 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Few-Annotation Learning for Object Detection: Are Transformer-based Models More Efficient ?
Oct 30, 2023For specialized and dense downstream tasks such as object detection, labeling data requires expertise and can be very expensive, making few-shot and semi-supervised models much more attractive alternatives. While in the few-shot setup we observe that transformer-based object detectors perform better than convolution-based two-stage models for a similar amount of parameters, they are not as effective when used with recent approaches in the semi-supervised setting. In this paper, we propose a semi-supervised method tailored for the current state-of-the-art object detector Deformable DETR in the few-annotation learning setup using a student-teacher architecture, which avoids relying on a sensitive post-processing of the pseudo-labels generated by the teacher model. We evaluate our method on the semi-supervised object detection benchmarks COCO and Pascal VOC, and it outperforms previous methods, especially when annotations are scarce. We believe that our contributions open new possibilities to adapt similar object detection methods in this setup as well.
Proposal-Contrastive Pretraining for Object Detection from Fewer Data
Oct 25, 2023The use of pretrained deep neural networks represents an attractive way to achieve strong results with few data available. When specialized in dense problems such as object detection, learning local rather than global information in images has proven to be more efficient. However, for unsupervised pretraining, the popular contrastive learning requires a large batch size and, therefore, a lot of resources. To address this problem, we are interested in transformer-based object detectors that have recently gained traction in the community with good performance and with the particularity of generating many diverse object proposals. In this work, we present Proposal Selection Contrast (ProSeCo), a novel unsupervised overall pretraining approach that leverages this property. ProSeCo uses the large number of object proposals generated by the detector for contrastive learning, which allows the use of a smaller batch size, combined with object-level features to learn local information in the images. To improve the effectiveness of the contrastive loss, we introduce the object location information in the selection of positive examples to take into account multiple overlapping object proposals. When reusing pretrained backbone, we advocate for consistency in learning local information between the backbone and the detection head. We show that our method outperforms state of the art in unsupervised pretraining for object detection on standard and novel benchmarks in learning with fewer data.
Spatio-temporal predictive tasks for abnormal event detection in videos
Oct 27, 2022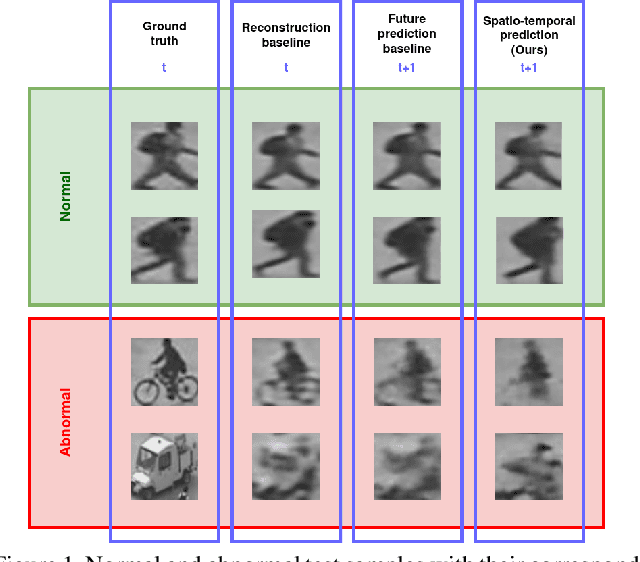
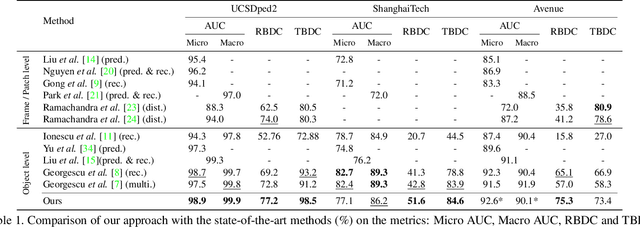


Abnormal event detection in videos is a challenging problem, partly due to the multiplicity of abnormal patterns and the lack of their corresponding annotations. In this paper, we propose new constrained pretext tasks to learn object level normality patterns. Our approach consists in learning a mapping between down-scaled visual queries and their corresponding normal appearance and motion characteristics at the original resolution. The proposed tasks are more challenging than reconstruction and future frame prediction tasks which are widely used in the literature, since our model learns to jointly predict spatial and temporal features rather than reconstructing them. We believe that more constrained pretext tasks induce a better learning of normality patterns. Experiments on several benchmark datasets demonstrate the effectiveness of our approach to localize and track anomalies as it outperforms or reaches the current state-of-the-art on spatio-temporal evaluation metrics.
