 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailored Conversations beyond LLMs: A RL-Based Dialogue Manager
Jun 24, 2025In this work, we propose a novel framework that integrates large language models (LLMs) with an RL-based dialogue manager for open-ended dialogue with a specific goal. By leveraging hierarchical reinforcement learning to model the structured phases of dialogue and employ meta-learning to enhance adaptability across diverse user profiles, our approach enhances adaptability and efficiency, enabling the system to learn from limited data, transition fluidly between dialogue phases, and personalize responses to heterogeneous patient needs. We apply our framework to Motivational Interviews, aiming to foster behavior change, and demonstrate that the proposed dialogue manager outperforms a state-of-the-art LLM baseline in terms of reward, showing a potential benefit of conditioning LLMs to create open-ended dialogue systems with specific goals.
Voice Activity Projection Model with Multimodal Encoders
Jun 04, 2025Turn-taking management is crucial for any social interaction. Still, it is challenging to model human-machine interaction due to the complexity of the social context and its multimodal nature. Unlike conventional systems based on silence duration, previous existing voice activity projection (VAP) models successfully utilized a unified representation of turn-taking behaviors as prediction targets, which improved turn-taking prediction performance. Recently, a multimodal VAP model outperformed the previous state-of-the-art model by a significant margin. In this paper, we propose a multimodal model enhanced with pre-trained audio and face encoders to improve performance by capturing subtle expressions. Our model performed competitively, and in some cases, even better than state-of-the-art models on turn-taking metrics. All the source codes and pretrained models are available at https://github.com/sagatake/VAPwithAudioFaceEncoders.
An action language-based formalisation of an abstract argumentation framework
Sep 29, 2024
An abstract argumentation framework is a commonly used formalism to provide a static representation of a dialogue. However, the order of enunciation of the arguments in an argumentative dialogue is very important and can affect the outcome of this dialogue. In this paper, we propose a new framework for modelling abstract argumentation graphs, a model that incorporates the order of enunciation of arguments. By taking this order into account, we have the means to deduce a unique outcome for each dialogue, called an extension. We also establish several properties, such as termination and correctness, and discuss two notions of completeness. In particular, we propose a modification of the previous transformation based on a "last enunciated last updated" strategy, which verifies the second form of completeness.
2D or not 2D: How Does the Dimensionality of Gesture Representation Affect 3D Co-Speech Gesture Generation?
Sep 16, 2024Co-speech gestures are fundamental for communication. The advent of recent deep learning techniques has facilitated the creation of lifelike, synchronous co-speech gestures for Embodied Conversational Agents. "In-the-wild" datasets, aggregating video content from platforms like YouTube via human pose detection technologies, provide a feasible solution by offering 2D skeletal sequences aligned with speech. Concurrent developments in lifting models enable the conversion of these 2D sequences into 3D gesture databases. However, it is important to note that the 3D poses estimated from the 2D extracted poses are, in essence, approximations of the ground-truth, which remains in the 2D domain. This distinction raises questions about the impact of gesture representation dimensionality on the quality of generated motions - a topic that, to our knowledge, remains largely unexplored. Our study examines the effect of using either 2D or 3D joint coordinates as training data on the performance of speech-to-gesture deep generative models. We employ a lifting model for converting generated 2D pose sequences into 3D and assess how gestures created directly in 3D stack up against those initially generated in 2D and then converted to 3D. We perform an objective evaluation using widely used metrics in the gesture generation field as well as a user study to qualitatively evaluate the different approaches.
Exploiting temporal information to detect conversational groups in videos and predict the next speaker
Aug 29, 2024



