 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
COMEDIAN: Self-Supervised Learning and Knowledge Distillation for Action Spotting using Transformers
Sep 03, 2023



We present COMEDIAN, a novel pipeline to initialize spatio-temporal transformers for action spotting, which involves self-supervised learning and knowledge distillation. Action spotting is a timestamp-level temporal action detection task. Our pipeline consists of three steps, with two initialization stages. First, we perform self-supervised initialization of a spatial transformer using short videos as input. Additionally, we initialize a temporal transformer that enhances the spatial transformer's outputs with global context through knowledge distillation from a pre-computed feature bank aligned with each short video segment. In the final step, we fine-tune the transformers to the action spotting task. The experiments, conducted on the SoccerNet-v2 dataset, demonstrate state-of-the-art performance and validate the effectiveness of COMEDIAN's pretraining paradigm. Our results highlight several advantages of our pretraining pipeline, including improved performance and faster convergence compared to non-pretrained models.
Similarity Contrastive Estimation for Image and Video Soft Contrastive Self-Supervised Learning
Dec 21, 2022Contrastive representation learning has proven to be an effective self-supervised learning method for images and videos. Most successful approaches are based on Noise Contrastive Estimation (NCE) and use different views of an instance as positives that should be contrasted with other instances, called negatives, that are considered as noise. However, several instances in a dataset are drawn from the same distribution and share underlying semantic information. A good data representation should contain relations between the instances, or semantic similarity and dissimilarity, that contrastive learning harms by considering all negatives as noise. To circumvent this issue, we propose a novel formulation of contrastive learning using semantic similarity between instances called Similarity Contrastive Estimation (SCE). Our training objective is a soft contrastive one that brings the positives closer and estimates a continuous distribution to push or pull negative instances based on their learned similarities. We validate empirically our approach on both image and video representation learning. We show that SCE performs competitively with the state of the art on the ImageNet linear evaluation protocol for fewer pretraining epochs and that it generalizes to several downstream image tasks. We also show that SCE reaches state-of-the-art results for pretraining video representation and that the learned representation can generalize to video downstream tasks.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
KaliCalib: A Framework for Basketball Court Registration
Sep 16, 2022
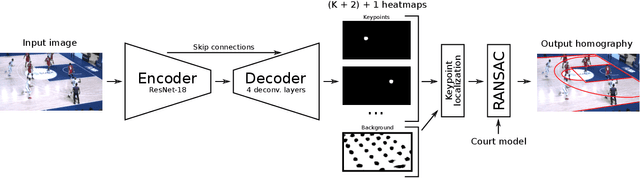
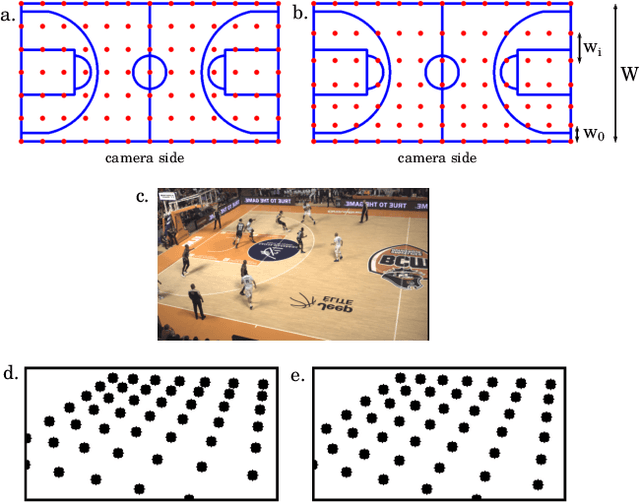

Tracking the players and the ball in team sports is key to analyse the performance or to enhance the game watching experience with augmented reality. When the only sources for this data are broadcast videos, sports-field registration systems are required to estimate the homography and re-project the ball or the players from the image space to the field space. This paper describes a new basketball court registration framework in the context of the MMSports 2022 camera calibration challenge. The method is based on the estimation by an encoder-decoder network of the positions of keypoints sampled with perspective-aware constraints. The regression of the basket positions and heavy data augmentation techniques make the model robust to different arenas. Ablation studies show the positive effects of our contributions on the challenge test set. Our method divides the mean squared error by 4.7 compared to the challenge baseline.
