-the-art techniques, whilst qualitative analysis reveals that the generated examples are both lexically diverse and semantically reliable.
Quantitative Metrics for Evaluating Explanations of Video DeepFake Detectors
Oct 07, 2022
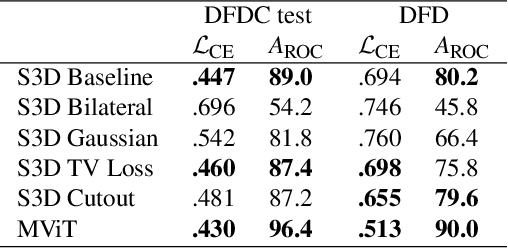
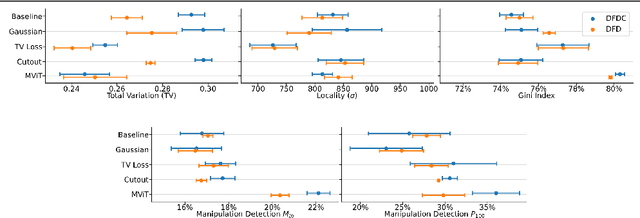
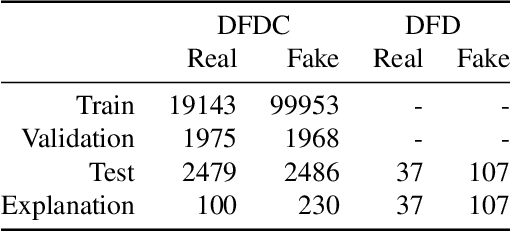
The proliferation of DeepFake technology is a rising challenge in today's society, owing to more powerful and accessible generation methods. To counter this, the research community has developed detectors of ever-increasing accuracy. However, the ability to explain the decisions of such models to users is lacking behind and is considered an accessory in large-scale benchmarks, despite being a crucial requirement for the correct deployment of automated tools for content moderation. We attribute the issue to the reliance on qualitative comparisons and the lack of established metrics. We describe a simple set of metrics to evaluate the visual quality and informativeness of explanations of video DeepFake classifiers from a human-centric perspective. With these metrics, we compare common approaches to improve explanation quality and discuss their effect on both classification and explanation performance on the recent DFDC and DFD datasets.