 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLina-Speech: Gated Linear Attention is a Fast and Parameter-Efficient Learner for text-to-speech synthesis
Oct 30, 2024



Neural codec language models have achieved state-of-the-art performance in text-to-speech (TTS) synthesis, leveraging scalable architectures like autoregressive transformers and large-scale speech datasets. By framing voice cloning as a prompt continuation task, these models excel at cloning voices from short audio samples. However, this approach is limited in its ability to handle numerous or lengthy speech excerpts, since the concatenation of source and target speech must fall within the maximum context length which is determined during training. In this work, we introduce Lina-Speech, a model that replaces traditional self-attention mechanisms with emerging recurrent architectures like Gated Linear Attention (GLA). Building on the success of initial-state tuning on RWKV, we extend this technique to voice cloning, enabling the use of multiple speech samples and full utilization of the context window in synthesis. This approach is fast, easy to deploy, and achieves performance comparable to fine-tuned baselines when the dataset size ranges from 3 to 15 minutes. Notably, Lina-Speech matches or outperforms state-of-the-art baseline models, including some with a parameter count up to four times higher or trained in an end-to-end style. We release our code and checkpoints. Audio samples are available at https://theodorblackbird.github.io/blog/demo_lina/.
2D or not 2D: How Does the Dimensionality of Gesture Representation Affect 3D Co-Speech Gesture Generation?
Sep 16, 2024Co-speech gestures are fundamental for communication. The advent of recent deep learning techniques has facilitated the creation of lifelike, synchronous co-speech gestures for Embodied Conversational Agents. "In-the-wild" datasets, aggregating video content from platforms like YouTube via human pose detection technologies, provide a feasible solution by offering 2D skeletal sequences aligned with speech. Concurrent developments in lifting models enable the conversion of these 2D sequences into 3D gesture databases. However, it is important to note that the 3D poses estimated from the 2D extracted poses are, in essence, approximations of the ground-truth, which remains in the 2D domain. This distinction raises questions about the impact of gesture representation dimensionality on the quality of generated motions - a topic that, to our knowledge, remains largely unexplored. Our study examines the effect of using either 2D or 3D joint coordinates as training data on the performance of speech-to-gesture deep generative models. We employ a lifting model for converting generated 2D pose sequences into 3D and assess how gestures created directly in 3D stack up against those initially generated in 2D and then converted to 3D. We perform an objective evaluation using widely used metrics in the gesture generation field as well as a user study to qualitatively evaluate the different approaches.
Investigating the impact of 2D gesture representation on co-speech gesture generation
Jun 24, 2024



Co-speech gestures play a crucial role in the interactions between humans and embodied conversational agents (ECA). Recent deep learning methods enable the generation of realistic, natural co-speech gestures synchronized with speech, but such approaches require large amounts of training data. "In-the-wild" datasets, which compile videos from sources such as YouTube through human pose detection models, offer a solution by providing 2D skeleton sequences that are paired with speech. Concurrently, innovative lifting models have emerged, capable of transforming these 2D pose sequences into their 3D counterparts, leading to large and diverse datasets of 3D gestures. However, the derived 3D pose estimation is essentially a pseudo-ground truth, with the actual ground truth being the 2D motion data. This distinction raises questions about the impact of gesture representation dimensionality on the quality of generated motions, a topic that, to our knowledge, remains largely unexplored. In this work, we evaluate the impact of the dimensionality of the training data, 2D or 3D joint coordinates, on the performance of a multimodal speech-to-gesture deep generative model. We use a lifting model to convert 2D-generated sequences of body pose to 3D. Then, we compare the sequence of gestures generated directly in 3D to the gestures generated in 2D and lifted to 3D as post-processing.
Small-E: Small Language Model with Linear Attention for Efficient Speech Synthesis
Jun 06, 2024