Efficient tracking of team sport players with few game-specific annotations
Apr 08, 2022
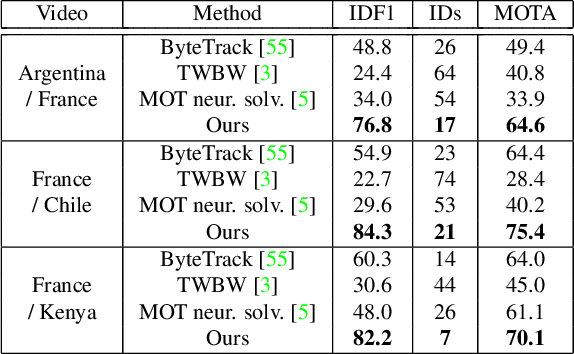
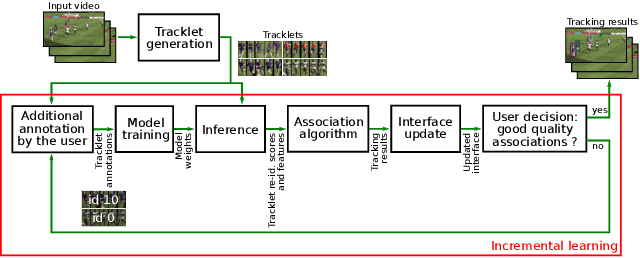
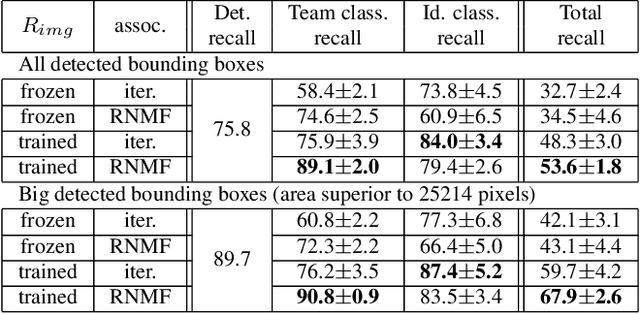
One of the requirements for team sports analysis is to track and recognize players. Many tracking and reidentification methods have been proposed in the context of video surveillance. They show very convincing results when tested on public datasets such as the MOT challenge. However, the performance of these methods are not as satisfactory when applied to player tracking. Indeed, in addition to moving very quickly and often being occluded, the players wear the same jersey, which makes the task of reidentification very complex. Some recent tracking methods have been developed more specifically for the team sport context. Due to the lack of public data, these methods use private datasets that make impossible a comparison with them. In this paper, we propose a new generic method to track team sport players during a full game thanks to few human annotations collected via a semi-interactive system. Non-ambiguous tracklets and their appearance features are automatically generated with a detection and a reidentification network both pre-trained on public datasets. Then an incremental learning mechanism trains a Transformer to classify identities using few game-specific human annotations. Finally, tracklets are linked by an association algorithm. We demonstrate the efficiency of our approach on a challenging rugby sevens dataset. To overcome the lack of public sports tracking dataset, we publicly release this dataset at https://kalisteo.cea.fr/index.php/free-resources/. We also show that our method is able to track rugby sevens players during a full match, if they are observable at a minimal resolution, with the annotation of only 6 few seconds length tracklets per player.