Object-centric and memory-guided normality reconstruction for video anomaly detection
Mar 07, 2022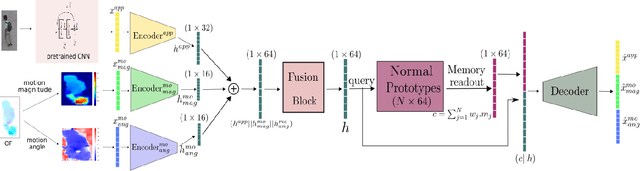
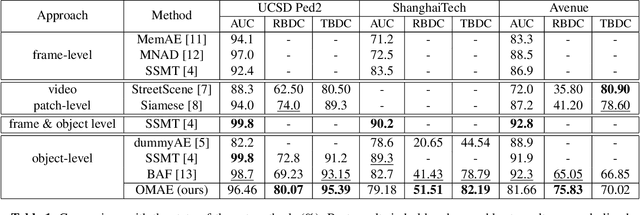
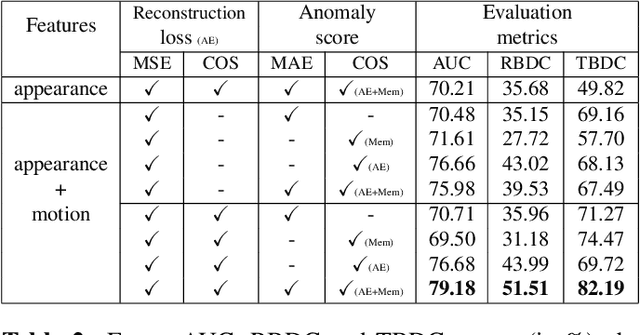
This paper addresses video anomaly detection problem for videosurveillance. Due to the inherent rarity and heterogeneity of abnormal events, the problem is viewed as a normality modeling strategy, in which our model learns object-centric normal patterns without seeing anomalous samples during training. The main contributions consist in coupling pretrained object-level action features prototypes with a cosine distance-based anomaly estimation function, therefore extending previous methods by introducing additional constraints to the mainstream reconstruction-based strategy. Our framework leverages both appearance and motion information to learn object-level behavior and captures prototypical patterns within a memory module. Experiments on several well-known datasets demonstrate the effectiveness of our method as it outperforms current state-of-the-art on most relevant spatio-temporal evaluation metrics.
A formal approach to good practices in Pseudo-Labeling for Unsupervised Domain Adaptive Re-Identification
Dec 28, 2021

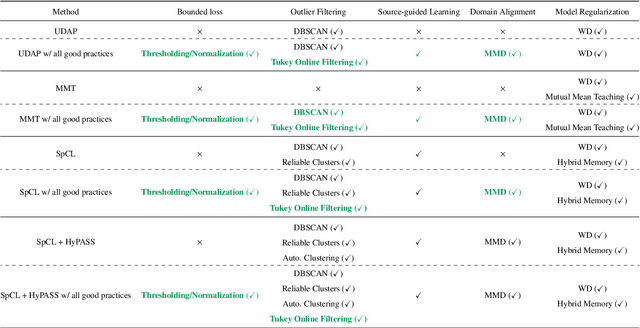
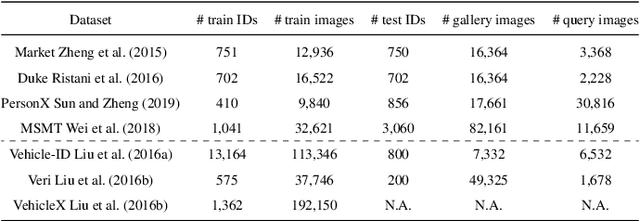
The use of pseudo-labels prevails in order to tackle Unsupervised Domain Adaptive (UDA) Re-Identification (re-ID) with the best performance. Indeed, this family of approaches has given rise to several UDA re-ID specific frameworks, which are effective. In these works, research directions to improve Pseudo-Labeling UDA re-ID performance are varied and mostly based on intuition and experiments: refining pseudo-labels, reducing the impact of errors in pseudo-labels... It can be hard to deduce from them general good practices, which can be implemented in any Pseudo-Labeling method, to consistently improve its performance. To address this key question, a new theoretical view on Pseudo-Labeling UDA re-ID is proposed. The contributions are threefold: (i) A novel theoretical framework for Pseudo-Labeling UDA re-ID, formalized through a new general learning upper-bound on the UDA re-ID performance. (ii) General good practices for Pseudo-Labeling, directly deduced from the interpretation of the proposed theoretical framework, in order to improve the target re-ID performance. (iii) Extensive experiments on challenging person and vehicle cross-dataset re-ID tasks, showing consistent performance improvements for various state-of-the-art methods and various proposed implementations of good practices.
