 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Adversarial Robustness and Adversarial Training Strategies for Object Detection
Feb 18, 2026Object detection models are critical components of automated systems, such as autonomous vehicles and perception-based robots, but their sensitivity to adversarial attacks poses a serious security risk. Progress in defending these models lags behind classification, hindered by a lack of standardized evaluation. It is nearly impossible to thoroughly compare attack or defense methods, as existing work uses different datasets, inconsistent efficiency metrics, and varied measures of perturbation cost. This paper addresses this gap by investigating three key questions: (1) How can we create a fair benchmark to impartially compare attacks? (2) How well do modern attacks transfer across different architectures, especially from Convolutional Neural Networks to Vision Transformers? (3) What is the most effective adversarial training strategy for robust defense? To answer these, we first propose a unified benchmark framework focused on digital, non-patch-based attacks. This framework introduces specific metrics to disentangle localization and classification errors and evaluates attack cost using multiple perceptual metrics. Using this benchmark, we conduct extensive experiments on state-of-the-art attacks and a wide range of detectors. Our findings reveal two major conclusions: first, modern adversarial attacks against object detection models show a significant lack of transferability to transformer-based architectures. Second, we demonstrate that the most robust adversarial training strategy leverages a dataset composed of a mix of high-perturbation attacks with different objectives (e.g., spatial and semantic), which outperforms training on any single attack.
WarNav: An Autonomous Driving Benchmark for Segmentation of Navigable Zones in War Scenes
Nov 19, 2025We introduce WarNav, a novel real-world dataset constructed from images of the open-source DATTALION repository, specifically tailored to enable the development and benchmarking of semantic segmentation models for autonomous ground vehicle navigation in unstructured, conflict-affected environments. This dataset addresses a critical gap between conventional urban driving resources and the unique operational scenarios encountered by unmanned systems in hazardous and damaged war-zones. We detail the methodological challenges encountered, ranging from data heterogeneity to ethical considerations, providing guidance for future efforts that target extreme operational contexts. To establish performance references, we report baseline results on WarNav using several state-of-the-art semantic segmentation models trained on structured urban scenes. We further analyse the impact of training data environments and propose a first step towards effective navigability in challenging environments with the constraint of having no annotation of the targeted images. Our goal is to foster impactful research that enhances the robustness and safety of autonomous vehicles in high-risk scenarios while being frugal in annotated data.
Open-set object detection: towards unified problem formulation and benchmarking
Nov 08, 2024
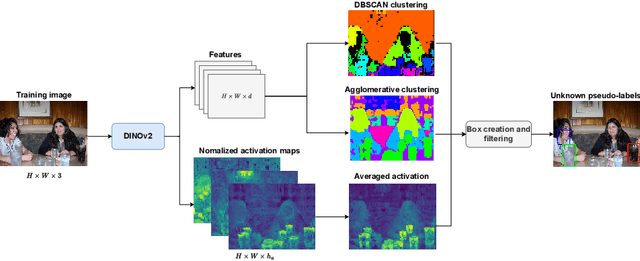


In real-world applications where confidence is key, like autonomous driving, the accurate detection and appropriate handling of classes differing from those used during training are crucial. Despite the proposal of various unknown object detection approaches, we have observed widespread inconsistencies among them regarding the datasets, metrics, and scenarios used, alongside a notable absence of a clear definition for unknown objects, which hampers meaningful evaluation. To counter these issues, we introduce two benchmarks: a unified VOC-COCO evaluation, and the new OpenImagesRoad benchmark which provides clear hierarchical object definition besides new evaluation metrics. Complementing the benchmark, we exploit recent self-supervised Vision Transformers performance, to improve pseudo-labeling-based OpenSet Object Detection (OSOD), through OW-DETR++. State-of-the-art methods are extensively evaluated on the proposed benchmarks. This study provides a clear problem definition, ensures consistent evaluations, and draws new conclusions about effectiveness of OSOD strategies.