Recent advancements in text-to-speech (TTS) powered by language models have showcased remarkable capabilities in achieving naturalness and zero-shot voice cloning. Notably, the decoder-only transformer is the prominent architecture in this domain. However, transformers face challenges stemming from their quadratic complexity in sequence length, impeding training on lengthy sequences and resource-constrained hardware. Moreover they lack specific inductive bias with regards to the monotonic nature of TTS alignments. In response, we propose to replace transformers with emerging recurrent architectures and introduce specialized cross-attention mechanisms for reducing repeating and skipping issues. Consequently our architecture can be efficiently trained on long samples and achieve state-of-the-art zero-shot voice cloning against baselines of comparable size.
META4: Semantically-Aligned Generation of Metaphoric Gestures Using Self-Supervised Text and Speech Representation
Nov 21, 2023



Image Schemas are repetitive cognitive patterns that influence the way we conceptualize and reason about various concepts present in speech. These patterns are deeply embedded within our cognitive processes and are reflected in our bodily expressions including gestures. Particularly, metaphoric gestures possess essential characteristics and semantic meanings that align with Image Schemas, to visually represent abstract concepts. The shape and form of gestures can convey abstract concepts, such as extending the forearm and hand or tracing a line with hand movements to visually represent the image schema of PATH. Previous behavior generation models have primarily focused on utilizing speech (acoustic features and text) to drive the generation model of virtual agents. They have not considered key semantic information as those carried by Image Schemas to effectively generate metaphoric gestures. To address this limitation, we introduce META4, a deep learning approach that generates metaphoric gestures from both speech and Image Schemas. Our approach has two primary goals: computing Image Schemas from input text to capture the underlying semantic and metaphorical meaning, and generating metaphoric gestures driven by speech and the computed image schemas. Our approach is the first method for generating speech driven metaphoric gestures while leveraging the potential of Image Schemas. We demonstrate the effectiveness of our approach and highlight the importance of both speech and image schemas in modeling metaphoric gestures.
BWSNet: Automatic Perceptual Assessment of Audio Signals
Sep 05, 2023



This paper introduces BWSNet, a model that can be trained from raw human judgements obtained through a Best-Worst scaling (BWS) experiment. It maps sound samples into an embedded space that represents the perception of a studied attribute. To this end, we propose a set of cost functions and constraints, interpreting trial-wise ordinal relations as distance comparisons in a metric learning task. We tested our proposal on data from two BWS studies investigating the perception of speech social attitudes and timbral qualities. For both datasets, our results show that the structure of the latent space is faithful to human judgements.
TranSTYLer: Multimodal Behavioral Style Transfer for Facial and Body Gestures Generation
Aug 08, 2023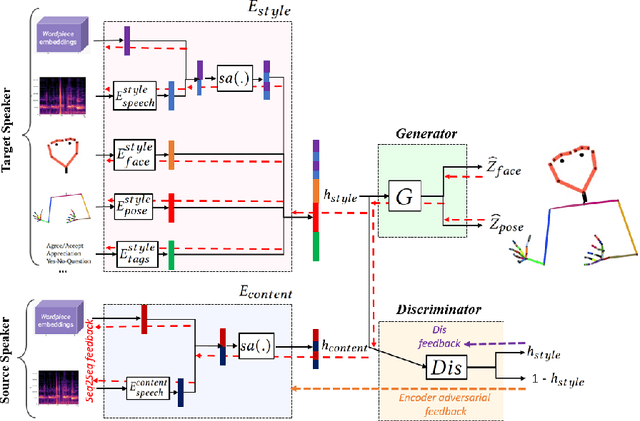