Improving Unsupervised Domain Adaptive Re-Identification via Source-Guided Selection of Pseudo-Labeling Hyperparameters
Nov 04, 2021
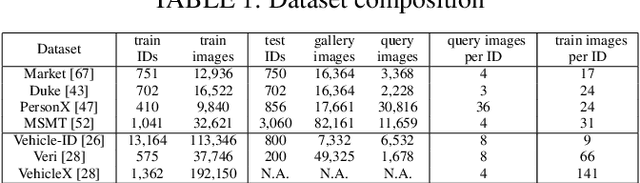
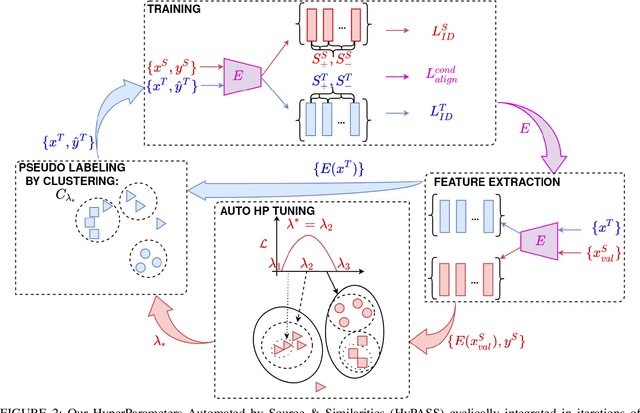

Unsupervised Domain Adaptation (UDA) for re-identification (re-ID) is a challenging task: to avoid a costly annotation of additional data, it aims at transferring knowledge from a domain with annotated data to a domain of interest with only unlabeled data. Pseudo-labeling approaches have proven to be effective for UDA re-ID. However, the effectiveness of these approaches heavily depends on the choice of some hyperparameters (HP) that affect the generation of pseudo-labels by clustering. The lack of annotation in the domain of interest makes this choice non-trivial. Current approaches simply reuse the same empirical value for all adaptation tasks and regardless of the target data representation that changes through pseudo-labeling training phases. As this simplistic choice may limit their performance, we aim at addressing this issue. We propose new theoretical grounds on HP selection for clustering UDA re-ID as well as method of automatic and cyclic HP tuning for pseudo-labeling UDA clustering: HyPASS. HyPASS consists in incorporating two modules in pseudo-labeling methods: (i) HP selection based on a labeled source validation set and (ii) conditional domain alignment of feature discriminativeness to improve HP selection based on source samples. Experiments on commonly used person re-ID and vehicle re-ID datasets show that our proposed HyPASS consistently improves the best state-of-the-art methods in re-ID compared to the commonly used empirical HP setting.
Optimal Transport as a Defense Against Adversarial Attacks
Feb 05, 2021

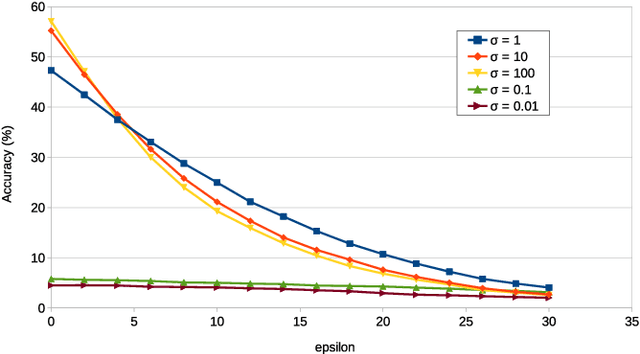
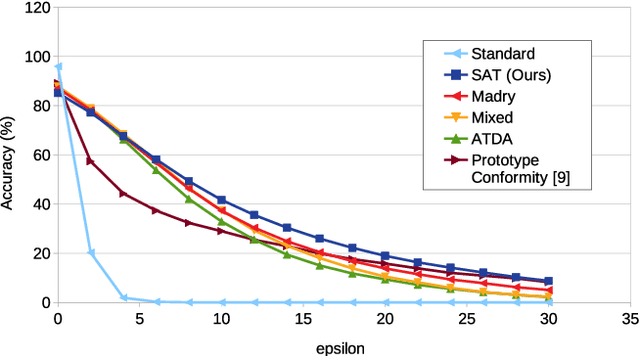
Deep learning classifiers are now known to have flaws in the representations of their class. Adversarial attacks can find a human-imperceptible perturbation for a given image that will mislead a trained model. The most effective methods to defend against such attacks trains on generated adversarial examples to learn their distribution. Previous work aimed to align original and adversarial image representations in the same way as domain adaptation to improve robustness. Yet, they partially align the representations using approaches that do not reflect the geometry of space and distribution. In addition, it is difficult to accurately compare robustness between defended models. Until now, they have been evaluated using a fixed perturbation size. However, defended models may react differently to variations of this perturbation size. In this paper, the analogy of domain adaptation is taken a step further by exploiting optimal transport theory. We propose to use a loss between distributions that faithfully reflect the ground distance. This leads to SAT (Sinkhorn Adversarial Training), a more robust defense against adversarial attacks. Then, we propose to quantify more precisely the robustness of a model to adversarial attacks over a wide range of perturbation sizes using a different metric, the Area Under the Accuracy Curve (AUAC). We perform extensive experiments on both CIFAR-10 and CIFAR-100 datasets and show that our defense is globally more robust than the state-of-the-art.
