 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVAT: Multi-View Aware Teacher for Weakly Supervised 3D Object Detection
Sep 09, 2025Annotating 3D data remains a costly bottleneck for 3D object detection, motivating the development of weakly supervised annotation methods that rely on more accessible 2D box annotations. However, relying solely on 2D boxes introduces projection ambiguities since a single 2D box can correspond to multiple valid 3D poses. Furthermore, partial object visibility under a single viewpoint setting makes accurate 3D box estimation difficult. We propose MVAT, a novel framework that leverages temporal multi-view present in sequential data to address these challenges. Our approach aggregates object-centric point clouds across time to build 3D object representations as dense and complete as possible. A Teacher-Student distillation paradigm is employed: The Teacher network learns from single viewpoints but targets are derived from temporally aggregated static objects. Then the Teacher generates high quality pseudo-labels that the Student learns to predict from a single viewpoint for both static and moving objects. The whole framework incorporates a multi-view 2D projection loss to enforce consistency between predicted 3D boxes and all available 2D annotations. Experiments on the nuScenes and Waymo Open datasets demonstrate that MVAT achieves state-of-the-art performance for weakly supervised 3D object detection, significantly narrowing the gap with fully supervised methods without requiring any 3D box annotations. % \footnote{Code available upon acceptance} Our code is available in our public repository (\href{https://github.com/CEA-LIST/MVAT}{code}).
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
KaliCalib: A Framework for Basketball Court Registration
Sep 16, 2022
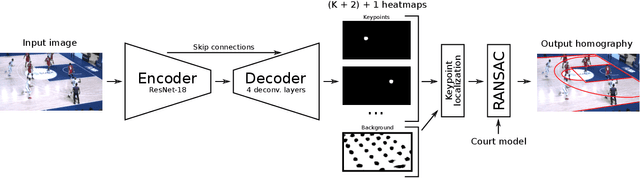
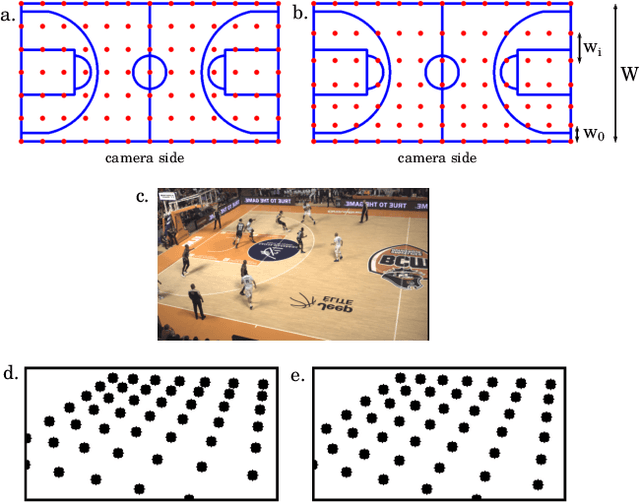

Tracking the players and the ball in team sports is key to analyse the performance or to enhance the game watching experience with augmented reality. When the only sources for this data are broadcast videos, sports-field registration systems are required to estimate the homography and re-project the ball or the players from the image space to the field space. This paper describes a new basketball court registration framework in the context of the MMSports 2022 camera calibration challenge. The method is based on the estimation by an encoder-decoder network of the positions of keypoints sampled with perspective-aware constraints. The regression of the basket positions and heavy data augmentation techniques make the model robust to different arenas. Ablation studies show the positive effects of our contributions on the challenge test set. Our method divides the mean squared error by 4.7 compared to the challenge baseline.
UCP-Net: Unstructured Contour Points for Instance Segmentation
Sep 15, 2021

