 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-set object detection: towards unified problem formulation and benchmarking
Nov 08, 2024
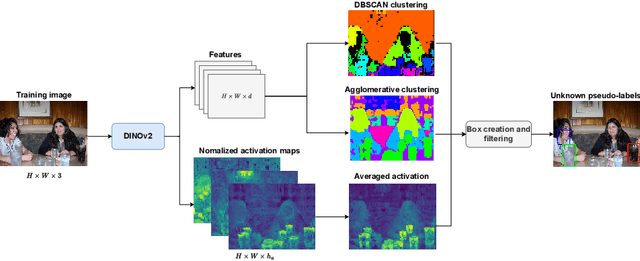


In real-world applications where confidence is key, like autonomous driving, the accurate detection and appropriate handling of classes differing from those used during training are crucial. Despite the proposal of various unknown object detection approaches, we have observed widespread inconsistencies among them regarding the datasets, metrics, and scenarios used, alongside a notable absence of a clear definition for unknown objects, which hampers meaningful evaluation. To counter these issues, we introduce two benchmarks: a unified VOC-COCO evaluation, and the new OpenImagesRoad benchmark which provides clear hierarchical object definition besides new evaluation metrics. Complementing the benchmark, we exploit recent self-supervised Vision Transformers performance, to improve pseudo-labeling-based OpenSet Object Detection (OSOD), through OW-DETR++. State-of-the-art methods are extensively evaluated on the proposed benchmarks. This study provides a clear problem definition, ensures consistent evaluations, and draws new conclusions about effectiveness of OSOD strategies.
GaussianBeV: 3D Gaussian Representation meets Perception Models for BeV Segmentation
Jul 19, 2024The Bird's-eye View (BeV) representation is widely used for 3D perception from multi-view camera images. It allows to merge features from different cameras into a common space, providing a unified representation of the 3D scene. The key component is the view transformer, which transforms image views into the BeV. However, actual view transformer methods based on geometry or cross-attention do not provide a sufficiently detailed representation of the scene, as they use a sub-sampling of the 3D space that is non-optimal for modeling the fine structures of the environment. In this paper, we propose GaussianBeV, a novel method for transforming image features to BeV by finely representing the scene using a set of 3D gaussians located and oriented in 3D space. This representation is then splattered to produce the BeV feature map by adapting recent advances in 3D representation rendering based on gaussian splatting. GaussianBeV is the first approach to use this 3D gaussian modeling and 3D scene rendering process online, i.e. without optimizing it on a specific scene and directly integrated into a single stage model for BeV scene understanding. Experiments show that the proposed representation is highly effective and place GaussianBeV as the new state-of-the-art on the BeV semantic segmentation task on the nuScenes dataset.