Putting Theory to Work: From Learning Bounds to Meta-Learning Algorithms
Oct 05, 2020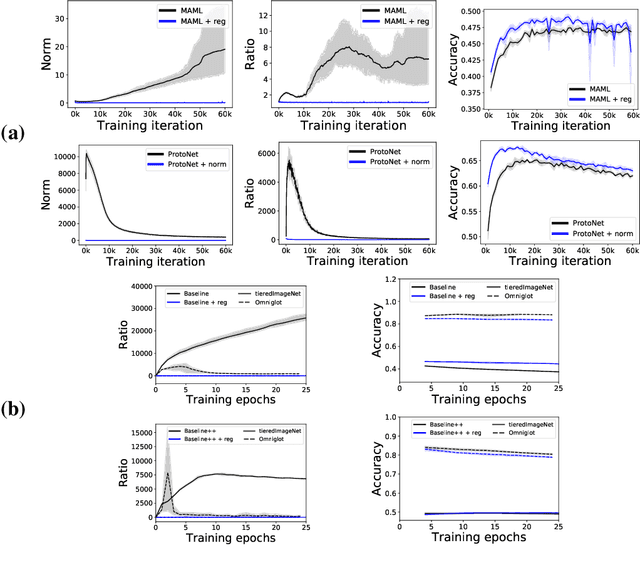
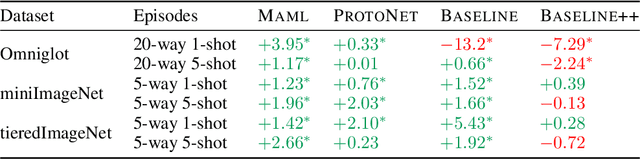

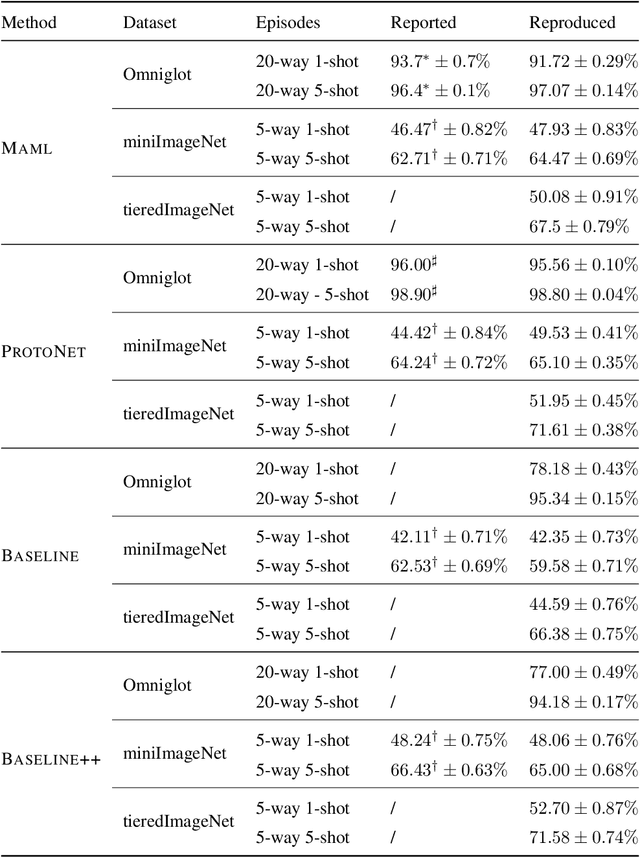
Most of existing deep learning models rely on excessive amounts of labeled training data in order to achieve state-of-the-art results, even though these data can be hard or costly to get in practice. One attractive alternative is to learn with little supervision, commonly referred to as few-shot learning (FSL), and, in particular, meta-learning that learns to learn with few data from related tasks. Despite the practical success of meta-learning, many of its algorithmic solutions proposed in the literature are based on sound intuitions, but lack a solid theoretical analysis of the expected performance on the test task. In this paper, we review the recent advances in meta-learning theory and show how they can be used in practice both to better understand the behavior of popular meta-learning algorithms and to improve their generalization capacity. This latter is achieved by integrating the theoretical assumptions ensuring efficient meta-learning in the form of regularization terms into several popular meta-learning algorithms for which we provide a large study of their behavior on classic few-shot classification benchmarks. To the best of our knowledge, this is the first contribution that puts the most recent learning bounds of meta-learning theory into practice for the popular task of few-shot classification.