 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically-admissible polarimetric data augmentation for road-scene analysis
Jun 15, 2022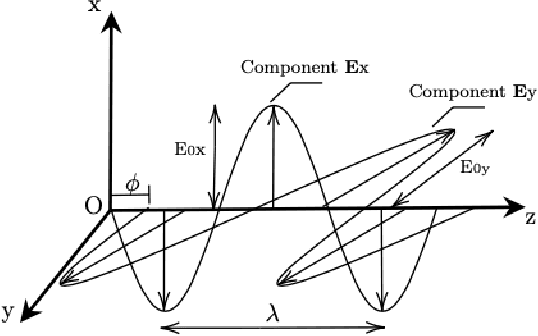
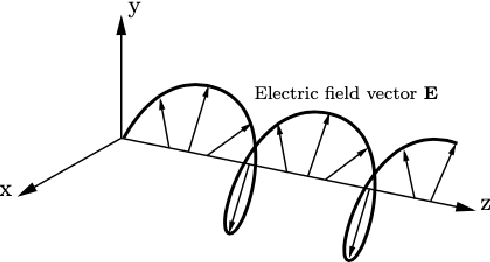
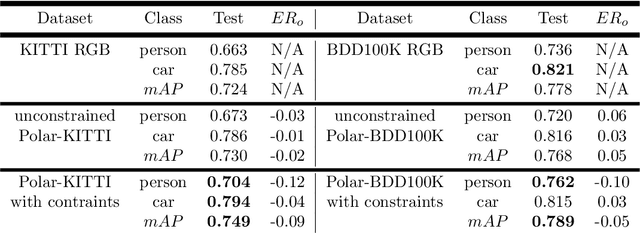
Polarimetric imaging, along with deep learning, has shown improved performances on different tasks including scene analysis. However, its robustness may be questioned because of the small size of the training datasets. Though the issue could be solved by data augmentation, polarization modalities are subject to physical feasibility constraints unaddressed by classical data augmentation techniques. To address this issue, we propose to use CycleGAN, an image translation technique based on deep generative models that solely relies on unpaired data, to transfer large labeled road scene datasets to the polarimetric domain. We design several auxiliary loss terms that, alongside the CycleGAN losses, deal with the physical constraints of polarimetric images. The efficiency of this solution is demonstrated on road scene object detection tasks where generated realistic polarimetric images allow to improve performances on cars and pedestrian detection up to 9%. The resulting constrained CycleGAN is publicly released, allowing anyone to generate their own polarimetric images.
A formal approach to good practices in Pseudo-Labeling for Unsupervised Domain Adaptive Re-Identification
Dec 28, 2021

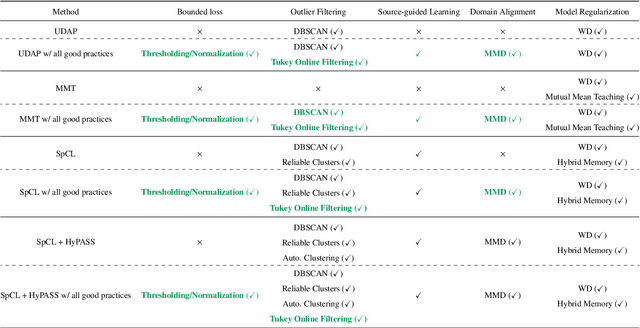
The use of pseudo-labels prevails in order to tackle Unsupervised Domain Adaptive (UDA) Re-Identification (re-ID) with the best performance. Indeed, this family of approaches has given rise to several UDA re-ID specific frameworks, which are effective. In these works, research directions to improve Pseudo-Labeling UDA re-ID performance are varied and mostly based on intuition and experiments: refining pseudo-labels, reducing the impact of errors in pseudo-labels... It can be hard to deduce from them general good practices, which can be implemented in any Pseudo-Labeling method, to consistently improve its performance. To address this key question, a new theoretical view on Pseudo-Labeling UDA re-ID is proposed. The contributions are threefold: (i) A novel theoretical framework for Pseudo-Labeling UDA re-ID, formalized through a new general learning upper-bound on the UDA re-ID performance. (ii) General good practices for Pseudo-Labeling, directly deduced from the interpretation of the proposed theoretical framework, in order to improve the target re-ID performance. (iii) Extensive experiments on challenging person and vehicle cross-dataset re-ID tasks, showing consistent performance improvements for various state-of-the-art methods and various proposed implementations of good practices.
