 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOO: A Multi-view Oriented Observations Dataset for Viewpoint Analysis in Cattle Re-Identification
Mar 04, 2026Animal re-identification (ReID) faces critical challenges due to viewpoint variations, particularly in Aerial-Ground (AG-ReID) settings where models must match individuals across drastic elevation changes. However, existing datasets lack the precise angular annotations required to systematically analyze these geometric variations. To address this, we introduce the Multi-view Oriented Observation (MOO) dataset, a large-scale synthetic AG-ReID dataset of $1,000$ cattle individuals captured from $128$ uniformly sampled viewpoints ($128,000$ annotated images). Using this controlled dataset, we quantify the influence of elevation and identify a critical elevation threshold, above which models generalize significantly better to unseen views. Finally, we validate the transferability to real-world applications in both zero-shot and supervised settings, demonstrating performance gains across four real-world cattle datasets and confirming that synthetic geometric priors effectively bridge the domain gap. Collectively, this dataset and analysis lay the foundation for future model development in cross-view animal ReID. MOO is publicly available at https://github.com/TurtleSmoke/MOO.
iMatcher: Improve matching in point cloud registration via local-to-global geometric consistency learning
Sep 10, 2025This paper presents iMatcher, a fully differentiable framework for feature matching in point cloud registration. The proposed method leverages learned features to predict a geometrically consistent confidence matrix, incorporating both local and global consistency. First, a local graph embedding module leads to an initialization of the score matrix. A subsequent repositioning step refines this matrix by considering bilateral source-to-target and target-to-source matching via nearest neighbor search in 3D space. The paired point features are then stacked together to be refined through global geometric consistency learning to predict a point-wise matching probability. Extensive experiments on real-world outdoor (KITTI, KITTI-360) and indoor (3DMatch) datasets, as well as on 6-DoF pose estimation (TUD-L) and partial-to-partial matching (MVP-RG), demonstrate that iMatcher significantly improves rigid registration performance. The method achieves state-of-the-art inlier ratios, scoring 95% - 97% on KITTI, 94% - 97% on KITTI-360, and up to 81.1% on 3DMatch, highlighting its robustness across diverse settings.
SFB-net for cardiac segmentation: Bridging the semantic gap with attention
Oct 24, 2024



In the past few years, deep learning algorithms have been widely used for cardiac image segmentation. However, most of these architectures rely on convolutions that hardly model long-range dependencies, limiting their ability to extract contextual information. In order to tackle this issue, this article introduces the Swin Filtering Block network (SFB-net) which takes advantage of both conventional and swin transformer layers. The former are used to introduce spatial attention at the bottom of the network, while the latter are applied to focus on high level semantically rich features between the encoder and decoder. An average Dice score of 92.4 was achieved on the ACDC dataset. To the best of our knowledge, this result outperforms any other work on this dataset. The average Dice score of 87.99 obtained on the M\&M's dataset demonstrates that the proposed method generalizes well to data from different vendors and centres.