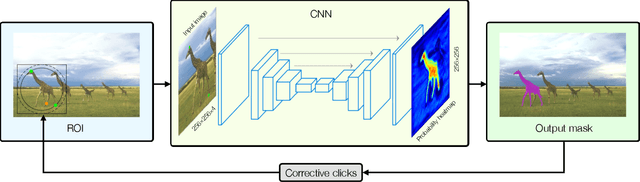
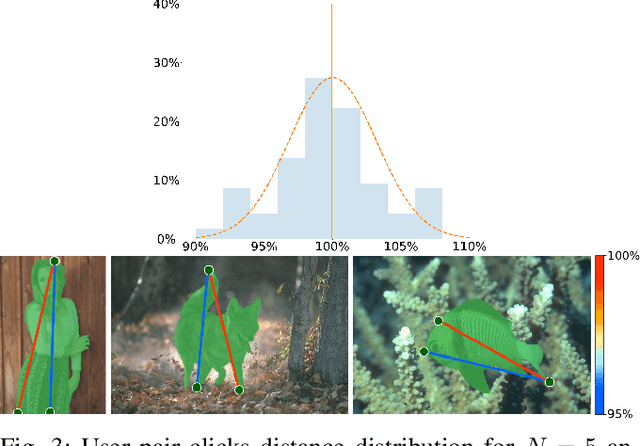
The goal of interactive segmentation is to assist users in producing segmentation masks as fast and as accurately as possible. Interactions have to be simple and intuitive and the number of interactions required to produce a satisfactory segmentation mask should be as low as possible. In this paper, we propose a novel approach to interactive segmentation based on unconstrained contour clicks for initial segmentation and segmentation refinement. Our method is class-agnostic and produces accurate segmentation masks (IoU > 85%) for a lower number of user interactions than state-of-the-art methods on popular segmentation datasets (COCO MVal, SBD and Berkeley).
Evaluating Robustness over High Level Driving Instruction for Autonomous Driving
May 20, 2021



In recent years, we have witnessed increasingly high performance in the field of autonomous end-to-end driving. In particular, more and more research is being done on driving in urban environments, where the car has to follow high level commands to navigate. However, few evaluations are made on the ability of these agents to react in an unexpected situation. Specifically, no evaluations are conducted on the robustness of driving agents in the event of a bad high-level command. We propose here an evaluation method, namely a benchmark that allows to assess the robustness of an agent, and to appreciate its understanding of the environment through its ability to keep a safe behavior, regardless of the instruction.
Deep, robust and single shot 3D multi-person human pose estimation in complex images
Nov 08, 2019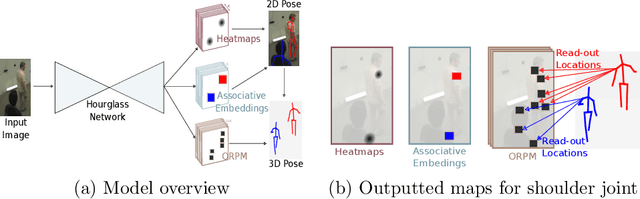
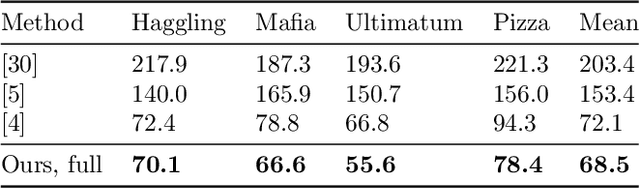