Similarity Contrastive Estimation for Self-Supervised Soft Contrastive Learning
Nov 29, 2021



Contrastive representation learning has proven to be an effective self-supervised learning method. Most successful approaches are based on the Noise Contrastive Estimation (NCE) paradigm and consider different views of an instance as positives and other instances as noise that positives should be contrasted with. However, all instances in a dataset are drawn from the same distribution and share underlying semantic information that should not be considered as noise. We argue that a good data representation contains the relations, or semantic similarity, between the instances. Contrastive learning implicitly learns relations but considers the negatives as noise which is harmful to the quality of the learned relations and therefore the quality of the representation. To circumvent this issue we propose a novel formulation of contrastive learning using semantic similarity between instances called Similarity Contrastive Estimation (SCE). Our training objective can be considered as soft contrastive learning. Instead of hard classifying positives and negatives, we propose a continuous distribution to push or pull instances based on their semantic similarities. The target similarity distribution is computed from weak augmented instances and sharpened to eliminate irrelevant relations. Each weak augmented instance is paired with a strong augmented instance that contrasts its positive while maintaining the target similarity distribution. Experimental results show that our proposed SCE outperforms its baselines MoCov2 and ReSSL on various datasets and is competitive with state-of-the-art algorithms on the ImageNet linear evaluation protocol.
Feature-enhanced Generation and Multi-modality Fusion based Deep Neural Network for Brain Tumor Segmentation with Missing MR Modalities
Nov 08, 2021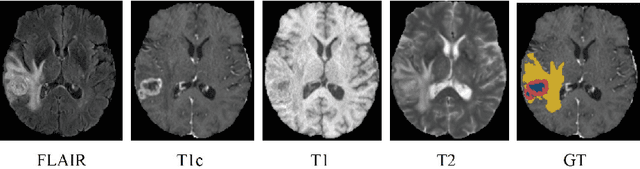
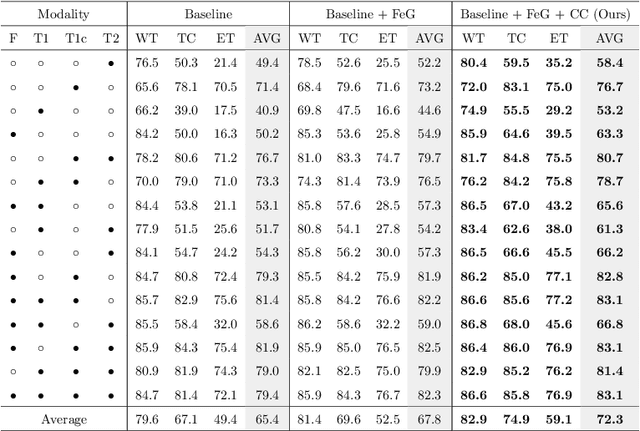
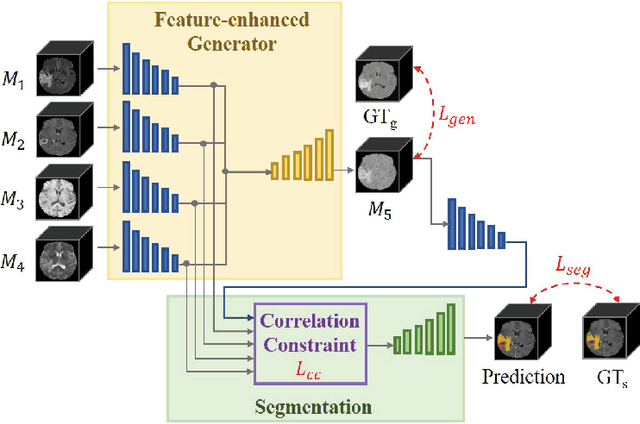
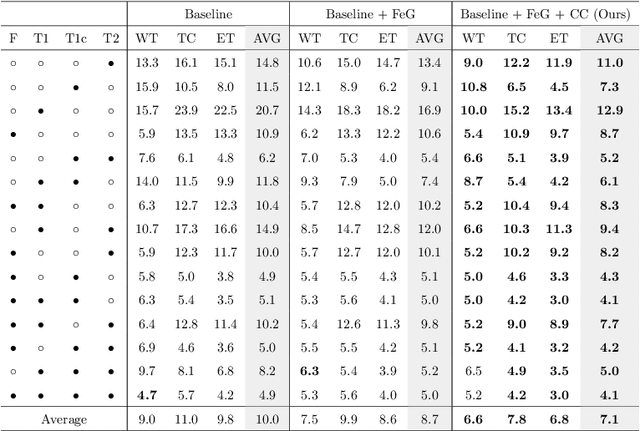
Using multimodal Magnetic Resonance Imaging (MRI) is necessary for accurate brain tumor segmentation. The main problem is that not all types of MRIs are always available in clinical exams. Based on the fact that there is a strong correlation between MR modalities of the same patient, in this work, we propose a novel brain tumor segmentation network in the case of missing one or more modalities. The proposed network consists of three sub-networks: a feature-enhanced generator, a