 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe GENEA Challenge 2023: A large scale evaluation of gesture generation models in monadic and dyadic settings
Aug 24, 2023This paper reports on the GENEA Challenge 2023, in which participating teams built speech-driven gesture-generation systems using the same speech and motion dataset, followed by a joint evaluation. This year's challenge provided data on both sides of a dyadic interaction, allowing teams to generate full-body motion for an agent given its speech (text and audio) and the speech and motion of the interlocutor. We evaluated 12 submissions and 2 baselines together with held-out motion-capture data in several large-scale user studies. The studies focused on three aspects: 1) the human-likeness of the motion, 2) the appropriateness of the motion for the agent's own speech whilst controlling for the human-likeness of the motion, and 3) the appropriateness of the motion for the behaviour of the interlocutor in the interaction, using a setup that controls for both the human-likeness of the motion and the agent's own speech. We found a large span in human-likeness between challenge submissions, with a few systems rated close to human mocap. Appropriateness seems far from being solved, with most submissions performing in a narrow range slightly above chance, far behind natural motion. The effect of the interlocutor is even more subtle, with submitted systems at best performing barely above chance. Interestingly, a dyadic system being highly appropriate for agent speech does not necessarily imply high appropriateness for the interlocutor. Additional material is available via the project website at https://svito-zar.github.io/GENEAchallenge2023/ .
AMII: Adaptive Multimodal Inter-personal and Intra-personal Model for Adapted Behavior Synthesis
May 18, 2023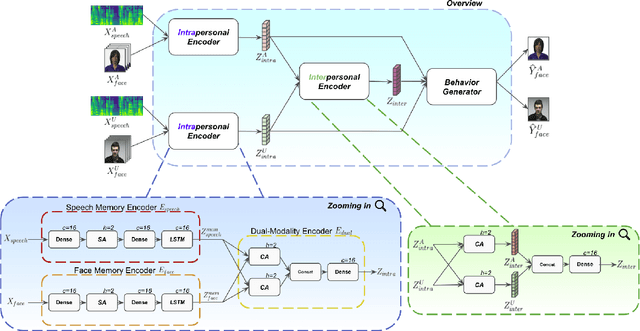
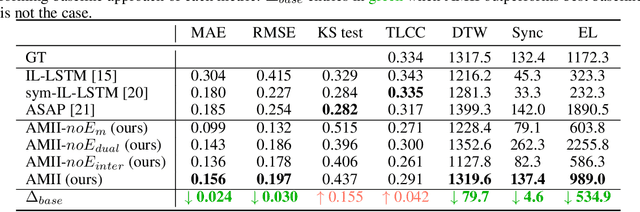
Socially Interactive Agents (SIAs) are physical or virtual embodied agents that display similar behavior as human multimodal behavior. Modeling SIAs' non-verbal behavior, such as speech and facial gestures, has always been a challenging task, given that a SIA can take the role of a speaker or a listener. A SIA must emit appropriate behavior adapted to its own speech, its previous behaviors (intra-personal), and the User's behaviors (inter-personal) for both roles. We propose AMII, a novel approach to synthesize adaptive facial gestures for SIAs while interacting with Users and acting interchangeably as a speaker or as a listener. AMII is characterized by modality memory encoding schema - where modality corresponds to either speech or facial gestures - and makes use of attention mechanisms to capture the intra-personal and inter-personal relationships. We validate our approach by conducting objective evaluations and comparing it with the state-of-the-art approaches.