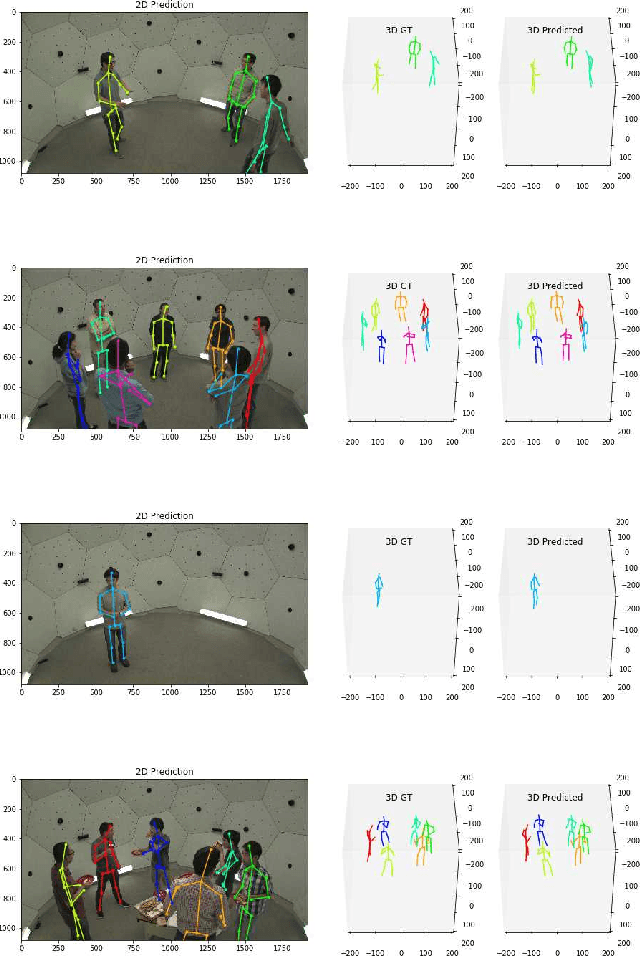
In this paper, we propose a new single shot method for multi-person 3D human pose estimation in complex images. The model jointly learns to locate the human joints in the image, to estimate their 3D coordinates and to group these predictions into full human skeletons. The proposed method deals with a variable number of people and does not need bounding boxes to estimate the 3D poses. It leverages and extends the Stacked Hourglass Network and its multi-scale feature learning to manage multi-person situations. Thus, we exploit a robust 3D human pose formulation to fully describe several 3D human poses even in case of strong occlusions or crops. Then, joint grouping and human pose estimation for an arbitrary number of people are performed using the associative embedding method. Our approach significantly outperforms the state of the art on the challenging CMU Panoptic. Furthermore, it leads to good results on the complex and synthetic images from the newly proposed JTA Dataset.
LapNet : Automatic Balanced Loss and Optimal Assignment for Real-Time Dense Object Detection
Nov 04, 2019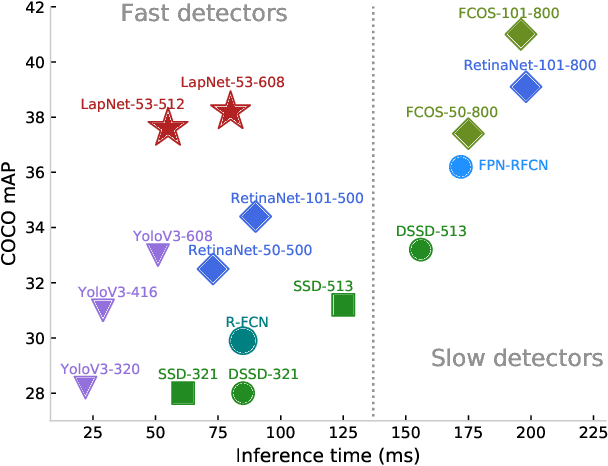
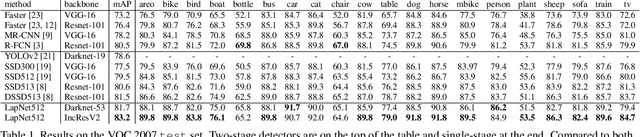

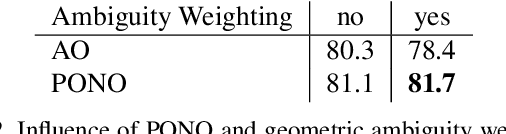
Several modern deep single-stage object detectors are really effective for real time processing but still remain less efficient than more complex ones. The trade-off between model performances and computing speed is an important challenge, directly related to the learning process. In this paper, we propose a new way to efficiently learn a single shot detector providing a very good trade-off between these two factors. For this purpose, we introduce LapNet, an anchor based detector, trained end-to-end without any sampling strategy. Our approach focuses on two limitations of anchor based detector training: (1) the ambiguity of anchor to ground truth assignment and (2) the imbalance between classes and the imbalance between object sizes. More specifically, a new method to assign positive and negative anchors is proposed, based on a new overlapping function called "Per-Object Normalized Overlap" (PONO). This more flexible assignment can be self-corrected by the network itself to avoid the ambiguity between close objects. In the learning process, we also propose to automatically learn weights to balance classes and object sizes to efficiently manage sample imbalance. It allows to build a robust object detector avoiding multi-scale prediction, in a semantic segmentation spirit.