correlation constraint block and a segmentation network. The feature-enhanced generator utilizes the available modalities to generate 3D feature-enhanced image representing the missing modality. The correlation constraint block can exploit the multi-source correlation between the modalities and also constrain the generator to synthesize a feature-enhanced modality which must have a coherent correlation with the available modalities. The segmentation network is a multi-encoder based U-Net to achieve the final brain tumor segmentation. The proposed method is evaluated on BraTS 2018 dataset. Experimental results demonstrate the effectiveness of the proposed method which achieves the average Dice Score of 82.9, 74.9 and 59.1 on whole tumor, tumor core and enhancing tumor, respectively across all the situations, and outperforms the best method by 3.5%, 17% and 18.2%.
* 30 pages, 7 figures
Improving Unsupervised Domain Adaptive Re-Identification via Source-Guided Selection of Pseudo-Labeling Hyperparameters
Nov 04, 2021
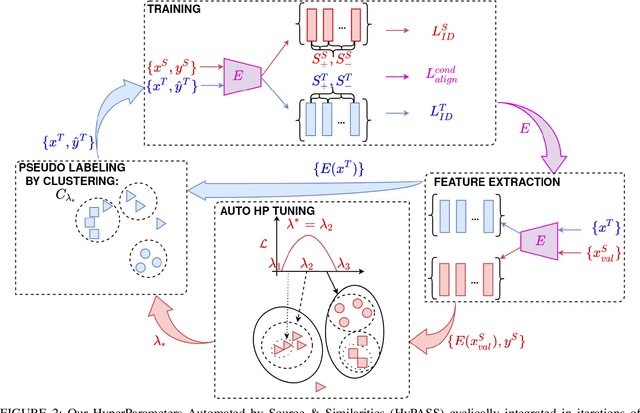

Unsupervised Domain Adaptation (UDA) for re-identification (re-ID) is a challenging task: to avoid a costly annotation of additional data, it aims at transferring knowledge from a domain with annotated data to a domain of interest with only unlabeled data. Pseudo-labeling approaches have proven to be effective for UDA re-ID. However, the effectiveness of these approaches heavily depends on the choice of some hyperparameters (HP) that affect the generation of pseudo-labels by clustering. The lack of annotation in the domain of interest makes this choice non-trivial. Current approaches simply reuse the same empirical value for all adaptation tasks and regardless of the target data representation that changes through pseudo-labeling training phases. As this simplistic choice may limit their performance, we aim at addressing this issue. We propose new theoretical grounds on HP selection for clustering UDA re-ID as well as method of automatic and cyclic HP tuning for pseudo-labeling UDA clustering: HyPASS. HyPASS consists in incorporating two modules in pseudo-labeling methods: (i) HP selection based on a labeled source validation set and (ii) conditional domain alignment of feature discriminativeness to improve HP selection based on source samples. Experiments on commonly used person re-ID and vehicle re-ID datasets show that our proposed HyPASS consistently improves the best state-of-the-art methods in re-ID compared to the commonly used empirical HP setting.