LoGDesc: Local geometric features aggregation for robust point cloud registration
Oct 03, 2024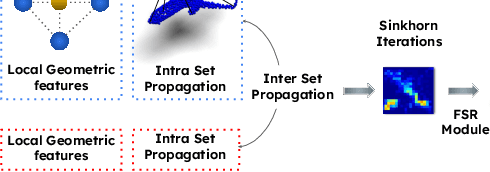
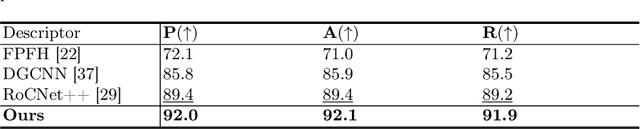
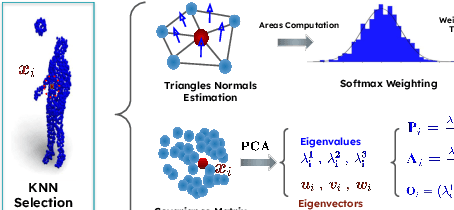
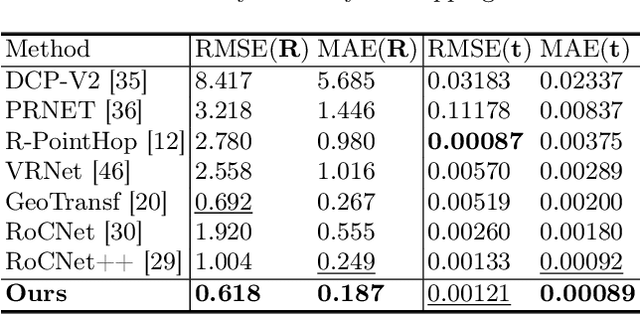
This paper introduces a new hybrid descriptor for 3D point matching and point cloud registration, combining local geometrical properties and learning-based feature propagation for each point's neighborhood structure description. The proposed architecture first extracts prior geometrical information by computing each point's planarity, anisotropy, and omnivariance using a Principal Components Analysis (PCA). This prior information is completed by a descriptor based on the normal vectors estimated thanks to constructing a neighborhood based on triangles. The final geometrical descriptor is propagated between the points using local graph convolutions and attention mechanisms. The new feature extractor is evaluated on ModelNet40, Bunny Stanford dataset, KITTI and MVP (Multi-View Partial)-RG for point cloud registration and shows interesting results, particularly on noisy and low overlapping point clouds.
AMII: Adaptive Multimodal Inter-personal and Intra-personal Model for Adapted Behavior Synthesis
May 18, 2023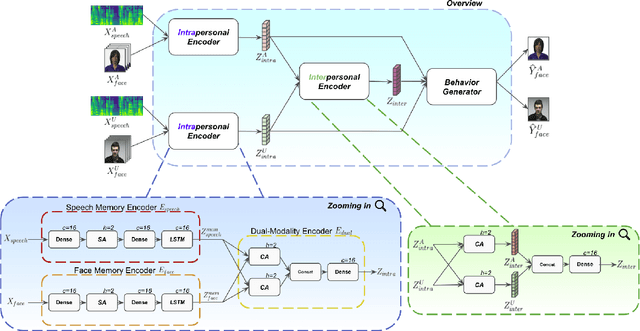
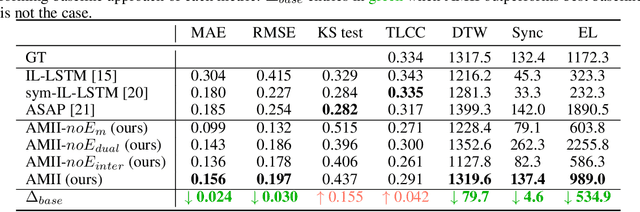
Socially Interactive Agents (SIAs) are physical or virtual embodied agents that display similar behavior as human multimodal behavior. Modeling SIAs' non-verbal behavior, such as speech and facial gestures, has always been a challenging task, given that a SIA can take the role of a speaker or a listener. A SIA must emit appropriate behavior adapted to its own speech, its previous behaviors (intra-personal), and the User's behaviors (inter-personal) for both roles. We propose AMII, a novel approach to synthesize adaptive facial gestures for SIAs while interacting with Users and acting interchangeably as a speaker or as a listener. AMII is characterized by modality memory encoding schema - where modality corresponds to either speech or facial gestures - and makes use of attention mechanisms to capture the intra-personal and inter-personal relationships. We validate our approach by conducting objective evaluations and comparing it with the state-of-the-art approaches.
RoCNet: 3D Robust Registration of Point-Clouds using Deep Learning
Mar 14, 2023This paper introduces a new method for 3D point cloud registration based on deep learning. The architecture is composed of three distinct blocs: (i) an encoder composed of a convolutional graph-based descriptor that encodes the immediate neighbourhood of each point and an attention mechanism that encodes the variations of the surface normals. Such descriptors are refined by highlighting attention between the points of the same set and then between the points of the two sets. (ii) a matching process that estimates a matrix of correspondences using the Sinkhorn algorithm. (iii) Finally, the rigid transformation between the two point clouds is calculated by RANSAC using the Kc best scores from the correspondence matrix. We conduct experiments on the ModelNet40 dataset, and our proposed architecture shows very promising results, outperforming state-of-the-art methods in most of the simulated configurations, including partial overlap and data augmentation with Gaussian noise.
