 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Transport as a Defense Against Adversarial Attacks
Paper and Code
Feb 05, 2021

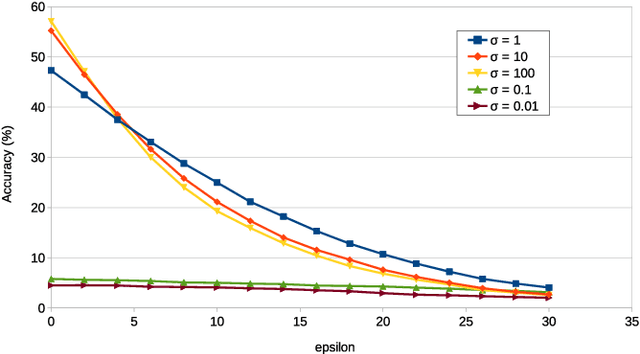
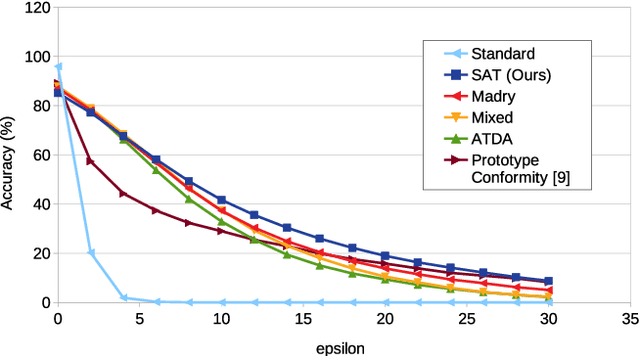
Deep learning classifiers are now known to have flaws in the representations of their class. Adversarial attacks can find a human-imperceptible perturbation for a given image that will mislead a trained model. The most effective methods to defend against such attacks trains on generated adversarial examples to learn their distribution. Previous work aimed to align original and adversarial image representations in the same way as domain adaptation to improve robustness. Yet, they partially align the representations using approaches that do not reflect the geometry of space and distribution. In addition, it is difficult to accurately compare robustness between defended models. Until now, they have been evaluated using a fixed perturbation size. However, defended models may react differently to variations of this perturbation size. In this paper, the analogy of domain adaptation is taken a step further by exploiting optimal transport theory. We propose to use a loss between distributions that faithfully reflect the ground distance. This leads to SAT (Sinkhorn Adversarial Training), a more robust defense against adversarial attacks. Then, we propose to quantify more precisely the robustness of a model to adversarial attacks over a wide range of perturbation sizes using a different metric, the Area Under the Accuracy Curve (AUAC). We perform extensive experiments on both CIFAR-10 and CIFAR-100 datasets and show that our defense is globally more robust than the state-of-the-art.