Towards Few-Annotation Learning for Object Detection: Are Transformer-based Models More Efficient ?
Oct 30, 2023For specialized and dense downstream tasks such as object detection, labeling data requires expertise and can be very expensive, making few-shot and semi-supervised models much more attractive alternatives. While in the few-shot setup we observe that transformer-based object detectors perform better than convolution-based two-stage models for a similar amount of parameters, they are not as effective when used with recent approaches in the semi-supervised setting. In this paper, we propose a semi-supervised method tailored for the current state-of-the-art object detector Deformable DETR in the few-annotation learning setup using a student-teacher architecture, which avoids relying on a sensitive post-processing of the pseudo-labels generated by the teacher model. We evaluate our method on the semi-supervised object detection benchmarks COCO and Pascal VOC, and it outperforms previous methods, especially when annotations are scarce. We believe that our contributions open new possibilities to adapt similar object detection methods in this setup as well.
Proposal-Contrastive Pretraining for Object Detection from Fewer Data
Oct 25, 2023The use of pretrained deep neural networks represents an attractive way to achieve strong results with few data available. When specialized in dense problems such as object detection, learning local rather than global information in images has proven to be more efficient. However, for unsupervised pretraining, the popular contrastive learning requires a large batch size and, therefore, a lot of resources. To address this problem, we are interested in transformer-based object detectors that have recently gained traction in the community with good performance and with the particularity of generating many diverse object proposals. In this work, we present Proposal Selection Contrast (ProSeCo), a novel unsupervised overall pretraining approach that leverages this property. ProSeCo uses the large number of object proposals generated by the detector for contrastive learning, which allows the use of a smaller batch size, combined with object-level features to learn local information in the images. To improve the effectiveness of the contrastive loss, we introduce the object location information in the selection of positive examples to take into account multiple overlapping object proposals. When reusing pretrained backbone, we advocate for consistency in learning local information between the backbone and the detection head. We show that our method outperforms state of the art in unsupervised pretraining for object detection on standard and novel benchmarks in learning with fewer data.
Spatio-temporal predictive tasks for abnormal event detection in videos
Oct 27, 2022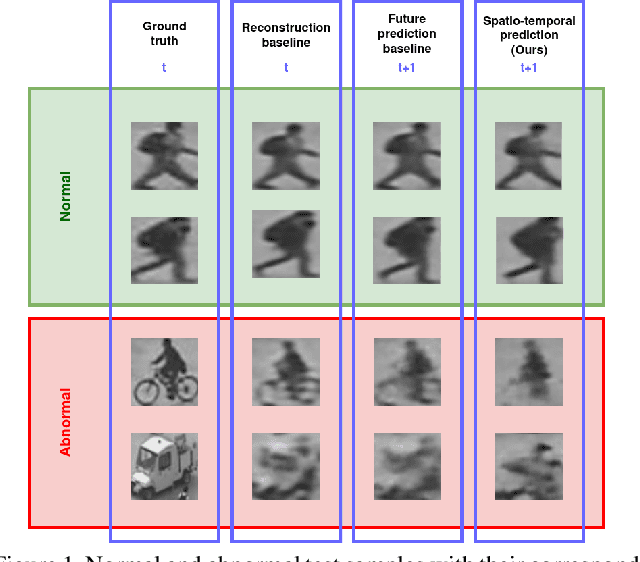
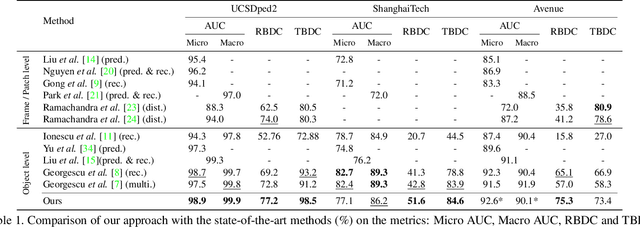


Abnormal event detection in videos is a challenging problem, partly due to the multiplicity of abnormal patterns and the lack of their corresponding annotations. In this paper, we propose new constrained pretext tasks to learn object level normality patterns. Our approach consists in learning a mapping between down-scaled visual queries and their corresponding normal appearance and motion characteristics at the original resolution. The proposed tasks are more challenging than reconstruction and future frame prediction tasks which are widely used in the literature, since our model learns to jointly predict spatial and temporal features rather than reconstructing them. We believe that more constrained pretext tasks induce a better learning of normality patterns. Experiments on several benchmark datasets demonstrate the effectiveness of our approach to localize and track anomalies as it outperforms or reaches the current state-of-the-art on spatio-temporal evaluation metrics.