SALAD: Self-Assessment Learning for Action Detection
Nov 13, 2020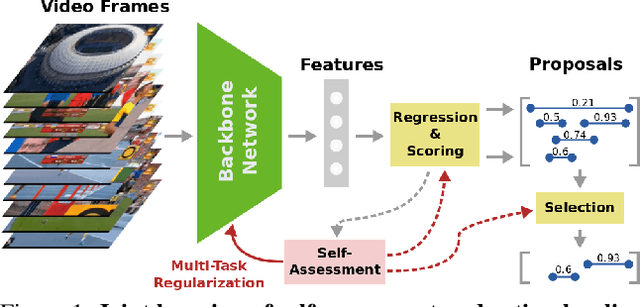
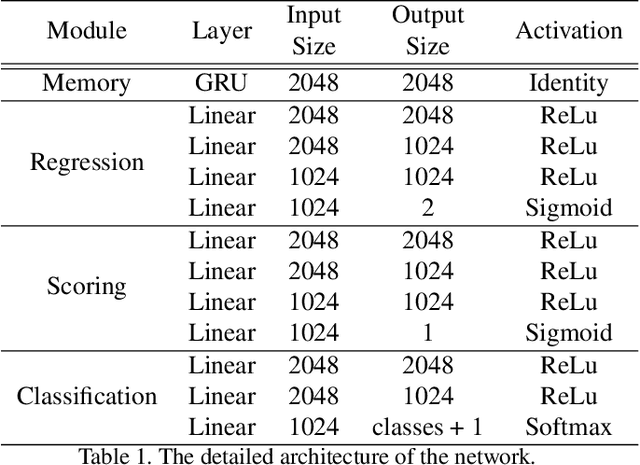
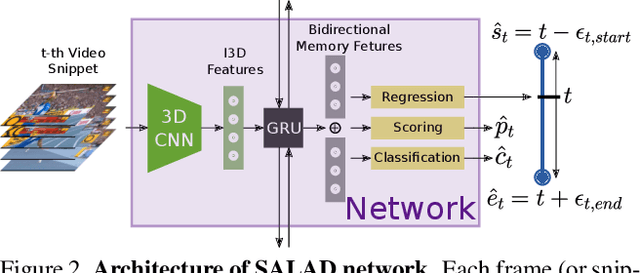
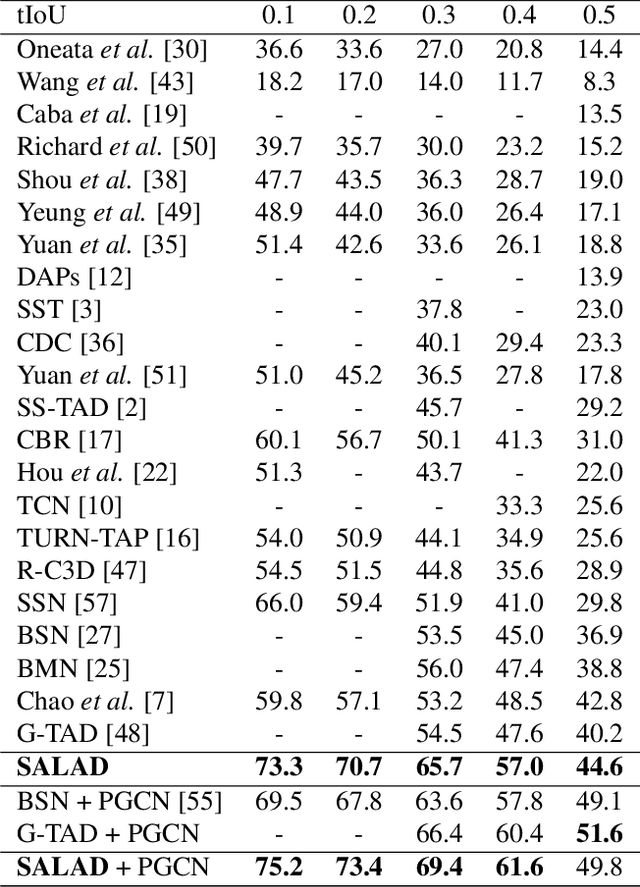
Literature on self-assessment in machine learning mainly focuses on the production of well-calibrated algorithms through consensus frameworks i.e. calibration is seen as a problem. Yet, we observe that learning to be properly confident could behave like a powerful regularization and thus, could be an opportunity to improve performance.Precisely, we show that used within a framework of action detection, the learning of a self-assessment score is able to improve the whole action localization process.Experimental results show that our approach outperforms the state-of-the-art on two action detection benchmarks. On THUMOS14 dataset, the mAP at tIoU@0.5 is improved from 42.8\% to 44.6\%, and from 50.4\% to 51.7\% on ActivityNet1.3 dataset. For lower tIoU values, we achieve even more significant improvements on both datasets.