Studies in human human interaction have introduced the concept of F formation to describe the spatial arrangement of participants during social interactions. This paper has two objectives. It aims at detecting F formations in video sequences and predicting the next speaker in a group conversation. The proposed approach exploits time information and human multimodal signals in video sequences. In particular, we rely on measuring the engagement level of people as a feature of group belonging. Our approach makes use of a recursive neural network, the Long Short Term Memory (LSTM), to predict who will take the speaker's turn in a conversation group. Experiments on the MatchNMingle dataset led to 85% true positives in group detection and 98% accuracy in predicting the next speaker.
* Accepted to Pattern Recognition Letter, 8 pages, 10 figures
EMMI -- Empathic Multimodal Motivational Interviews Dataset: Analyses and Annotations
Jun 24, 2024The study of multimodal interaction in therapy can yield a comprehensive understanding of therapist and patient behavior that can be used to develop a multimodal virtual agent supporting therapy. This investigation aims to uncover how therapists skillfully blend therapy's task goal (employing classical steps of Motivational Interviewing) with the social goal (building a trusting relationship and expressing empathy). Furthermore, we seek to categorize patients into various ``types'' requiring tailored therapeutic approaches. To this intent, we present multimodal annotations of a corpus consisting of simulated motivational interviewing conversations, wherein actors portray the roles of patients and therapists. We introduce EMMI, composed of two publicly available MI corpora, AnnoMI and the Motivational Interviewing Dataset, for which we add multimodal annotations. We analyze these annotations to characterize functional behavior for developing a virtual agent performing motivational interviews emphasizing social and empathic behaviors. Our analysis found three clusters of patients expressing significant differences in behavior and adaptation of the therapist's behavior to those types. This shows the importance of a therapist being able to adapt their behavior depending on the current situation within the dialog and the type of user.
Investigating the impact of 2D gesture representation on co-speech gesture generation
Jun 24, 2024



Co-speech gestures play a crucial role in the interactions between humans and embodied conversational agents (ECA). Recent deep learning methods enable the generation of realistic, natural co-speech gestures synchronized with speech, but such approaches require large amounts of training data. "In-the-wild" datasets, which compile videos from sources such as YouTube through human pose detection models, offer a solution by providing 2D skeleton sequences that are paired with speech. Concurrently, innovative lifting models have emerged, capable of transforming these 2D pose sequences into their 3D counterparts, leading to large and diverse datasets of 3D gestures. However, the derived 3D pose estimation is essentially a pseudo-ground truth, with the actual ground truth being the 2D motion data. This distinction raises questions about the impact of gesture representation dimensionality on the quality of generated motions, a topic that, to our knowledge, remains largely unexplored. In this work, we evaluate the impact of the dimensionality of the training data, 2D or 3D joint coordinates, on the performance of a multimodal speech-to-gesture deep generative model. We use a lifting model to convert 2D-generated sequences of body pose to 3D. Then, we compare the sequence of gestures generated directly in 3D to the gestures generated in 2D and lifted to 3D as post-processing.
META4: Semantically-Aligned Generation of Metaphoric Gestures Using Self-Supervised Text and Speech Representation
Nov 21, 2023



Image Schemas are repetitive cognitive patterns that influence the way we conceptualize and reason about various concepts present in speech. These patterns are deeply embedded within our cognitive processes and are reflected in our bodily expressions including gestures. Particularly, metaphoric gestures possess essential characteristics and semantic meanings that align with Image Schemas, to visually represent abstract concepts. The shape and form of gestures can convey abstract concepts, such as extending the forearm and hand or tracing a line with hand movements to visually represent the image schema of PATH. Previous behavior generation models have primarily focused on utilizing speech (acoustic features and text) to drive the generation model of virtual agents. They have not considered key semantic information as those carried by Image Schemas to effectively generate metaphoric gestures. To address this limitation, we introduce META4, a deep learning approach that generates metaphoric gestures from both speech and Image Schemas. Our approach has two primary goals: computing Image Schemas from input text to capture the underlying semantic and metaphorical meaning, and generating metaphoric gestures driven by speech and the computed image schemas. Our approach is the first method for generating speech driven metaphoric gestures while leveraging the potential of Image Schemas. We demonstrate the effectiveness of our approach and highlight the importance of both speech and image schemas in modeling metaphoric gestures.
Seeing and hearing what has not been said; A multimodal client behavior classifier in Motivational Interviewing with interpretable fusion
Sep 27, 2023