Object-centric and memory-guided normality reconstruction for video anomaly detection
Mar 07, 2022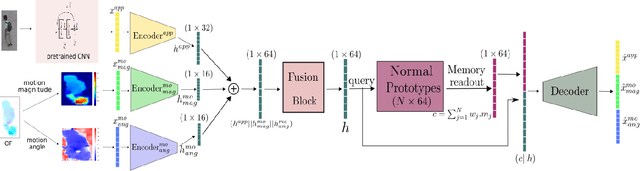
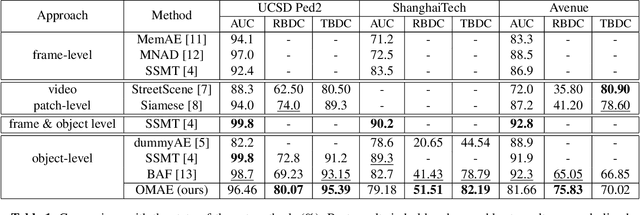
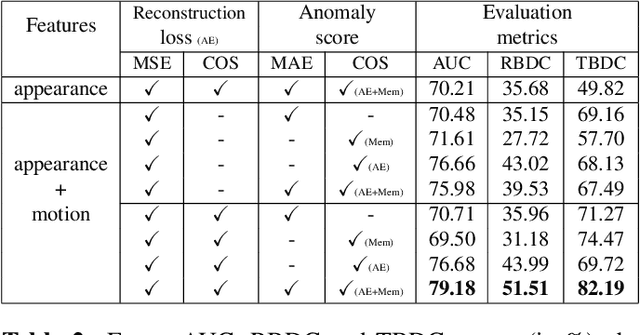
This paper addresses video anomaly detection problem for videosurveillance. Due to the inherent rarity and heterogeneity of abnormal events, the problem is viewed as a normality modeling strategy, in which our model learns object-centric normal patterns without seeing anomalous samples during training. The main contributions consist in coupling pretrained object-level action features prototypes with a cosine distance-based anomaly estimation function, therefore extending previous methods by introducing additional constraints to the mainstream reconstruction-based strategy. Our framework leverages both appearance and motion information to learn object-level behavior and captures prototypical patterns within a memory module. Experiments on several well-known datasets demonstrate the effectiveness of our method as it outperforms current state-of-the-art on most relevant spatio-temporal evaluation metrics.
End-to-end Person Search Sequentially Trained on Aggregated Dataset
Jan 24, 2022

In video surveillance applications, person search is a challenging task consisting in detecting people and extracting features from their silhouette for re-identification (re-ID) purpose. We propose a new end-to-end model that jointly computes detection and feature extraction steps through a single deep Convolutional Neural Network architecture. Sharing feature maps between the two tasks for jointly describing people commonalities and specificities allows faster runtime, which is valuable in real-world applications. In addition to reaching state-of-the-art accuracy, this multi-task model can be sequentially trained task-by-task, which results in a broader acceptance of input dataset types. Indeed, we show that aggregating more pedestrian detection datasets without costly identity annotations makes the shared feature maps more generic, and improves re-ID precision. Moreover, these boosted shared feature maps result in re-ID features more robust to a cross-dataset scenario.