ActionSpotter: Deep Reinforcement Learning Framework for Temporal Action Spotting in Videos
Apr 15, 2020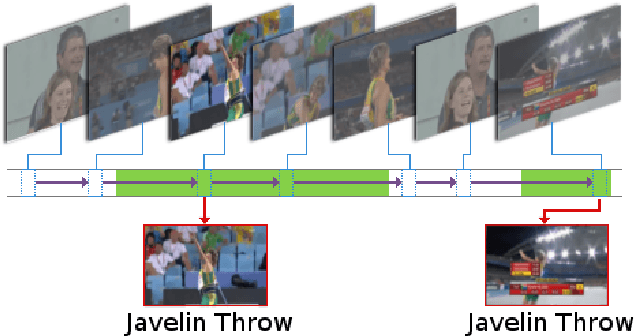
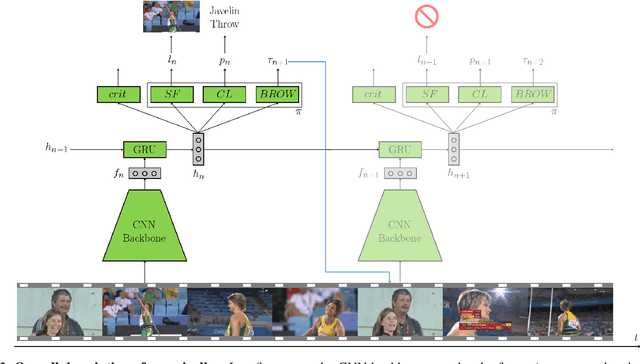
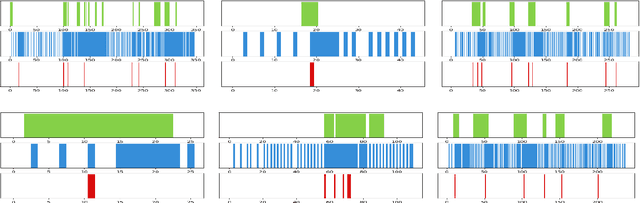
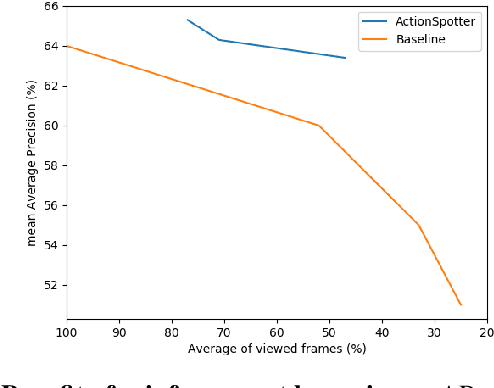
Summarizing video content is an important task in many applications. This task can be defined as the computation of the ordered list of actions present in a video. Such a list could be extracted using action detection algorithms. However, it is not necessary to determine the temporal boundaries of actions to know their existence. Moreover, localizing precise boundaries usually requires dense video analysis to be effective. In this work, we propose to directly compute this ordered list by sparsely browsing the video and selecting one frame per action instance, task known as action spotting in literature. To do this, we propose ActionSpotter, a spotting algorithm that takes advantage of Deep Reinforcement Learning to efficiently spot actions while adapting its video browsing speed, without additional supervision. Experiments performed on datasets THUMOS14 and ActivityNet show that our framework outperforms state of the art detection methods. In particular, the spotting mean Average Precision on THUMOS14 is significantly improved from 59.7% to 65.6% while skipping 23% of video.