A Tri-attention Fusion Guided Multi-modal Segmentation Network
Nov 02, 2021
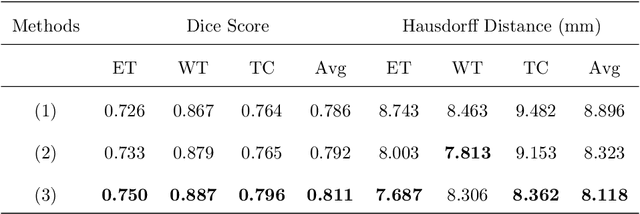
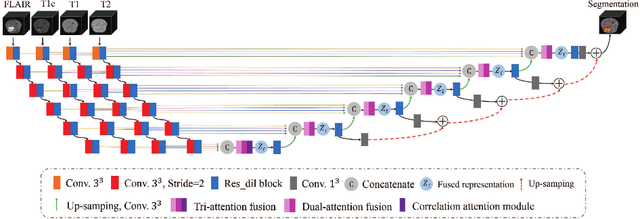
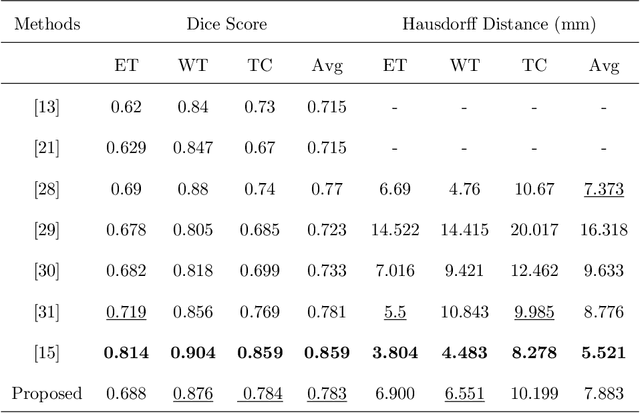
In the field of multimodal segmentation, the correlation between different modalities can be considered for improving the segmentation results. Considering the correlation between different MR modalities, in this paper, we propose a multi-modality segmentation network guided by a novel tri-attention fusion. Our network includes N model-independent encoding paths with N image sources, a tri-attention fusion block, a dual-attention fusion block, and a decoding path. The model independent encoding paths can capture modality-specific features from the N modalities. Considering that not all the features extracted from the encoders are useful for segmentation, we propose to use dual attention based fusion to re-weight the features along the modality and space paths, which can suppress less informative features and emphasize the useful ones for each modality at different positions. Since there exists a strong correlation between different modalities, based on the dual attention fusion block, we propose a correlation attention module to form the tri-attention fusion block. In the correlation attention module, a correlation description block is first used to learn the correlation between modalities and then a constraint based on the correlation is used to guide the network to learn the latent correlated features which are more relevant for segmentation. Finally, the obtained fused feature representation is projected by the decoder to obtain the segmentation results. Our experiment results tested on BraTS 2018 dataset for brain tumor segmentation demonstrate the effectiveness of our proposed method.
Conditional generator and multi-sourcecorrelation guided brain tumor segmentation with missing MR modalities
May 27, 2021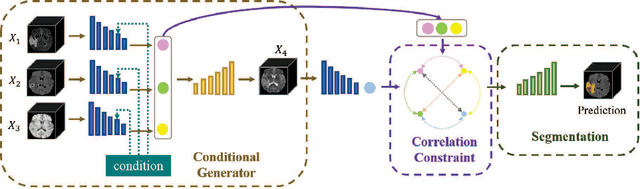
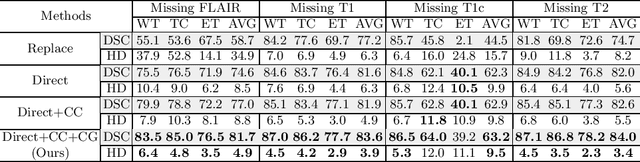
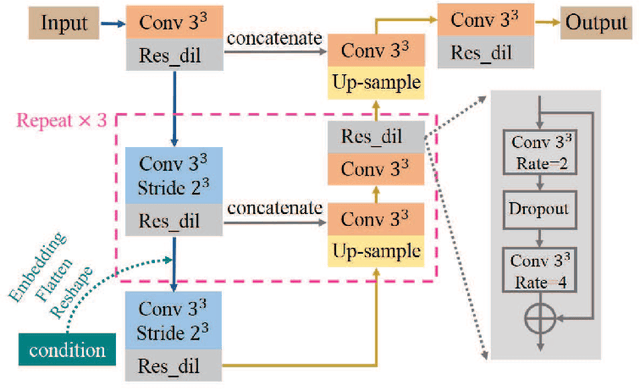
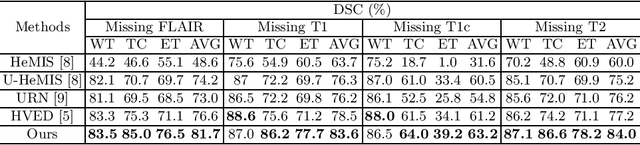
Brain tumor is one of the most high-risk cancers which causes the 5-year survival rate of only about 36%. Accurate diagnosis of brain tumor is critical for the treatment planning. However, complete data are not always available in clinical scenarios. In this paper, we propose a novel brain tumor segmentation network to deal with the missing data issue. To compensate for missing data, we propose to use a conditional generator to generate the missing modality