Detecting Human-to-Human-or-Object (H2O) Interactions with DIABOLO
Jan 07, 2022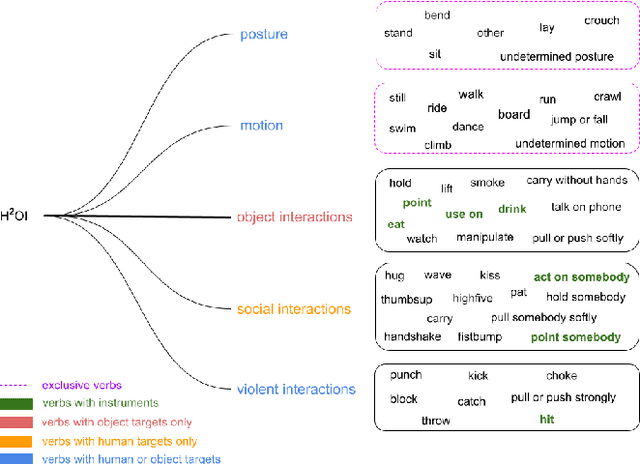

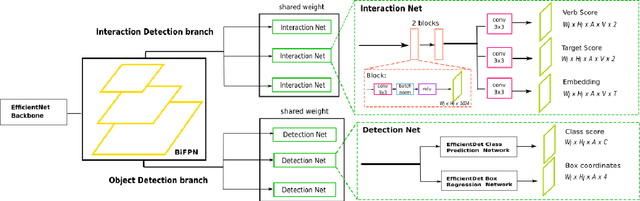
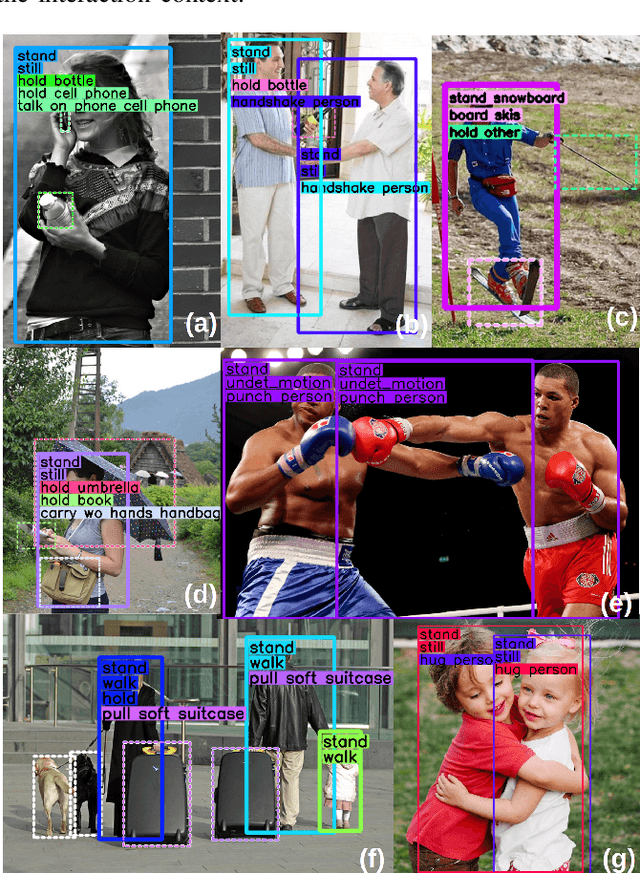
Detecting human interactions is crucial for human behavior analysis. Many methods have been proposed to deal with Human-to-Object Interaction (HOI) detection, i.e., detecting in an image which person and object interact together and classifying the type of interaction. However, Human-to-Human Interactions, such as social and violent interactions, are generally not considered in available HOI training datasets. As we think these types of interactions cannot be ignored and decorrelated from HOI when analyzing human behavior, we propose a new interaction dataset to deal with both types of human interactions: Human-to-Human-or-Object (H2O). In addition, we introduce a novel taxonomy of verbs, intended to be closer to a description of human body attitude in relation to the surrounding targets of interaction, and more independent of the environment. Unlike some existing datasets, we strive to avoid defining synonymous verbs when their use highly depends on the target type or requires a high level of semantic interpretation. As H2O dataset includes V-COCO images annotated with this new taxonomy, images obviously contain more interactions. This can be an issue for HOI detection methods whose complexity depends on the number of people, targets or interactions. Thus, we propose DIABOLO (Detecting InterActions By Only Looking Once), an efficient subject-centric single-shot method to detect all interactions in one forward pass, with constant inference time independent of image content. In addition, this multi-task network simultaneously detects all people and objects. We show how sharing a network for these tasks does not only save computation resource but also improves performance collaboratively. Finally, DIABOLO is a strong baseline for the new proposed challenge of H2O Interaction detection, as it outperforms all state-of-the-art methods when trained and evaluated on HOI dataset V-COCO.