Explaining Regression Based Neural Network Model
Apr 15, 2020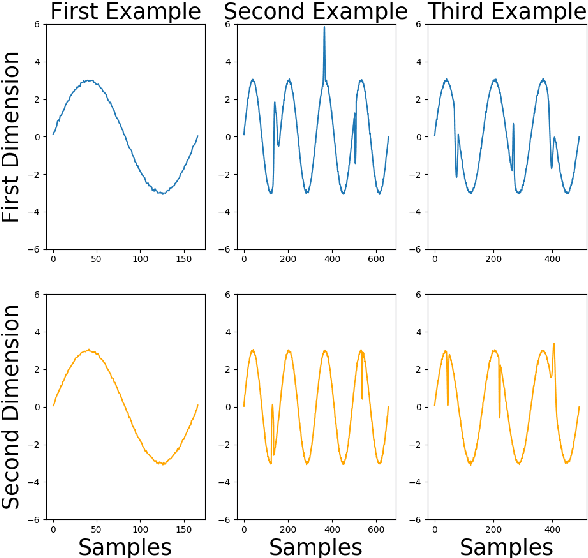
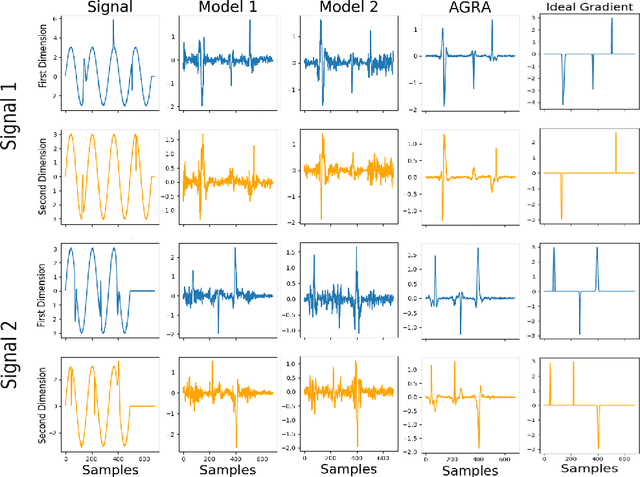
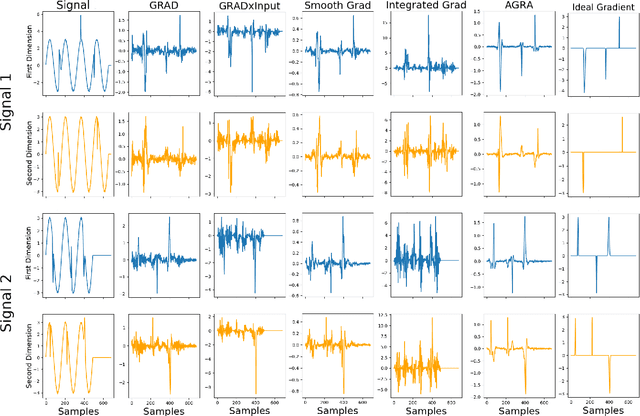
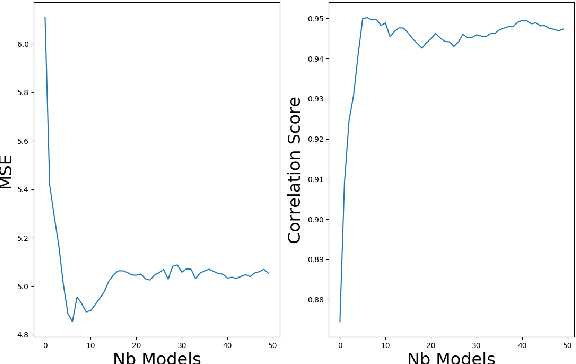
Several methods have been proposed to explain Deep Neural Network (DNN). However, to our knowledge, only classification networks have been studied to try to determine which input dimensions motivated the decision. Furthermore, as there is no ground truth to this problem, results are only assessed qualitatively in regards to what would be meaningful for a human. In this work, we design an experimental settings where the ground truth can been established: we generate ideal signals and disrupted signals with errors and learn a neural network that determines the quality of the signals. This quality is simply a score based on the distance between the disrupted signals and the corresponding ideal signal. We then try to find out how the network estimated this score and hope to find the time-step and dimensions of the signal where errors are present. This experimental setting enables us to compare several methods for network explanation and to propose a new method, named AGRA for Accurate Gradient, based on several trainings that decrease the noise present in most state-of-the-art results. Comparative results show that the proposed method outperforms state-of-the-art methods for locating time-steps where errors occur in the signal.