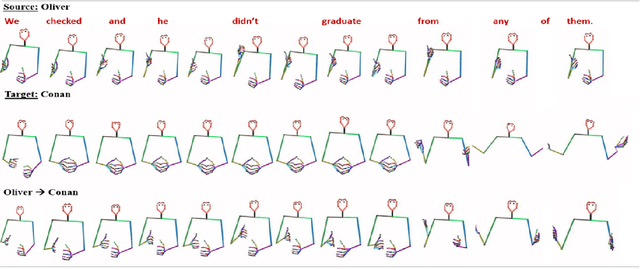
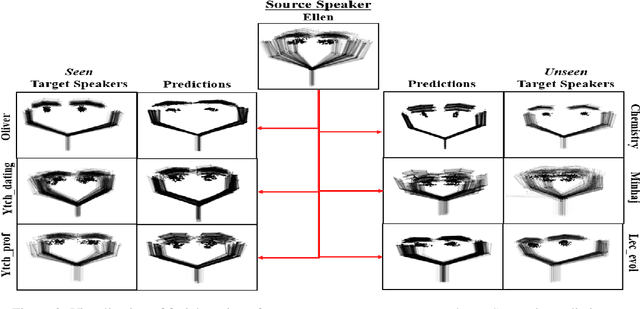
This paper addresses the challenge of transferring the behavior expressivity style of a virtual agent to another one while preserving behaviors shape as they carry communicative meaning. Behavior expressivity style is viewed here as the qualitative properties of behaviors. We propose TranSTYLer, a multimodal transformer based model that synthesizes the multimodal behaviors of a source speaker with the style of a target speaker. We assume that behavior expressivity style is encoded across various modalities of communication, including text, speech, body gestures, and facial expressions. The model employs a style and content disentanglement schema to ensure that the transferred style does not interfere with the meaning conveyed by the source behaviors. Our approach eliminates the need for style labels and allows the generalization to styles that have not been seen during the training phase. We train our model on the PATS corpus, which we extended to include dialog acts and 2D facial landmarks. Objective and subjective evaluations show that our model outperforms state of the art models in style transfer for both seen and unseen styles during training. To tackle the issues of style and content leakage that may arise, we propose a methodology to assess the degree to which behavior and gestures associated with the target style are successfully transferred, while ensuring the preservation of the ones related to the source content.
ZS-MSTM: Zero-Shot Style Transfer for Gesture Animation driven by Text and Speech using Adversarial Disentanglement of Multimodal Style Encoding
May 22, 2023In this study, we address the importance of modeling behavior style in virtual agents for personalized human-agent interaction. We propose a machine learning approach to synthesize gestures, driven by prosodic features and text, in the style of different speakers, even those unseen during training. Our model incorporates zero-shot multimodal style transfer using multimodal data from the PATS database, which contains videos of diverse speakers. We recognize style as a pervasive element during speech, influencing the expressivity of communicative behaviors, while content is conveyed through multimodal signals and text. By disentangling content and style, we directly infer the style embedding, even for speakers not included in the training phase, without the need for additional training or fine-tuning. Objective and subjective evaluations are conducted to validate our approach and compare it against two baseline methods.
Zero-Shot Style Transfer for Gesture Animation driven by Text and Speech using Adversarial Disentanglement of Multimodal Style Encoding
Aug 03, 2022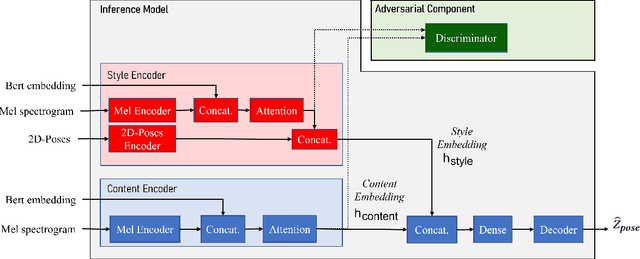

