 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative Metrics for Evaluating Explanations of Video DeepFake Detectors
Oct 07, 2022
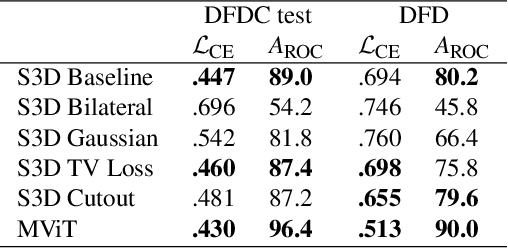
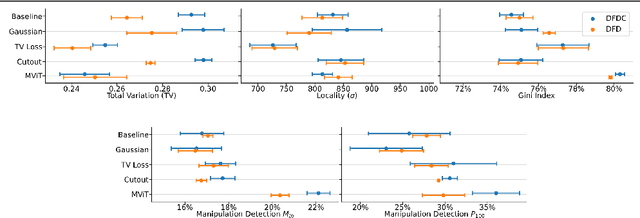
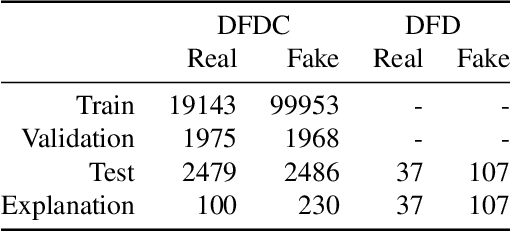
The proliferation of DeepFake technology is a rising challenge in today's society, owing to more powerful and accessible generation methods. To counter this, the research community has developed detectors of ever-increasing accuracy. However, the ability to explain the decisions of such models to users is lacking behind and is considered an accessory in large-scale benchmarks, despite being a crucial requirement for the correct deployment of automated tools for content moderation. We attribute the issue to the reliance on qualitative comparisons and the lack of established metrics. We describe a simple set of metrics to evaluate the visual quality and informativeness of explanations of video DeepFake classifiers from a human-centric perspective. With these metrics, we compare common approaches to improve explanation quality and discuss their effect on both classification and explanation performance on the recent DFDC and DFD datasets.
Learning 3D Navigation Protocols on Touch Interfaces with Cooperative Multi-Agent Reinforcement Learning
Apr 16, 2019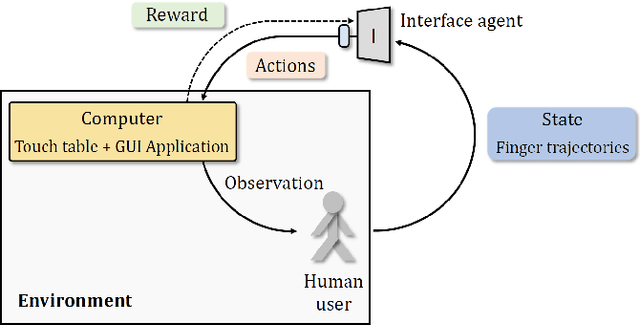
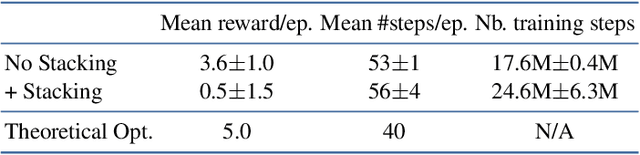
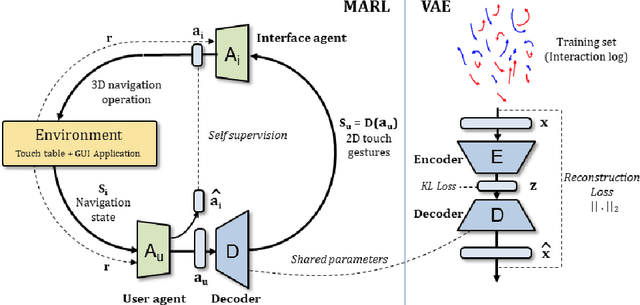
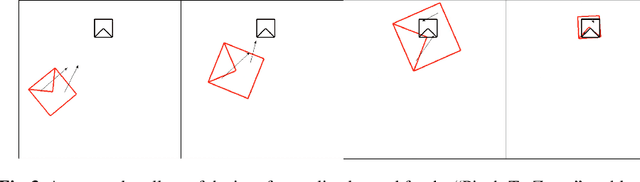
Using touch devices to navigate in virtual 3D environments such as computer assisted design (CAD) models or geographical information systems (GIS) is inherently difficult for humans, as the 3D operations have to be performed by the user on a 2D touch surface. This ill-posed problem is classically solved with a fixed and handcrafted interaction protocol, which must be learned by the user. We propose to automatically learn a new interaction protocol allowing to map a 2D user input to 3D actions in virtual environments using reinforcement learning (RL). A fundamental problem of RL methods is the vast amount