Deep, robust and single shot 3D multi-person human pose estimation in complex images
Nov 08, 2019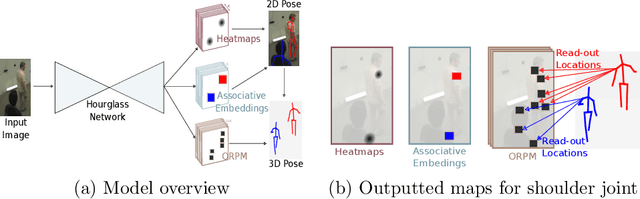
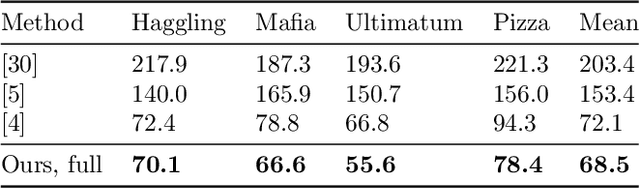

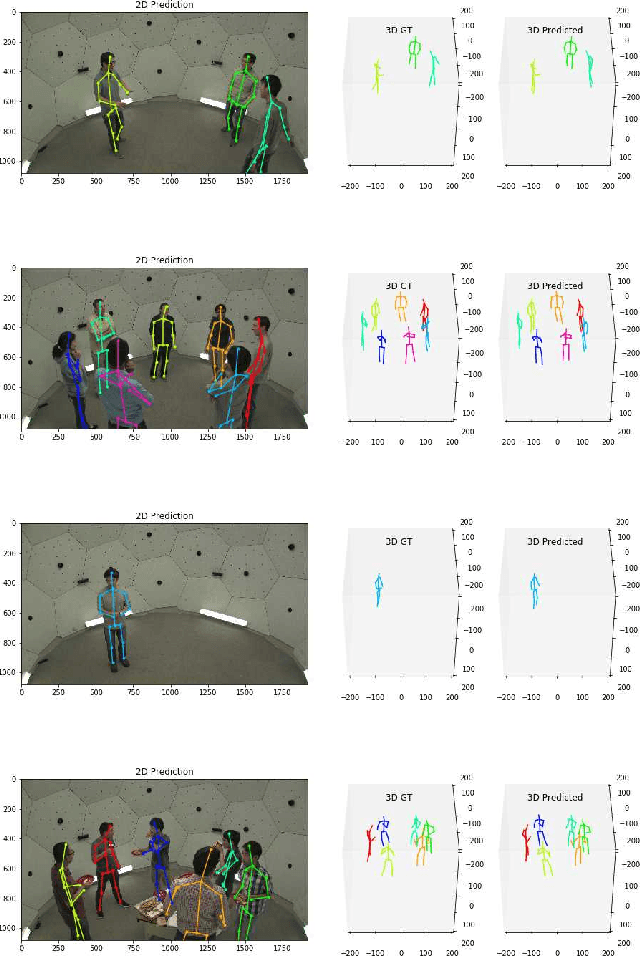
In this paper, we propose a new single shot method for multi-person 3D human pose estimation in complex images. The model jointly learns to locate the human joints in the image, to estimate their 3D coordinates and to group these predictions into full human skeletons. The proposed method deals with a variable number of people and does not need bounding boxes to estimate the 3D poses. It leverages and extends the Stacked Hourglass Network and its multi-scale feature learning to manage multi-person situations. Thus, we exploit a robust 3D human pose formulation to fully describe several 3D human poses even in case of strong occlusions or crops. Then, joint grouping and human pose estimation for an arbitrary number of people are performed using the associative embedding method. Our approach significantly outperforms the state of the art on the challenging CMU Panoptic. Furthermore, it leads to good results on the complex and synthetic images from the newly proposed JTA Dataset.