* 5 pages
Describe me if you can! Characterized Instance-level Human Parsing
Jan 24, 2022

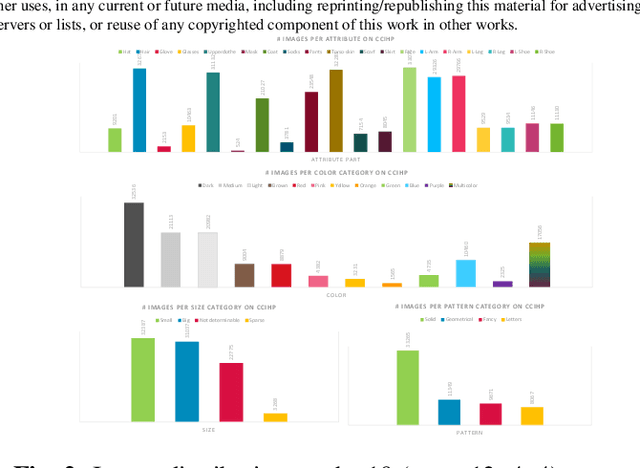
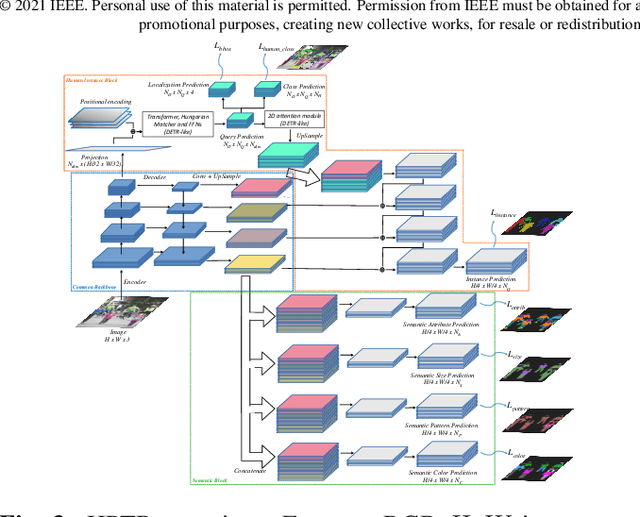
Several computer vision applications such as person search or online fashion rely on human description. The use of instance-level human parsing (HP) is therefore relevant since it localizes semantic attributes and body parts within a person. But how to characterize these attributes? To our knowledge, only some single-HP datasets describe attributes with some color, size and/or pattern characteristics. There is a lack of dataset for multi-HP in the wild with such characteristics. In this article, we propose the dataset CCIHP based on the multi-HP dataset CIHP, with 20 new labels covering these 3 kinds of characteristics. In addition, we propose HPTR, a new bottom-up multi-task method based on transformers as a fast and scalable baseline. It is the fastest method of multi-HP state of the art while having precision comparable to the most precise bottom-up method. We hope this will encourage research for fast and accurate methods of precise human descriptions.