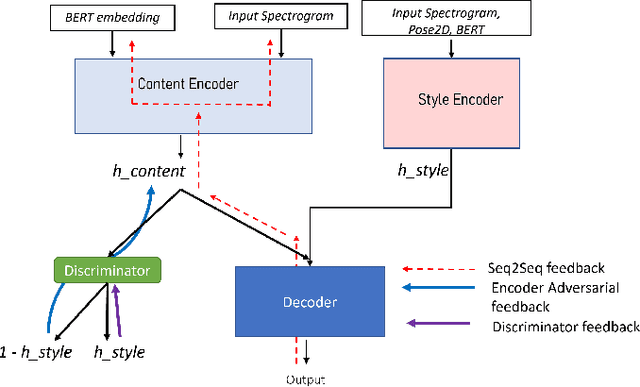
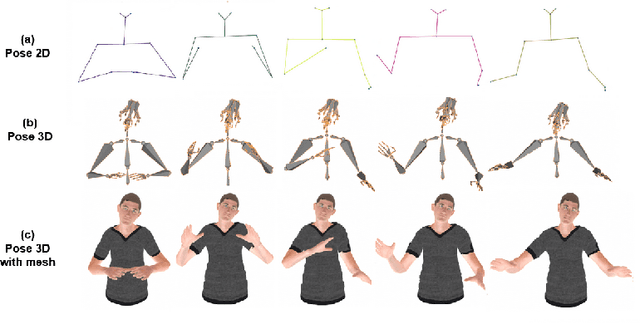
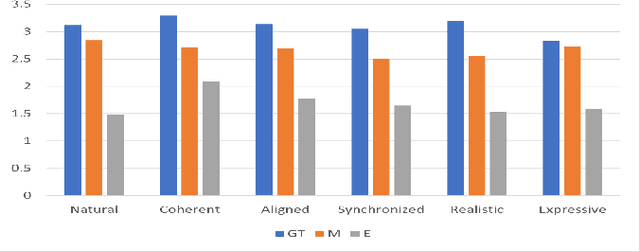
Modeling virtual agents with behavior style is one factor for personalizing human agent interaction. We propose an efficient yet effective machine learning approach to synthesize gestures driven by prosodic features and text in the style of different speakers including those unseen during training. Our model performs zero shot multimodal style transfer driven by multimodal data from the PATS database containing videos of various speakers. We view style as being pervasive while speaking, it colors the communicative behaviors expressivity while speech content is carried by multimodal signals and text. This disentanglement scheme of content and style allows us to directly infer the style embedding even of speaker whose data are not part of the training phase, without requiring any further training or fine tuning. The first goal of our model is to generate the gestures of a source speaker based on the content of two audio and text modalities. The second goal is to condition the source speaker predicted gestures on the multimodal behavior style embedding of a target speaker. The third goal is to allow zero shot style transfer of speakers unseen during training without retraining the model. Our system consists of: (1) a speaker style encoder network that learns to generate a fixed dimensional speaker embedding style from a target speaker multimodal data and (2) a sequence to sequence synthesis network that synthesizes gestures based on the content of the input modalities of a source speaker and conditioned on the speaker style embedding. We evaluate that our model can synthesize gestures of a source speaker and transfer the knowledge of target speaker style variability to the gesture generation task in a zero shot setup. We convert the 2D gestures to 3D poses and produce 3D animations. We conduct objective and subjective evaluations to validate our approach and compare it with a baseline.
Multimodal generation of upper-facial and head gestures with a Transformer Network using speech and text
Oct 09, 2021

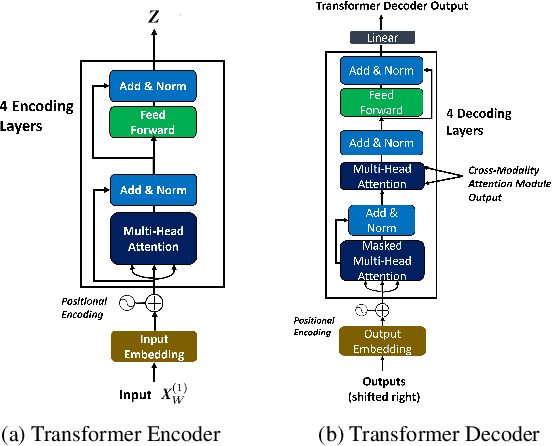
We propose a semantically-aware speech driven method to generate expressive and natural upper-facial and head motion for Embodied Conversational Agents (ECA). In this work, we tackle two key challenges: produce natural and continuous head motion and upper-facial gestures. We propose a model that generates gestures based on multimodal input features: the first modality is text, and the second one is speech prosody. Our model makes use of Transformers and Convolutions to map the multimodal features that correspond to an utterance to continuous eyebrows and head gestures. We conduct subjective and objective evaluations to validate our approach.