Motivational Interviewing (MI) is an approach to therapy that emphasizes collaboration and encourages behavioral change. To evaluate the quality of an MI conversation, client utterances can be classified using the MISC code as either change talk, sustain talk, or follow/neutral talk. The proportion of change talk in a MI conversation is positively correlated with therapy outcomes, making accurate classification of client utterances essential. In this paper, we present a classifier that accurately distinguishes between the three MISC classes (change talk, sustain talk, and follow/neutral talk) leveraging multimodal features such as text, prosody, facial expressivity, and body expressivity. To train our model, we perform annotations on the publicly available AnnoMI dataset to collect multimodal information, including text, audio, facial expressivity, and body expressivity. Furthermore, we identify the most important modalities in the decision-making process, providing valuable insights into the interplay of different modalities during a MI conversation.
TranSTYLer: Multimodal Behavioral Style Transfer for Facial and Body Gestures Generation
Aug 08, 2023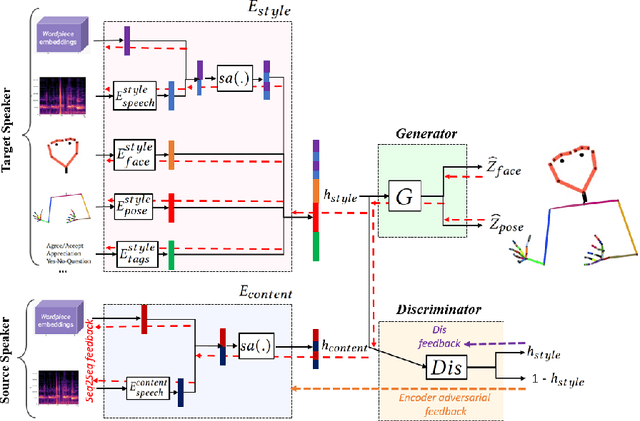

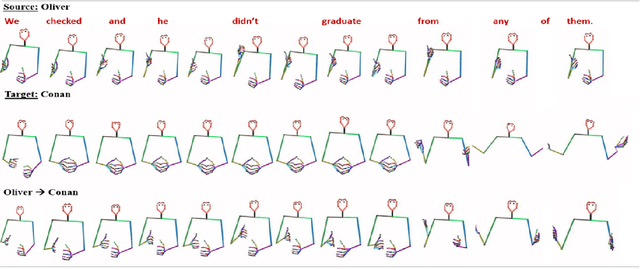
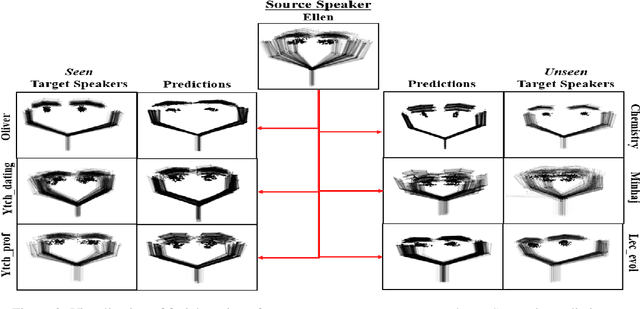
This paper addresses the challenge of transferring the behavior expressivity style of a virtual agent to another one while preserving behaviors shape as they carry communicative meaning. Behavior expressivity style is viewed here as the qualitative properties of behaviors. We propose TranSTYLer, a multimodal transformer based model that synthesizes the multimodal behaviors of a source speaker with the style of a target speaker. We assume that behavior expressivity style is encoded across various modalities of communication, including text, speech, body gestures, and facial expressions. The model employs a style and content disentanglement schema to ensure that the transferred style does not interfere with the meaning conveyed by the source behaviors. Our approach eliminates the need for style labels and allows the generalization to styles that have not been seen during the training phase. We train our model on the PATS corpus, which we extended to include dialog acts and 2D facial landmarks. Objective and subjective evaluations show that our model outperforms state of the art models in style transfer for both seen and unseen styles during training. To tackle the issues of style and content leakage that may arise, we propose a methodology to assess the degree to which behavior and gestures associated with the target style are successfully transferred, while ensuring the preservation of the ones related to the source content.