* 5 pages
Detecting Human-to-Human-or-Object (H2O) Interactions with DIABOLO
Jan 07, 2022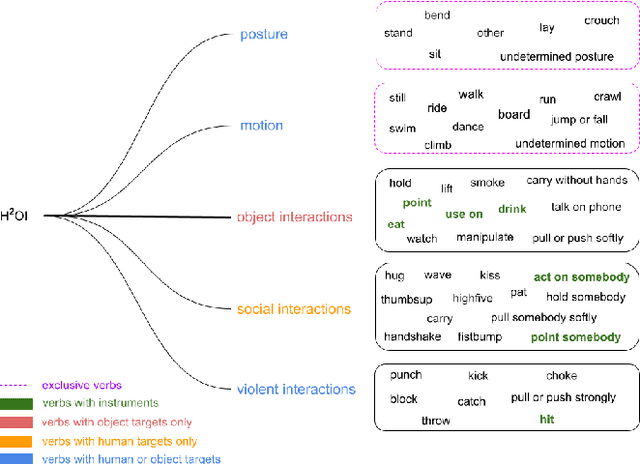

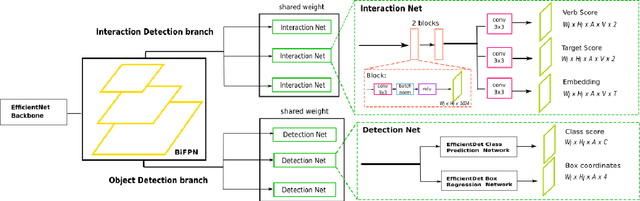
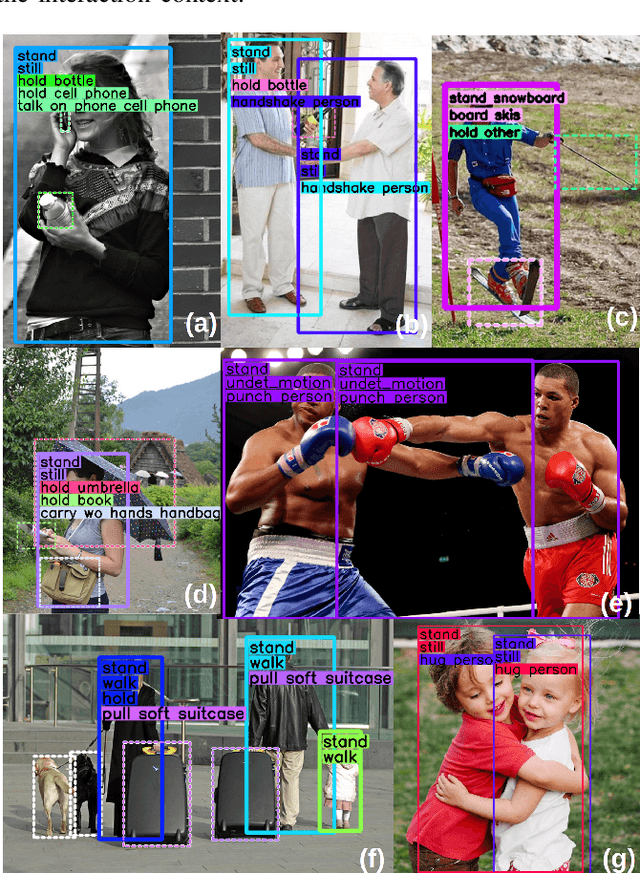
Detecting human interactions is crucial for human behavior analysis. Many methods have been proposed to deal with Human-to-Object Interaction (HOI) detection, i.e., detecting in an image which person and object interact together and classifying the type of interaction. However, Human-to-Human Interactions, such as social and violent interactions, are generally not considered in available HOI training datasets. As we think these types of interactions cannot be ignored and decorrelated from HOI when analyzing human behavior, we propose a new interaction dataset to deal with both types of human interactions: Human-to-Human-or-Object (H2O). In addition, we introduce a novel taxonomy of verbs, intended to be closer to a description of human body attitude in relation to the surrounding targets of interaction, and more independent of the environment. Unlike some existing datasets, we strive to avoid defining synonymous verbs when their use highly depends on the target type or requires a high level of semantic interpretation. As H2O dataset includes V-COCO images annotated with this new taxonomy, images obviously contain more interactions. This can be an issue for HOI detection methods whose complexity depends on the number of people, targets or interactions. Thus, we propose DIABOLO (Detecting InterActions By Only Looking Once), an efficient subject-centric single-shot method to detect all interactions in one forward pass, with constant inference time independent of image content. In addition, this multi-task network simultaneously detects all people and objects. We show how sharing a network for these tasks does not only save computation resource but also improves performance collaboratively. Finally, DIABOLO is a strong baseline for the new proposed challenge of H2O Interaction detection, as it outperforms all state-of-the-art methods when trained and evaluated on HOI dataset V-COCO.