 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePutting Theory to Work: From Learning Bounds to Meta-Learning Algorithms
Paper and Code
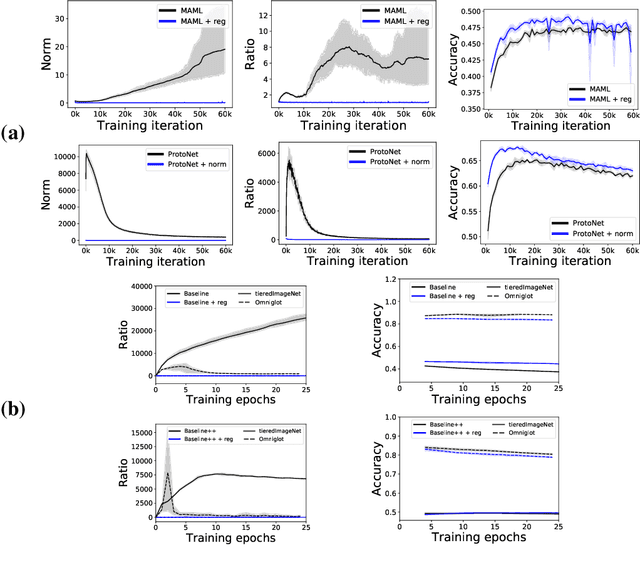
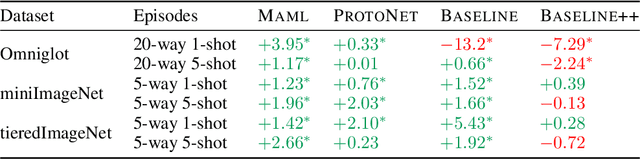

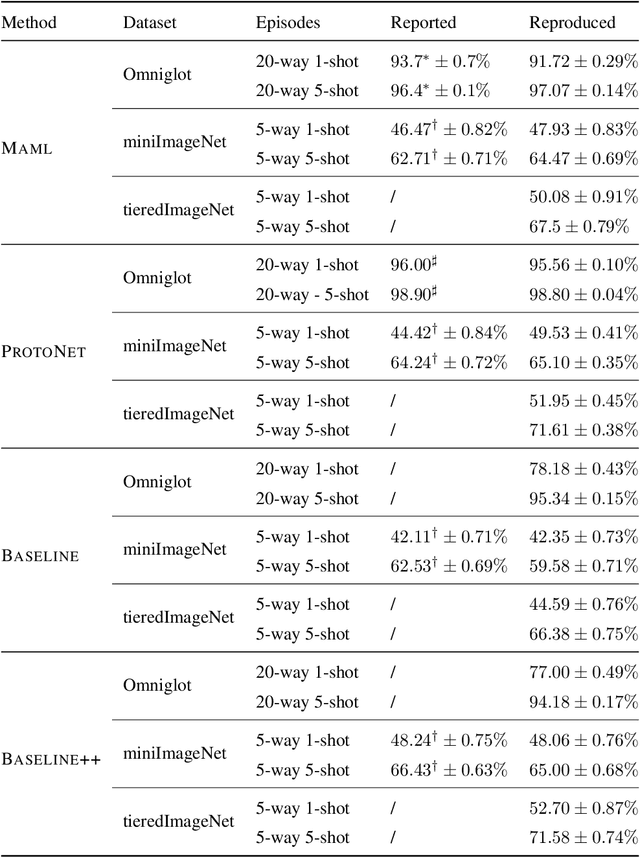
Most of existing deep learning models rely on excessive amounts of labeled training data in order to achieve state-of-the-art results, even though these data can be hard or costly to get in practice. One attractive alternative is to learn with little supervision, commonly referred to as few-shot learning (FSL), and, in particular, meta-learning that learns to learn with few data from related tasks. Despite the practical success of meta-learning, many of its algorithmic solutions proposed in the literature are based on sound intuitions, but lack a solid theoretical analysis of the expected performance on the test task. In this paper, we review the recent advances in meta-learning theory and show how they can be used in practice both to better understand the behavior of popular meta-learning algorithms and to improve their generalization capacity. This latter is achieved by integrating the theoretical assumptions ensuring efficient meta-learning in the form of regularization terms into several popular meta-learning algorithms for which we provide a large study of their behavior on classic few-shot classification benchmarks. To the best of our knowledge, this is the first contribution that puts the most recent learning bounds of meta-learning theory into practice for the popular task of few-shot classification.