Similarity Contrastive Estimation for Self-Supervised Soft Contrastive Learning
Nov 29, 2021



Contrastive representation learning has proven to be an effective self-supervised learning method. Most successful approaches are based on the Noise Contrastive Estimation (NCE) paradigm and consider different views of an instance as positives and other instances as noise that positives should be contrasted with. However, all instances in a dataset are drawn from the same distribution and share underlying semantic information that should not be considered as noise. We argue that a good data representation contains the relations, or semantic similarity, between the instances. Contrastive learning implicitly learns relations but considers the negatives as noise which is harmful to the quality of the learned relations and therefore the quality of the representation. To circumvent this issue we propose a novel formulation of contrastive learning using semantic similarity between instances called Similarity Contrastive Estimation (SCE). Our training objective can be considered as soft contrastive learning. Instead of hard classifying positives and negatives, we propose a continuous distribution to push or pull instances based on their semantic similarities. The target similarity distribution is computed from weak augmented instances and sharpened to eliminate irrelevant relations. Each weak augmented instance is paired with a strong augmented instance that contrasts its positive while maintaining the target similarity distribution. Experimental results show that our proposed SCE outperforms its baselines MoCov2 and ReSSL on various datasets and is competitive with state-of-the-art algorithms on the ImageNet linear evaluation protocol.
Classifying All Interacting Pairs in a Single Shot
Jan 13, 2020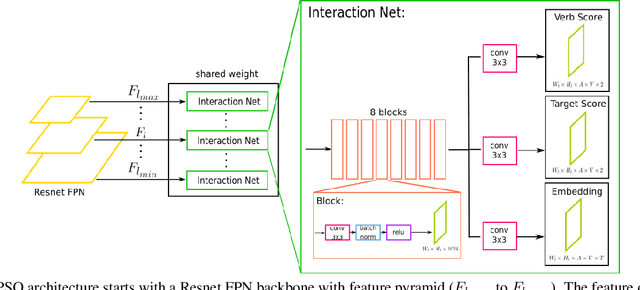


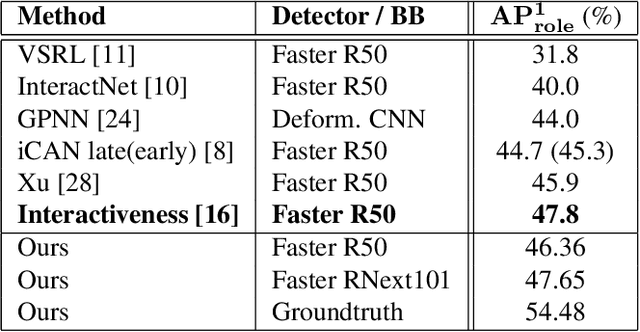
In this paper, we introduce a novel human interaction detection approach, based on CALIPSO (Classifying ALl Interacting Pairs in a Single shOt), a classifier of human-object interactions. This new single-shot interaction classifier estimates interactions simultaneously for all human-object pairs, regardless of their number and class. State-of-the-art approaches adopt a multi-shot strategy based on a pairwise estimate of interactions for a set of human-object candidate pairs, which leads to a complexity depending, at least, on the number of interactions or, at most, on the number of candidate pairs. In contrast, the proposed method estimates the interactions on the whole image. Indeed, it simultaneously estimates all interactions between all human subjects and object targets by performing a single forward pass throughout the image. Consequently, it leads to a constant complexity and computation time independent of the number of subjects, objects or interactions in the image. In detail, interaction classification is achieved on a dense grid of anchors thanks to a joint multi-task network that learns three complementary tasks simultaneously: (i) prediction of the types of interaction, (ii) estimation of the presence of a target and (iii) learning of an embedding which maps interacting subject and target to a same representation, by using a metric learning strategy. In addition, we introduce an object-centric passive-voice verb estimation which significantly improves results. Evaluations on the two well-known Human-Object Interaction image datasets, V-COCO and HICO-DET, demonstrate the competitiveness of the proposed method (2nd place) compared to the state-of-the-art while having constant computation time regardless of the number of objects and interactions in the image.