under the condition of the available modalities. As the multi-modality has a strong correlation in tumor region, we design a correlation constraint network to leverage the multi-source information. On the one hand, the correlation constraint network can help the conditional generator to generate the missing modality which should keep the multi-source correlation with the available modalities. On the other hand, it can guide the segmentation network to learn the correlated feature representations to improve the segmentation performance. The proposed network consists of a conditional generator, a correlation constraint network and a segmentation network. We carried out extensive experiments on BraTS 2018 dataset to evaluate the proposed method.The experimental results demonstrate the importance of the proposed components and the superior performance of the proposed method com-pared with the state-of-the-art methods
Latent Correlation Representation Learning for Brain Tumor Segmentation with Missing MRI Modalities
Apr 20, 2021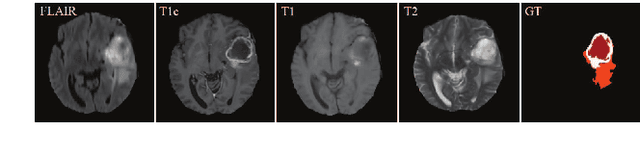
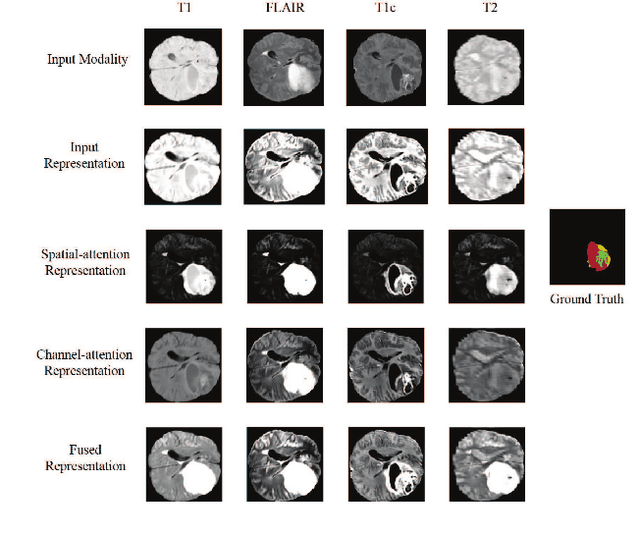
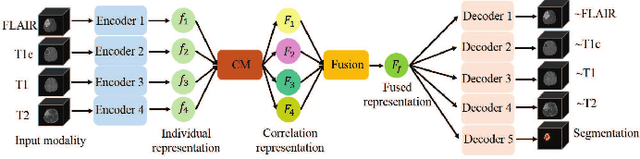
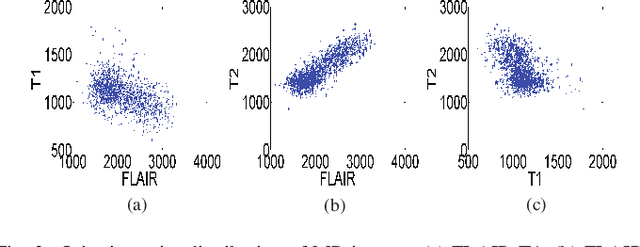
Magnetic Resonance Imaging (MRI) is a widely used imaging technique to assess brain tumor. Accurately segmenting brain tumor from MR images is the key to clinical diagnostics and treatment planning. In addition, multi-modal MR images can provide complementary information for accurate brain tumor segmentation. However, it's common to miss some imaging modalities in clinical practice. In this paper, we present a novel brain tumor segmentation algorithm with missing modalities. Since it exists a strong correlation between multi-modalities, a correlation model is proposed to specially represent the latent multi-source correlation. Thanks to the obtained correlation representation, the segmentation becomes more robust in the case of missing modality. First, the individual representation produced by each encoder is used to estimate the modality independent parameter. Then, the correlation model transforms all the individual representations to the latent multi-source correlation representations. Finally, the correlation representations across modalities are fused via attention mechanism into a shared representation to emphasize the most important features for segmentation. We evaluate our model on BraTS 2018 and BraTS 2019 dataset, it outperforms the current state-of-the-art methods and produces robust results when one or more modalities are missing.