of interactions often required, which are difficult to come by when humans are involved. To overcome this limitation, we make use of two collaborative agents. The first agent models the human by learning to perform the 2D finger trajectories. The second agent acts as the interaction protocol, interpreting and translating to 3D operations the 2D finger trajectories from the first agent. We restrict the learned 2D trajectories to be similar to a training set of collected human gestures by first performing state representation learning, prior to reinforcement learning. This state representation learning is addressed by projecting the gestures into a latent space learned by a variational auto encoder (VAE).
Learning to recognize touch gestures: recurrent vs. convolutional features and dynamic sampling
Feb 19, 2018

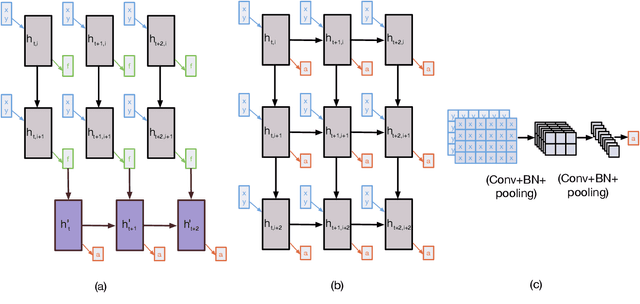
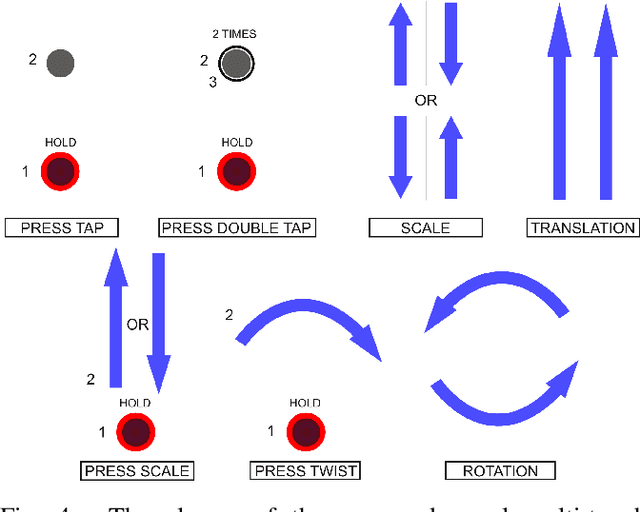
We propose a fully automatic method for learning gestures on big touch devices in a potentially multi-user context. The goal is to learn general models capable of adapting to different gestures, user styles and hardware variations (e.g. device sizes, sampling frequencies and regularities). Based on deep neural networks, our method features a novel dynamic sampling and temporal normalization component, transforming variable length gestures into fixed length representations while preserving finger/surface contact transitions, that is, the topology of the signal. This sequential representation is then processed with a convolutional model capable, unlike recurrent networks, of learning hierarchical representations with different levels of abstraction. To demonstrate the interest of the proposed method, we introduce a new touch gestures dataset with 6591 gestures performed by 27 people, which is, up to our knowledge, the first of its kind: a publicly available multi-touch gesture dataset for interaction. We also tested our method on a standard dataset of symbolic touch gesture recognition, the MMG dataset, outperforming the state of the art and reporting close to perfect performance.