* 12 pages, 10 figures, accepted by IEEE Transactions on Image Processing (8 April 2021). arXiv admin note: text overlap with arXiv:2003.08870, arXiv:2102.03111
3D Medical Multi-modal Segmentation Network Guided by Multi-source Correlation Constraint
Feb 05, 2021



In the field of multimodal segmentation, the correlation between different modalities can be considered for improving the segmentation results. In this paper, we propose a multi-modality segmentation network with a correlation constraint. Our network includes N model-independent encoding paths with N image sources, a correlation constraint block, a feature fusion block, and a decoding path. The model independent encoding path can capture modality-specific features from the N modalities. Since there exists a strong correlation between different modalities, we first propose a linear correlation block to learn the correlation between modalities, then a loss function is used to guide the network to learn the correlated features based on the linear correlation block. This block forces the network to learn the latent correlated features which are more relevant for segmentation. Considering that not all the features extracted from the encoders are useful for segmentation, we propose to use dual attention based fusion block to recalibrate the features along the modality and spatial paths, which can suppress less informative features and emphasize the useful ones. The fused feature representation is finally projected by the decoder to obtain the segmentation result. Our experiment results tested on BraTS-2018 dataset for brain tumor segmentation demonstrate the effectiveness of our proposed method.
A review: Deep learning for medical image segmentation using multi-modality fusion
Apr 22, 2020
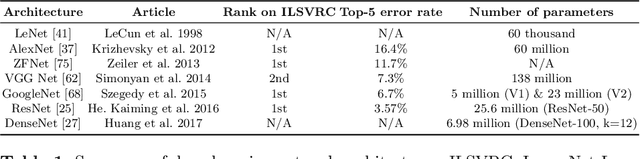
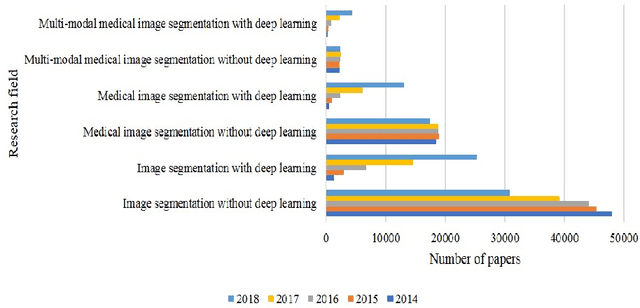
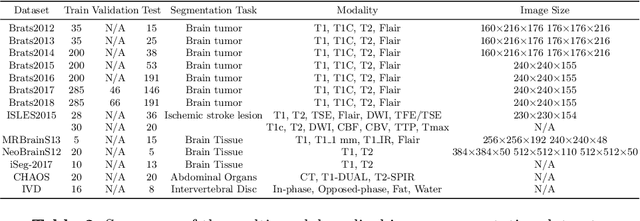
Multi-modality is widely used in medical imaging, because it can provide multiinformation about a target (tumor, organ or tissue). Segmentation using multimodality consists of fusing multi-information to improve the segmentation. Recently, deep learning-based approaches have presented the state-of-the-art performance in image classification, segmentation, object detection and tracking tasks. Due to their self-learning and generalization ability over large amounts of data, deep learning recently has also gained great interest in multi-modal medical image segmentation. In this paper, we give an overview of deep learning-based approaches for multi-modal medical image segmentation task. Firstly, we introduce the general principle of deep learning and multi-modal medical image segmentation. Secondly, we present different deep learning network architectures, then analyze their fusion strategies and compare their results. The earlier fusion is commonly used, since it's simple and it focuses on the subsequent segmentation network architecture. However, the later fusion gives more attention on fusion strategy to learn the complex relationship between different modalities. In general, compared to the earlier fusion, the later fusion can give more accurate result if the fusion method is effective enough. We also discuss some common problems in medical image segmentation. Finally, we summarize and provide some perspectives on the future research.
* 26 pages, 8 figures